Ce site stocke des cookies sur votre ordinateur. Nous les utilisons afin de personnaliser votre expérience de navigation ainsi que pour des analyses d'audience.
Nous avons récemment fait l’acquisition d’une station météorologique Davis Vantage Vue. Cette station comporte un ensemble de capteurs, qui communiquent leurs données à une console par radio 868MHz. Elle fournit plus d’une vingtaine de données différentes, ce qui est plus que ce que propose la majorité des grands sites météorologiques. Cette constatation nous a fait nous questionner sur la précision et la pertinence des informations météorologiques que l’on nous transmet au quotidien. Ainsi, nous avons décidé, en coopération avec La Fonderie, de proposer nos propres relevés de données, et ce en différents points de la région parisienne.
Pour ce faire, nous avons décidé de récupérer toutes les données fournies par la station météo à l’aide d’un Rapsberry Pi, utilisant Raspbian, système d’exploitation basé sur Debian et optimisé pour le Raspberry (les données de la station étant chiffrées, il était nécessaire d’utiliser cette OS plutôt qu’une OS du type tinyOS). L’objectif était ensuite de publier ces données sur un serveur, puis gérer le flux afin de pouvoir les afficher :
Une fois le Raspberry relié à la station météo, les données météorologiques sont récupérées et stockées dans un fichier csv à l’aide d’une librairie Python, Wospi. Ce fichier est ensuite lu et chaque nouvelle ligne est envoyée dans un format json en tant que message vers un broker MQTT Mosquitto, sous un topic spécifique pour chaque station. Dans l’architecture que nous avons choisi Mosquitto s’exécute au sein d’un container Docker chez notre fournisseur de cloud. Le service MQTT peut être accédé par l’ensemble des nano-machines couplés aux stations météo.
Nous créons ensuite un autre container Docker avec InfluxDB, une base de données. Sur ce container un programme Python, se connecte en tant que client à notre broker MQTT, s’abonne au topic de notre station, afin de recevoir chacun des messages. Ils sont traités pour chaque type de donnée (température, pression…) enregistré au sein d’InfluxDB.
Nous avons choisi InfluxDB car il permet nativement de gérer des séries temporelles : nos données seront donc conservées et historisées. En effet, ce n’est pas le but premier de Mosquitto, qui bien que sachant stocker les messages n’a pas vocation à les conserver sur du long terme.
Par ailleurs, InfluxDB s’accompagne souvent d’une interface graphique : Grafana. Celle-ci nous a permis de créer des graphes en fonction du temps, et de les afficher comme nous l’entendions.
Ainsi, il est aussi possible de tracer plusieurs courbes sur un même graphe, ce qui permet de mettre en valeur le lien entre les données. Par exemple, la figure précédente illustre le lien entre humidité et température : plus la température augmente, plus l’humidité baisse. Grafana nous permet en outre de rajouter des valeurs supplémentaires ou des types de données au flux temporel, ainsi notre exploitation n’est pas limitée aux seules informations fournies par la station. Nous envisageons ainsi d’ajouter des données de pollution, ainsi que nos relevés de consommation en eau, en électricité et en gaz. L’interface nous permettra alors de mettre en évidence, de manière très visible, le lien entre conditions climatiques et consommations domestiques. Ces informations pourraient alors être exploitées avec un système IFTTT qui permettrait, par exemple, d’allumer le chauffage lorsque la température fournie par la station est trop faible, ou d’émettre un message d’alerte lorsque le niveau de pollution est trop important.
De nombreux outils de catalogage des données sont apparus grâce à l’accumulation massive de données désorganisées. Le but de ces outils va être de maximiser les possibilités de ré-usage des données afin de mieux les valoriser. Pour ce faire, il faut « connaître la donnée » pour pouvoir correctement la ranger et la retrouver, cette connaissance passe par l’usage d’un ensemble de méta-données décrivant la donnée. Cependant, une intervention humaine est nécessaire pour assurer un catalogage correct. Pour résoudre ce problème, il faut automatiser au maximum l’extraction des méta-informations des données.
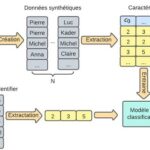
Parmi ces informations, le type sémantique des données est particulièrement intéressant, car largement utiliser en data intégration. La plupart des outils de BI peuvent découvrir automatiquement quelques types sémantiques. Cette détection se fait classiquement à l’aide d’expressions régulières et de dictionnaires. Ces méthodes sont efficaces quand les données présentent des schémas réguliers et sont peu bruitées. Dans le cas contraire, la reconnaissance est difficile. Cette problématique a fait naître ces dernières années un nouveau courant de méthodes basées sur l’apprentissage artificiel.
Ces techniques vont essayer d’apprendre à partir de colonnes d’exemples à reconnaître les différents types sémantiques. Néanmoins, ces nouvelles méthodes ont besoin d’un large volume de données réel, ce qui limite l’usage à des types sémantiques pour lesquels beaucoup de données sont disponibles. Ainsi, une partie des travaux de R&D chez Synaltic visent à développer des méthodes basées sur l’apprentissage automatique pour identifier une plus grande variété de types sémantiques tout en minimisant le besoin de données réelles. C’est dans ce cadre que l’article « Semantic Type Detection in Tabular Data via Machine Learning Using Semi-synthetic Data » a été écrit et présenté à la conférence SoCPaR2022.
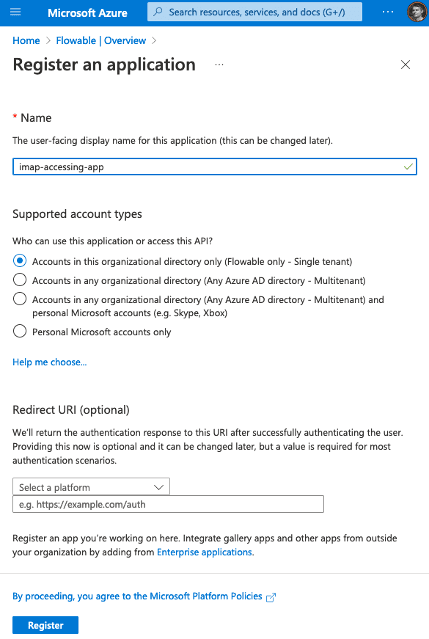
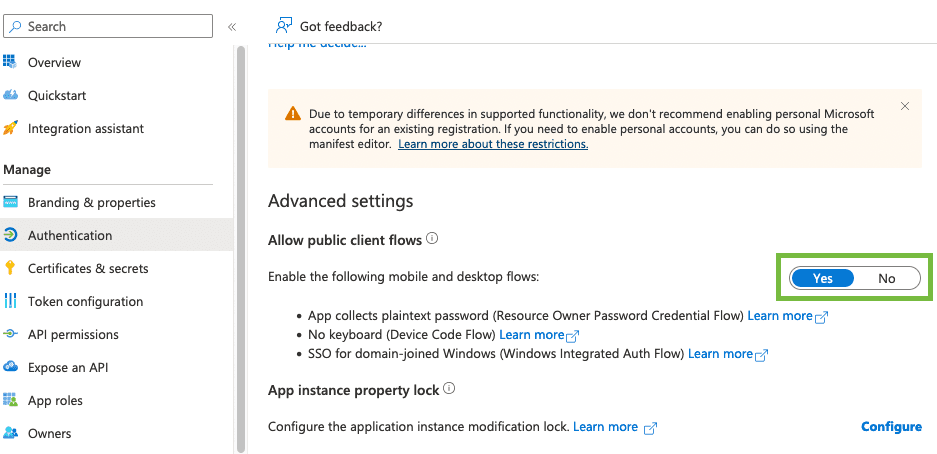
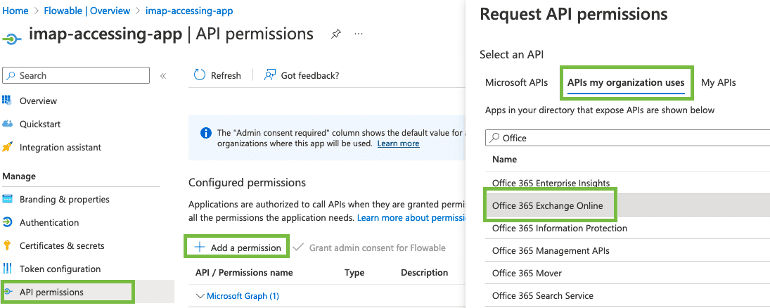
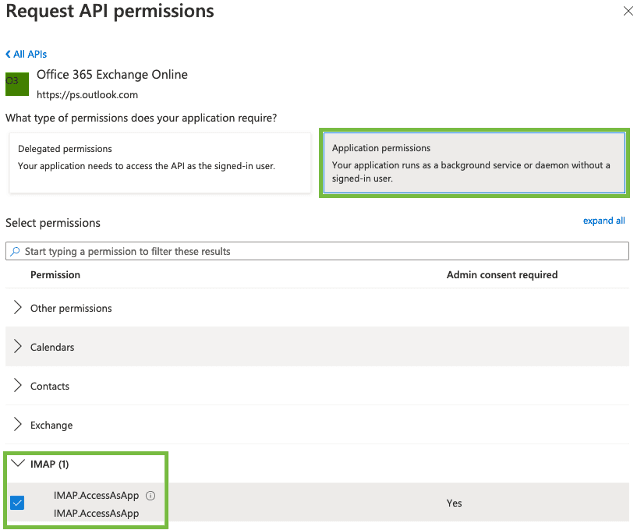
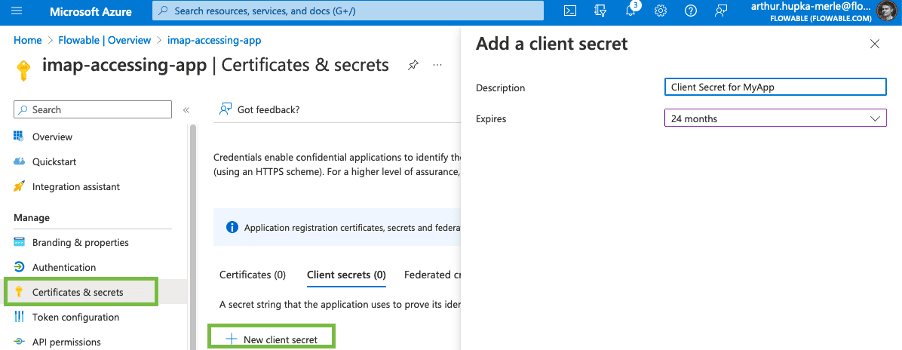
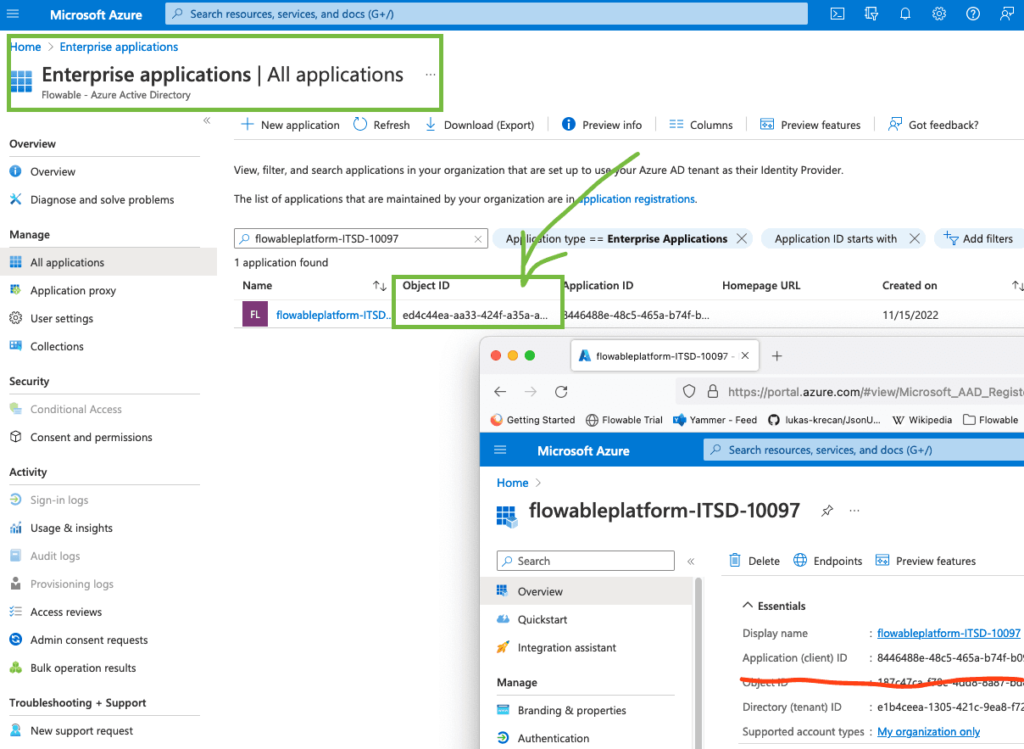
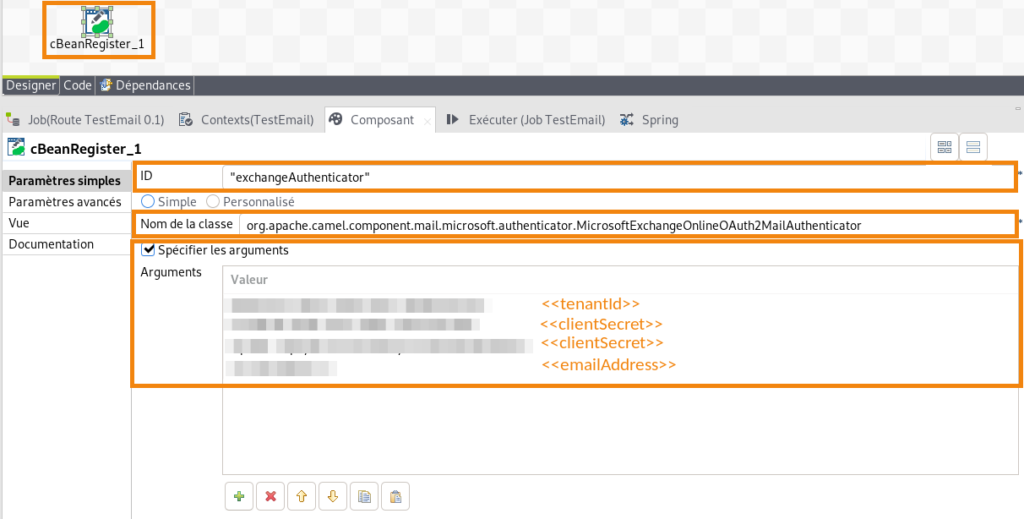
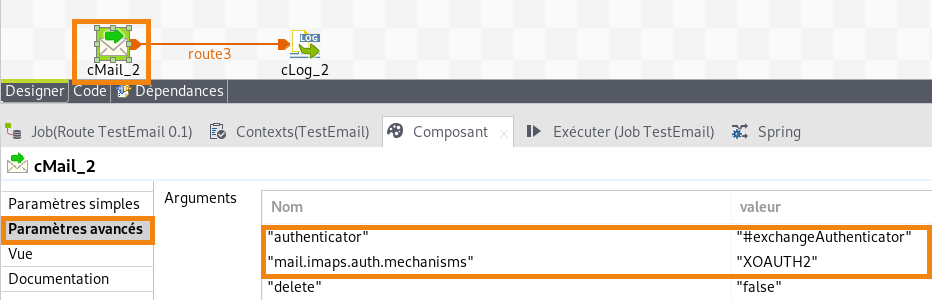
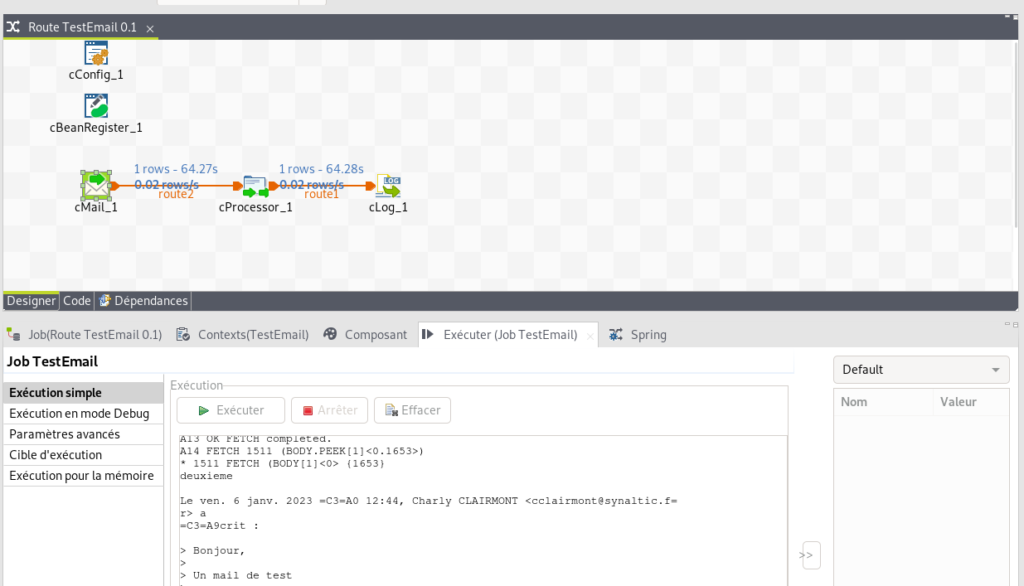
L’intégration de données trouve une certaine complexité dans la manipulation d’un grand nombre de sources de données, et d’API. Ici, nous avons cherché à simplifier l’appropriation de la configuration des API OAuth2 de Microsoft Azure pour Exchange Online.
Synaltic se tient à vos côtés pour vous aider dans la mise en œuvre de vos projets d’intégration de données avec Talend.








Sections commentaires non disponible.