
APACHE ICEBERG™
Apache Iceberg™ est un format de table open source pour les architectures modernes de données (Big Data, Data Lake, Data Lakehouse).
Apache Iceberg™ apporte la fiabilité et la simplicité des tables SQL tout en permettant à des moteurs tels que Spark, Trino, Dremio SQL Engine, Flink, Presto et Impala de travailler en toute sécurité, en même temps et avec les mêmes tables !

Pourquoi choisir Iceberg ?
Apache Iceberg™ est le format de table ouvert qui modernise nos architectures actuelles et les transforme en plateformes fiables, performantes et prêtes pour l’analytique et l’IA.
Iceberg est LE format universel de la donnée, adopté par tout l’ecosystème logiciel … il devient la fondation idéale pour les architectures Lakehouse modernes.
Format ouvert et interopérable
Iceberg repose sur des standards ouverts, garantissant une compatibilité native avec de nombreux moteurs. Vous conservez la liberté de choisir vos outils, sans verrouillage éditeur !
Performance et fiabilité à grande échelle
Grâce à sa gestion avancée des métadonnées, Iceberg optimise les lectures, réduit les scans inutiles et améliore les performances des requêtes. Les opérations critiques deviennent fiables et transactionnelles.
Évolution des schémas sans interruption
Iceberg permet de faire évoluer vos schémas sans casser les pipelines ni impacter les consommateurs. Les équipes gagnent en agilité et en autonomie, même dans des environnements complexes.
Time‑travel et versioning natifs
Iceberg conserve l’historique des tables, permettant d’interroger les données à un instant T, de restaurer un état précédent et d’auditer facilement les évolutions. Un atout majeur pour la gouvernance, la conformité et le debugging.
Les fondamentaux
Apache Iceberg est un format de table open source pour les architectures modernes de données (Big Data, Data Lake, Data Lakehouse).
Apache iceberg est sous licence Apache 2.0 et vise à répondre aux limitations des formats traditionnels comme Apache Parquet, Apache Avro ou encore Apache Hive. Il fournit une solution puissante et évolutive pour gérer et analyser des ensembles de données à grande échelle dans des systèmes distribués.
Le format de table Iceberg a des capacités et des fonctionnalités similaires à celles des tables SQL dans les bases de données traditionnelles. Iceberg fonctionne de manière entièrement ouverte et accessible.
Ainsi, Apache Iceberg est une spécification de format de table et un ensemble d’API et de bibliothèques permettant aux moteurs d’interagir avec les tables suivant cette spécification.
Netflix, l’entreprise américaine créée en 1997 se concentrait initialement sur la location et l’achat de DVD livrés à domicile. Cependant, en 2007, Netflix a lancé son service de vidéo à la demande par abonnement et depuis lors, elle s’est développée pour distribuer un grand nombre de films et de séries. Avec une grande quantité de données générées par les activités des utilisateurs, les recommandations de contenu et les analyses, Netflix commençait à peiner à gérer ses données.
Le développement d’Iceberg a été lancé par Ryan Blue et Dan Weeks en 2017. Le projet a été donné à la fondation Apache en novembre 2018. En mai 2020, le projet Iceberg est devenu un “top-level project” Apache.
Depuis, Apache iceberg a été adopté par d’autres entreprises telles que Airbnb, Apple, Expedia, LinkedIn, Adobe, Le Point, La Poste, Michelin, Bic … Courant 2024, la spécification Iceberg est massivement adoptée par les éditeurs logiciels eux-mêmes, notamment Snowflake et Databricks.
L’architecture de la table Iceberg se compose de trois couches :
- Le catalogue Iceberg : Le catalogue est l’endroit où les services vont pour trouver l’emplacement du pointeur de métadonnées actuel, ce qui permet d’identifier où lire ou écrire des données pour une table donnée. C’est ici qu’il existe des références ou des pointeurs pour chaque table qui identifient le fichier de métadonnées actuel de chaque table.
- La couche de métadonnées : Cette couche se compose de trois composants : fichier de métadonnées, liste de manifeste et fichier manifeste. Le fichier de métadonnées inclut des informations sur le schéma d’une table, les informations de partition, les instantanés et l’instantané actuel. La liste manifeste contient une liste de fichiers manifeste, ainsi que des informations sur les fichiers manifestes qui composent un instantané. Les fichiers manifestes suivent les fichiers de données en plus d’autres détails et statistiques sur chaque fichier.
- La couche de données : Chaque fichier manifeste suit un sous-ensemble de fichiers de données, qui contiennent des détails sur l’appartenance à la partition, le nombre d’enregistrements et les limites inférieure et supérieure des colonnes.
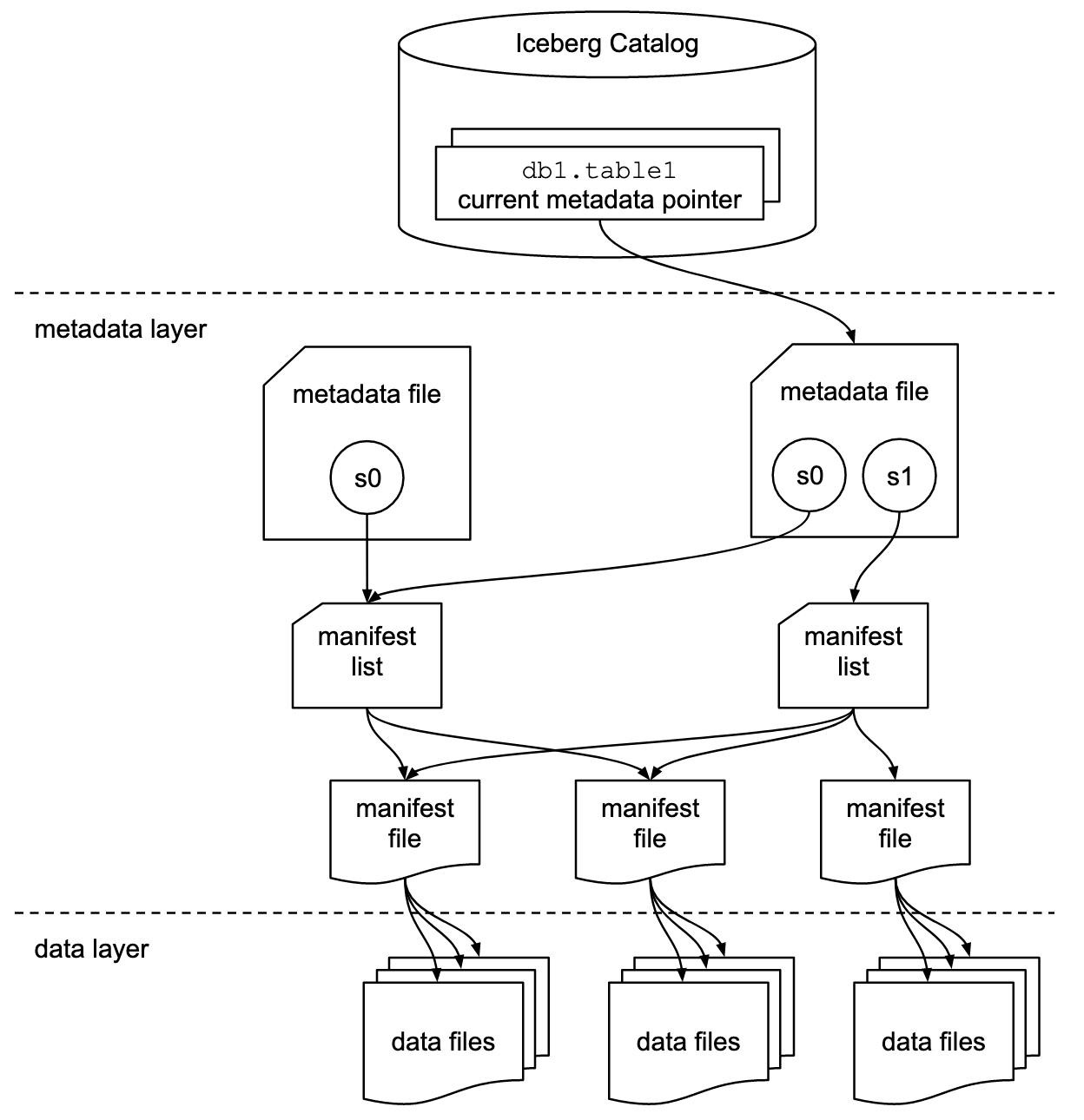
Source de l’illustration : https://iceberg.apache.org/spec/#overview
Apache Iceberg permet une évolution efficace des schémas, garantit la cohérence des données, prend en charge l’analyse historique (time travel), optimise les performances des requêtes. Iceberg offre une compatibilité avec les frameworks de traitement de données populaires, notamment :
- Apache Spark, Apache Flink, Presto, Impala, Dremio, Daft, Clickhouse, Starrocks, Amazon Redshift, Amazon Athena, Amazon EMR, AWS Glue, Snowflake, Databricks…
Ces qualités font d’Apache Iceberg un outil essentiel pour les organisations confrontées au traitement et à l’analyse de données à grande échelle dans le paysage du Big Data, du Data Lake et du Data Lakehouse.
Voici quelques grandes caractéristiques d’Apache Iceberg :
- Exactitude : Apache Iceberg gère les opérations d’écritures avec l’isolement nécessaires, et les mécanismes utiles qui garantissent les transactions ACID, comme dans une base de données traditionnelle. Même en cas d’échec d’écriture vos données restent intègres.
- Evolutivité : Apache Iceberg offre une flexibilisation dans la définition des structures de données telle que MongoDB ou Elasticsearch tout en s’appuyant sur la rigueur des modélisation des plus grands data warehouses. Apache Iceberg inscrit ces données dans un stockage distribué. Ici encore Apache Iceberg bénéficie de toute les évolutions qu’il y a eues au sein des architecture Big Data et celles des data lakes.
- Performances: En informatique, il est très coûteux d’ouvrir un fichier pour le lire. Bien sûr, ouvrir un fichier ne pose pas de problème. Toutefois, lorsque l’on passe à l’échelle et que le nombre de fichiers explose, il convient de faire en sorte de réduire ce nombre. Ici encore Apache Iceberg apporte des réponses face aux solutions déjà existantes…
- Ouverture : Bien sûr que Apache Iceberg est open source ! Ici, ce qu’il faut en comprendre c’est surtout que la mutualisation en facilite l’adoption en particulier parce que Apache Iceberg s’interface avec l’ensemble des cadres de développement, des solutions d’analyses… Grâce à Apache Iceberg pas d’enfermement par un fournisseur ! Dit autrement : “Pas de Vendor Locking”.
- Temps réel : compte-tenu de la performance d’une part, et de l’évolutivité d’autre part, Apache Iceberg s’inscrit parfaitement dans l’architecture quasi temps réel.
Les ressources pour prendre en main Apache Iceberg™
Vidéo
« De la Business Intelligence aux décisions en streaming » est un webinaire de 35 minutes qui illustre l’évolution des architectures de données et qui met en avant Iceberg et Kafka.
Livre - Ebook
« INTRODUCTION À APACHE ICEBERGTM PAR CHARLY CLAIRMONT » c’est plus de 150 pages pour découvrir les principales fonctionnalités d’Apache iceberg et les meilleures best-practices !
Etes vous prêts ?
Ce document liste les questions essentielles pour évaluer la maturité de votre entreprise face à l’adoption d’un Data Lakehouse. Ne lisez pas ce document seul/e mais réunissez vos équipes pour échanger sur le sujet !
Site Officiel
https://iceberg.apache.org publie une documentation complète, un « quick-start« , des articles de blog et bien d’autres ressources ! Le contenu est en anglais uniquement.
Communauté
La communauté Apache Iceberg est animée principalement en anglais. On y trouve un espace d’échange Slack, des mailing-lists et la liste des événements.
AWS Documentation
Apache Iceberg est supporté par les services d’AWS tels qu’Amazon Redshift, Amazon Athena, Amazon EMR et AWS Glue … votre data lakehouse sur S3 est à portée de main ! La documentation est ici disponible en français.
Un peu d’histoire
Créé chez Netflix en 2018, Apache Iceberg™ est rendu open source la même année et rejoint l’incubateur Apache en 2020, avant de devenir un Top‑Level Project en 2022 sous la gouvernance de la fondation Apache Software Foundation. Dès son origine, Apache Iceberg™ n’est pas pensé comme un simple format de table, mais comme un standard structurant pour organiser, versionner et gouverner la donnée à grande échelle.
Lorsque Charly découvre Apache Iceberg™, il a immédiatement perçu la solidité de son approche technique et la maturité de son modèle. Pourtant, une interrogation demeure : aussi prometteur soit-il, comment ce format allait-il arriver à s’imposer comme un standard ?
En 2024 puis en 2025, les géants du cloud, AWS, Google Cloud, Microsoft, ont intégré Apache Iceberg™. Les moteurs analytiques comme Snowflake, BigQuery, Synapse, Starburst, Databricks, ClickHouse, MotherDuck, Redshift, Athena, Trino, Presto, DuckDB et bien d’autres ont suivi… Même les acteurs orientés analytics comme Qlik, Tableau, PowerBI ou encore Looker ont intégré Apache Iceberg™ dans leurs pipelines et leurs connecteurs !
Tous les acteurs ont basculés naturellement vers Apache Iceberg™, sans contrainte ni injonction, nous avons compris que la bataille était gagnée !
Nos derniers articles de Blog autour d’Apache Iceberg™

What’s New in Apache Iceberg 1.11.0
Traduction libre du billet “What’s New in Apache Iceberg 1.11.0” publié par Alex Merced de Dremio en mai 2026. Un tournant architectural pour... Lire la suite →
28/05/2026

Le catalogue Iceberg est le GPS du Lakehouse !
Le Lakehouse moderne repose sur Apache Iceberg™, mais c’est le catalogue qui en détermine vraiment la puissance, l’ouverture… et le... Lire la suite →
27/05/2026
Un lakehouse en une conversation avec Claude
43 millions de lignes SIRENE : initialisation d'un lakehouse "associations" en une conversation avec Claude Et si construire un data... Lire la suite →
13/05/2026
Piloter Dremio en langage naturel
dremio-cli + Claude Code : piloter Dremio en langage naturel Dremio Cloud embarque désormais un CLI pensé pour être orchestré... Lire la suite →
13/05/2026

Maillage de données avec Dremio #5
Passer à l'échelle Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent,... Lire la suite →
13/04/2026

Maillage de données avec Dremio #4
Gouvernance et catalogue Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent,... Lire la suite →
07/04/2026

Dremio, une solution conçue nativement pour Apache IcebergTM !
C’est en nous intéressant dès 2018 à l’Open Data Lakehouse Dremio que nous avons petit à petit découvert tout ce qu’allait nous apporter Apache Iceberg. 6 ans plus tard, nous continuons de découvrir un potentiel que nous n’avions alors qu’entre aperçu !
Dremio est le premier Lakehouse a avoir mis à l’honneur Iceberg en présentant une solution packagée comprenant notamment les projets Apache IcebergTM, Apache Arrow et Apache Nessie ! Dremio permet ainsi de déployer une solution complète et ouverte de Data Lakehouse.
Pour recevoir le livre Introduction à Apache IcebergTM par Charly Clairmont, remplissez le formulaire ci-dessous :
*tous les champs sont obligatoires
