

Qu’est ce que c’est Real-Time data Processing ?
Le Real-Time Data Processing – traitement de données temps réel – consiste à exécuter des processus sur des données sur une période très courte et dont le résultat est délivré dans des délais tout aussi courts. Ainsi, ces traitements se terminent à peine les données absorbées.
C’est donc une intégration continue de données, qui engendre un flux tout aussi ininterrompu de données résultantes en sortie.
Il existe des exemples bien connus de système Real-Time Data Processing tels que les distributeurs automatiques des banques (ATM), le système de contrôle de trafic ou encore les systèmes qui soutiennent les réseaux mobiles pour l’acheminement des appels. Prenons par exemple le système de contrôle de trafic aérien, qui affiche en permanence la localisation des avions ; il a un flux de données continu ; il faut avoir un système qui permet d’en extraire leurs positions, pour les transmettre à un autre processus qui par exemple projette « instantanément » ces avions sur une carte selon les coordonnées où ils ont été situés à cet instant précis.
A l’opposé, les traitements de données de type Batch, travaillent sur des données du « passé » (du mois précédent, de la journée précédente, des 4 heures précédentes) ! Avec les traitements continus et temps réel, il s’agit bien d’agir sur des données en mouvement afin de fluidifier les processus de l’entreprise, et dégager un point vue très actuel (“Présent”) sur une activité !
Real-Time data Processing est souvent appelé “Stream Processing”.
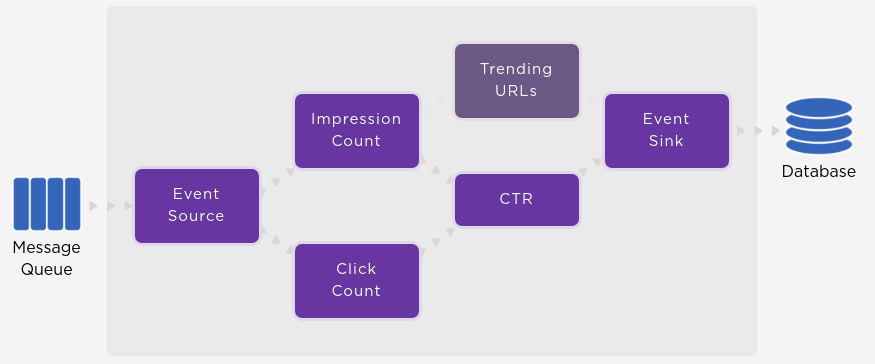
Pourquoi le Real-Time Data Processing ?
Avec l’intensification de l’activité économique, nombreuses sont les organisations qui souhaitent une obtention toujours plus rapide de l’information. Les quantités de données traitées dans un batch s’amenuisent et la fréquence, elle, devient de plus en plus élevée. Le nombre d’enregistrements traités tend vers une quantité proche de un : le stream processing émerge. Tel que déjà évoqué, avec le model Stream Processing, les événements sont traités dès qu’ils arrivent.
Ce modèle plus dynamique rend la conception des traitement plus complexes. Souvent le Stream Processing est imprévisible, avec des piques aléatoires d’arrivée de données, voire des rafales, le système doit être capable d’activer des mécanismes de « tampons » ou encore augmenter ou diminuer dynamiquement le nombre de ressources nécessaires à l’absorption de cette charge. Qui plus est, la complexité grandit avec une arrivée « désordonnée » de la donnée, qui peut même être perdue ou dupliquée.
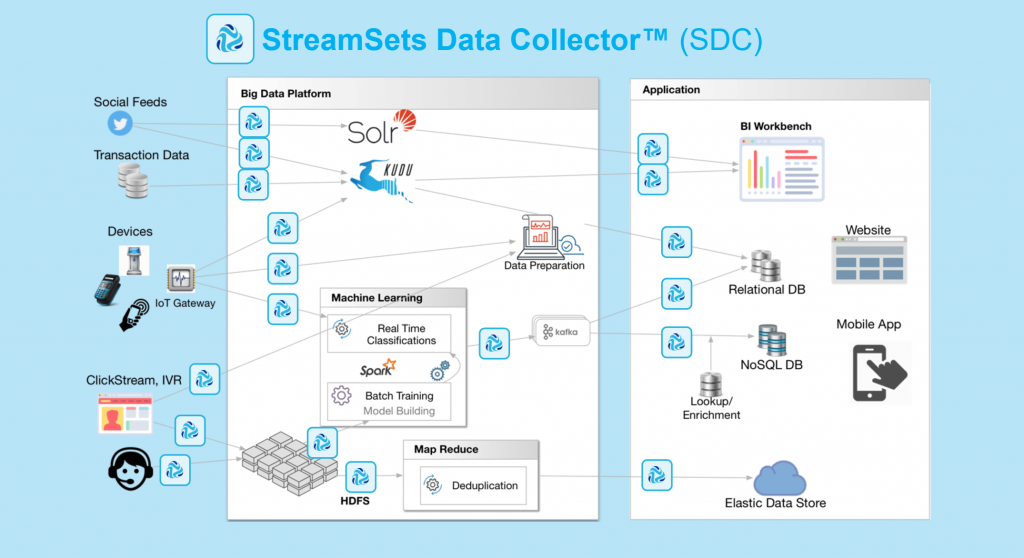
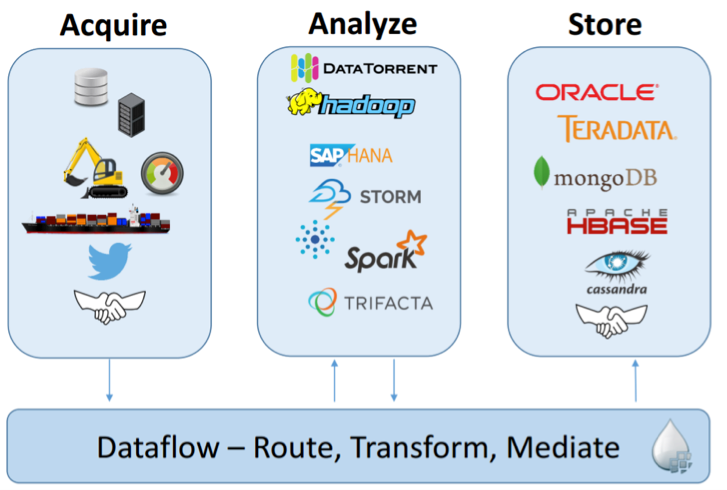
Stream Processing Frameworks
Avec Hadoop File System (HDFS) on est capable de stocker un très grand volume de données, supporté par une forte tolérance à la panne. Les technologies de traitements distribués, tel que MapReduce, apportent aux développeurs des solutions pour concevoir des processus s’exécutant sur un cluster de machines dont la donnée est par exemple stockée à même HDFS.
Apache Storm, Apache Spark, Apache Flink, Apache Apex, Apache Kafka Stream sont des exemples de frameworks de Stream Processing. Ils permettent aux développeurs de faire des applications pour réaliser des analyse en quasi temps réel (ou à faible latence). Nous citerons aussi Apache Beam qui abstrait les frameworks de streaming processing pour permettre une exécution sur le / les moteurs de son choix.
Dans une vision plus détaillée, les frameworks sont divers et couvrent des fonctionnalités différentes: distribution de code, exécution à même un cluster, configuration des sources et des destinations de la donnée, combinaison de processus (DAG), etc…
Les frameworks fournissent une grande flexibilité dans la conception des programmes, toutefois certains ingénieurs de la donnée cherchent parfois des outils de plus haut niveau qui masquent la complexité du code, pour fabriquer leurs pipelines de données et obtenir leurs traitements de Stream Processing. StreamSets Data Collector et Apache NiFi offrent une interface utilisateur dans le navigateur qui permettent de construire un pipeline graphiquement qui peut s’exécuter sur un cluster de machines avec une liste de connecteurs à des sources de données et des noeuds de traitements.
Voici un exemple de pipeline réalisé avec StreamSets Data Collector :
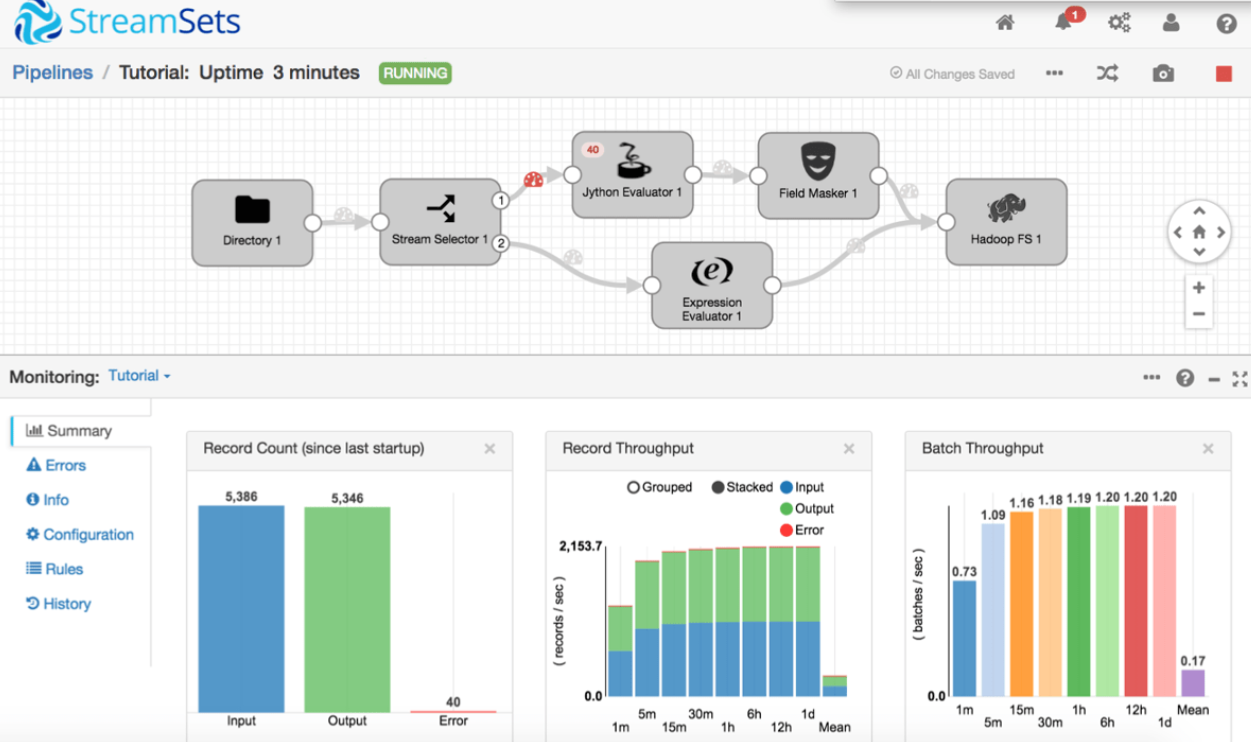
Ce pipeline récupère un fichier .csv depuis le disque local, réalise un traitement et sort un résultat vers HDFS.
Un point important pour ces deux outils est la personnalisation du traitement au-delà des composants fournis via des langages tels Java, Scala, Python, JavaScript ou autre.
Un autre grand avantage des ces solutions réside dans leur capacité à distribuer le processus sur un réseau de machines, et ainsi le passer à l’échelle selon des niveau de qualité requis.
StreamSets vs Nifi
Installation
Ici, nous procédons à une installation sur une seule machine sous GNU Linux (Virtualbox).
-
StreamSets
Télécharger StreamSets Data Collector sur https://streamsets.com/opensource/, et tappez
tar xvzf streamsets-datacollector-core-2.7.2.0.tgz
dans le Terminal pour décompresser le fichier sur CentOS.
Taper ensuite
streamsets-datacollector-2.7.2.0/bin/streamsets dc
dans le Terminal pour lancer streamsets-datacollector.
Ouvrir un navigateur et y saisir http://<system-ip>:18630/ quand <system-ip> est l’adresse IP de la machine où vous avez installé streamsets-datacollector.
Vous aurez la page de connexion de gestion de pipelines, vous pouvez vous connecter avec admin:admin.
Dedans, vous aurez tous les pipelines exemple :
-
Nifi
Nous réalisons une installation simple dans le cadre de cet article.
Allez sur https://fr.hortonworks.com/downloads/#dataflow et télécharger Hortonworks DataFlow (HDF®) 3.0 on Hortonworks Sandbox pour VirtualBox.
Ouvrez le fichier téléchargé avec VirtualBox et lancez ; ici vous avez lancé une machine CentOS où est déjà installé Apache Nifi.
Allez sur Terminal de la machine et faire:
echo '{Host-Name} sandbox-hdf.hortonworks.com' | sudo tee -a /private/etc/hosts
pour faire correspondre l’entrée DNS sandbox-hdf.hortonworks.com avec l’adresse ip locale de votre machine. Ici remplacez {Host-Name} par 127.0.0.1 (parce qu’on est sur une seule machine).
Ouvrez votre navigateur et naviguer sur http://{host-ip}:19090/nifi/, ici {host-ip} est l’adresse IP de la machine SandBox.
Vous aurez l’interface utilisateur d’Apache Nifi qui permet de construire le flux de données comme vous le voulez :
Voici notre comparatif entre Nifi et StreamSets Data Collector :
| StreamSets | Nifi | |
| Interface Utilisateur | Web (plus intuitive) | Web |
| Prévisualisation de l’exécution | Mode Preview | Pas de Mode Preview |
| Arrêt | Arrêt toute pipeline | Arrêt d’un seul processor |
| ingestion | Record Based | File oriented |
| Licence | Open source | Open source |
| Prise en main | Facil pour commencer | Plus mature, plus de contributors |
| Exécution en mode cluster | s’exécute au dessus de SPARK avec un cluster YARN ou Apache Mesos | mode cluster en standard sans de dépendance à d’autres système |
| supporter back-pressure et pressure-release | non fourni en standard | fourni en standard |
Record Based vs File Oriented
StreamSets Data Collector est conçu pour traiter des données organisées sous forme d’enregistrements. Ainsi dès la captation et la lecture des données, au début du pipeline, elles sont traitées dans un format commun. Globalement la construction des flux (donc la productivité des développeurs) est facilité ! Petit bémol la performance en prend un léger coup pour convertir dans ce format. Dans le même temps les formats de données peuvent être centralisés dans un référentiel tel que Confluent Schema Registry.
A contrario Apache Nifi est « data agnostique » ! Il ne se préoccupe pas du type de données qu’il doit traiter. Apache Nifi sait manipuler tant du JSON, que du XML, que du CSV, de l’Avro, ou encore des images, des video, et de nombreux autres formats. Toutefois, pour simplifier l’accès aux données structurée, Apache Nifi a introduit depuis sa version 1.2 des processeurs « Record Based » qui doivent être associés à un schéma pour pouvoir procéder à leur action.
Arrêt toute pipeline vs Arrêt un seul processor
Avec Apache Nifi, il sera possible d’agir sur un composant, où le traitement est arrêté ! Les autres processeur continue alors leurs actions ! Avec StreamSets Data Collector, on doit arrêter tout le flux pour modifier un processor.
Mode Cluster
StreamSets Data Collector fonctionne avec SPARK au dessus de YARN ou Apache Mesos ; ce qui permet de mutualiser un cluster existe déjà.. Ce qui signifie aussi qu’il faut un cluster YARN ou Mesos pour le mode cluster de StreamSets Data Collector.
Apache Nifi possède une architecture propre pour s’exécuter en mode cluster.
Cet article n’avait d’autre but que de faire découvrir succinctement le traitement de données temps réel avec des plateformes propose un environment de construction des flux grâces à des interfaces graphiques telles que nous les manipulons chez Synaltic ! Nous n’ignorons pas les solutions comme Apache Beam, Apache Storm, Apache Spark, Apache Flink, Apache Apex… Ou les dernier né Apache Heron, Apache Kafka Stream… Dans nos prochains articles nous détaillerons comment créer un flux avec Apache Nifi, avec StreamSets Data Collector, ou encore Streaming Analytic Manager d’Hortonworks.
Chunan Xia & Charly Clairmont



Sections commentaires non disponible.