
Qu’est-ce qu’un Data Lakehouse ?
Des structures et des fonctions de gestion des données similaires à celles d’un data warehouse directement implémentées dans un stockage à faible coût de type data lake.
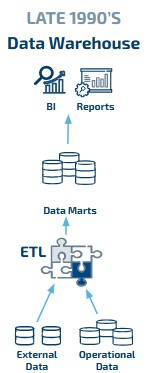
A l’origine : l’entrepôt de données
Pour stocker et gérer les données, nous avons traditionnellement mis en place des entrepôts de données (ou data warehouse). Le principe de collecter la donnée, de l’enrichir par association, nettoyage ou calcul, et d’en assurer la cohérence. Pour supporter ces fonctionnalités, plusieurs solutions ETL (extract, transform, load) ont vues le jour … et dominent aujourd’hui le marché.
Les données sont ensuite interrogées par les utilisateurs métier qui utilisent les données préparées dans les outils BI pour les rapports et les projections.
Ces plateformes sont ainsi conçues pour supporter la prise de décision et effectuer des analyses sur de grandes quantités de données structurées.
Que deviennent les entrepôts de données aujourd’hui ?
Ces dernières années, les types, les sources ainsi que le volume de données ont explosés ! Maintenir un entrepôt est devenu complexe, cher et lent. Les limites de ces plateformes ne se présentent pas que du coté IT, les utilisateurs métier sont de plus en plus touchés.
L’accès aux données devient parfois une peine, la vitesse n’est pas au rendez-vous et les évolutions ne sont pas toujours délivrées dans les temps. De plus les projets de data science et de machine learning réclament une connexion à la source des données, ce qu’un entrepôt de donnée n’a pas prévu. Si la technologie est remise en question, la méthodologie du data warehousing reste elle bien confirmée.
Les bonnes pratiques de gouvernance sont désormais reconnues et ne demandent qu’à être complétées, par exemple avec les Data Contracts.
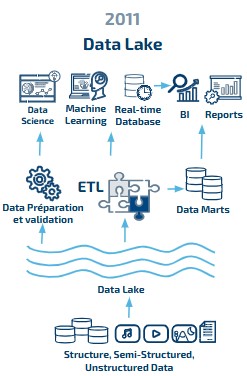
Que nous apportent vraiment les lacs de données ?
Dès les années 2000, les lacs de données ont gagné en popularité en réponse aux limites des entrepôts de données traditionnels. Hadoop, avec son système de fichiers distribués (HDFS), a permis aux entreprises de stocker et de traiter de grands volumes de données de manière évolutive.
Des plateformes comme Databricks et Dremio ont réalisées la convergence des lacs de données et des entrepôts de données. Databricks, Netflix et Uber ont introduit Delta Lake, Apache Iceberg et Apache Hudi, des formats de table qui ont introduit les transactions ACID dans les lacs de données.
Depuis 2011, les lacs de données sont considérées comme des architectures peu onéreuses utilisées pour stocker les grandes quantités de données non structurées et semi-structurées qu’ils collectent et conservent dans des formats de fichier génériques et ouverts. Les données sont ajoutées au lac de données telles quelles, autrement dit sans association, calcul ou reformatage des nouvelles données. Ces fonctionnalités, bien présentes dans les entrepôts de données, reposent ici uniquement sur la cohérence des sources des données. Difficile donc de répondre aux exigences de qualité des données et de gouvernance !
Si les lacs de données ont séduit ceux qui cherchaient à réduire leur coût, il leur manque toutefois des fonctionnalités des data warehouses, comme la prise en charge des transactions et l’application de règles de qualité des données.
Le Data Lakehouse, une combinaison du meilleur des deux mondes !
Un Data Warehouse facilite la prise de décision et permet la gouvernance de données. Cependant des problèmes de volumétries, de vitesses, de coûts et d’accès aux données apparaissent. Un Data Lake résout ces problèmes cependant nous perdons la gouvernance des données.
Un Data Lakehouse est la solution ! Des structures et des fonctions de gestion des données similaires à celles d’un entrepôt de données sont directement implémentées dans un stockage à faible coût de type lac de données.
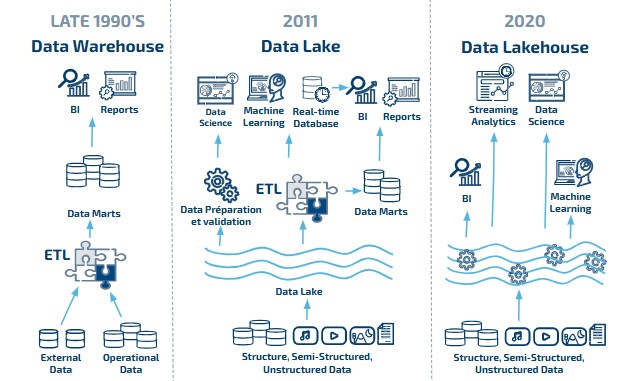
Chez Synaltic, nous considérons l’Open Data Lakehouse comme une évolution naturelle, voire un certain aboutissement. Il y a déjà 20 ans, nous accompagnions nos clients dans la mise en place et l’évolution de leurs data warehouses. Nous parlions de qualité et de gouvernance… puis sont arrivés les projets Big Data et le Cloud.
Aujourd’hui, les enjeux de gouvernance, de souveraineté et de coûts nous incitent plus que jamais à recommander l’Open Data Lakehouse : une plateforme de données fondée sur des solutions Open Source et des formats ouverts.
DECOUVrEZ NOTRe OfFRE SUR L’OPEN DATA LAKEHOUSE
LES SOLUTIONS QUE NOUS METTONS EN OEUVRE

NOTRE LIVRE BLANC

Tout savoir sur le Data Lakehouse !
Aujourd’hui, les entreprises ont plus de données que jamais… mais elles peinent à en tirer de la valeur.
Le Data Lakehouse change la donne : une architecture unique, ouverte et souveraine, qui réunit la flexibilité du Data Lake et la performance du Data Warehouse, sans duplication ni verrouillage.
En quelques semaines, vous passez d’un système fragmenté à une plateforme data unifiée, performante et prête pour l’IA.
NOS DERNIERS ARTICLES

OKDP : pourquoi une plateforme data intégrée ?
Open Kubernetes Data Platform — une réponse aux coûts cachés de l’assemblage. Vue d'ensemble : le modèle OKDP Lecture du... Lire la suite →
01/07/2026

Le catalogue Iceberg est le GPS du Lakehouse !
Le Lakehouse moderne repose sur Apache Iceberg™, mais c’est le catalogue qui en détermine vraiment la puissance, l’ouverture… et le... Lire la suite →
27/05/2026
Un lakehouse en une conversation avec Claude
43 millions de lignes SIRENE : initialisation d'un lakehouse "associations" en une conversation avec Claude Et si construire un data... Lire la suite →
13/05/2026

Maillage de données avec Dremio #5
Passer à l'échelle Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent,... Lire la suite →
13/04/2026

Maillage de données avec Dremio #4
Gouvernance et catalogue Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent,... Lire la suite →
07/04/2026

Maillage de données avec Dremio #3
L'architecture lakehouse Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous... Lire la suite →
31/03/2026

Maillage de données avec Dremio #2
Commencer petit Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous... Lire la suite →
27/03/2026

Maillage de données avec Dremio #1
Pourquoi 2026 change la donne ! « Le Data Mesh ? Oui, on en a parlé, et puis on est... Lire la suite →
25/03/2026

Déployer une stack lakehouse sur Kubernetes
Nous avons exploré le paradoxe français, l'architecture révolutionnaire, et le ROI convaincant. Passons maintenant à la pratique : comment déployer... Lire la suite →
25/11/2025
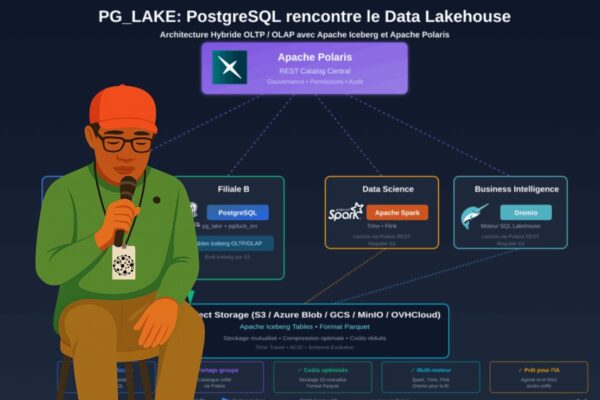
PG_LAKE : PostgreSQL + Data Lakehouse
Qu'est-ce que PG_LAKE ? pg_lake est un ensemble d'extensions PostgreSQL open-source (Apache 2.0) qui transforme votre base de données PostgreSQL... Lire la suite →
10/11/2025

Piloter Apache Iceberg™ en local grâce à DuckDB
DuckDB Lorsque DuckDB est apparu, il a créé une véritable onde de choc. Tout le monde en a parlé. Tout... Lire la suite →
29/09/2025

Apache Iceberg™ 1.10 : première étape de la Spécification V3
1. Introduction : Apache Iceberg 1.10, L'ère de la Spécification V3 Apache Iceberg s’impose comme une pierre angulaire des architectures... Lire la suite →
15/09/2025

Rendez-vous au Subsurface World Tour 2025 !
Chaque jour, vos données vous parlent ... les entendez-vous ? Elles sont là, partout : dans vos processus, vos applications,... Lire la suite →
12/08/2025

DataOps : Base de données agile avec Bytebase
Beaucoup de livres traitent des bases de données. Lorsque vous travaillez avec les bases de données il est important de... Lire la suite →
29/07/2025

Moderniser Hadoop, Hive avec Apache Iceberg™
Votre écosystème Hadoop a bien servi, mais vous sentez qu'il atteint ses limites ? Chez Synaltic nous avons beaucoup promu... Lire la suite →
15/07/2025

Etes vous prêts pour le Data Lakehouse ?
Pour vous aidez à définir si votre entreprise est suffisamment mature pour adopter la démarche d'un Data Lakehouse, nous vous... Lire la suite →
25/06/2025

Qlik Open Lakehouse : une plongée en profondeur
Le 12 mai 2025, en direct de Orlando, Qlik a profité du Tech Field Day pour dévoiler sa vision du... Lire la suite →
20/05/2025

Iceberg Summit 2025 : Apache Iceberg un socle commun pour la données
1. Introduction : Apache Iceberg à l'Avant-Garde des Architectures de Données Modernes Apache Iceberg s'est rapidement imposé comme un format... Lire la suite →
02/05/2025

Comprendre Data Lakehouse, Iceberg et Dremio
Avec la montée en puissance des technologies de gestion des données, des concepts comme Apache Iceberg, le Data Lakehouse et... Lire la suite →
20/01/2025

Iceberg : vous pouvez décider en temps réel !
ou comment le format de données Apache Iceberg transforme l’intégration et l’analyse de données. Etes-vous aujourd’hui en mesure de... Lire la suite →
15/05/2024

Data Lakehouse : Data Warehouse et bien plus encore !
Merci à Dipankar Mazumdar, Jason Hughes, JB Onofré pour mettre en relief ce qu’est un data lakehouse. The Data Lakehouse:... Lire la suite →
14/11/2023

Open Data Lakehouse, Simplifier, Gérer, Maîtriser ses données
Open Data Lakehouse, Simplifier, Gérer, Maîtriser ses données, un article rédigé par Charly Clairmont Directeur Général chez Synaltic. (suite…)
06/11/2023

Formez-vous à l’Open Data Lakehouse Dremio en 3 jours à Vincennes le 27, 28 et 29 novembre 2023
Synaltic est partenaire du "Data Lake facile d’emploi et ouvert" Dremio depuis 2021. Dremio fournit un moteur de requête et... Lire la suite →
24/10/2023
Découvrez les avantages et caractéristiques du Data Lakehouse
Découvrez les avantages et caractéristiques du Data lakehouse : Notre entreprise spécialisée dans la gestion de données lakehouse vous permet... Lire la suite →
04/07/2023


Analyser vos données Amazon S3 avec Dremio Cloud
Dans cet article, nous explorons comment Dremio permet aux analystes et aux scientifiques des données d’analyser directement des données dans... Lire la suite →
06/12/2022

Data Mesh : 3 retours d’expérience en vidéo !
La fréquentation du salon Big Data Paris en septembre 2022 (12.000 participants en physique, 4.000 à distance) nous montre l’intérêt... Lire la suite →
17/10/2022

Dremio, une nouvelle page s’ouvre
Dremio, une nouvelle page s'ouvre ;un article rédigé par Charly Clairmont, CTO, Synaltic (suite…)
03/03/2022

Analyse ultra-rapide avec Tableau Online et Dremio
Analyse ultra-rapide avec Tableau Online et Dremio, traduit et adapté du site de l’éditeur. (suite…)
12/01/2021

Dremio carrefour de données dans le cloud
Dremio carrefour de données dans le cloud, en mode cloud hybride, un article de Charly Clairmont, CTO, Synaltic. (suite…)
21/07/2020

Décloisonner les décisions grâce à Dremio
Organisations et décisions : Décloisonner les décisions grâce à Dremio, un article de Charly Clairmont, Directeur Technique, Synaltic. (suite…)
06/05/2020

Conférence POSS 2019 : Gouvernance technique des données
Conférence POSS 2019 : Gouvernance technique des données, retour d’expérience RTE, Charly Clairmont, CTO chez Synaltic et Arnaud Renard, Responsable... Lire la suite →
20/12/2019

Depuis 2014 Dremio facilite l’accès à vos données !
[Mise à jour] cet article a plus de 5 ans, si il reste utile pour rappeler l'histoire de la solution... Lire la suite →
22/11/2018

VIDÉO : Euronext partage son expérience lors du Talend Connect 2018
Une fois encore, nous sommes allés assister à Talend Connect et cette année, notre plaisir était double (suite…)
19/11/2018
Apache Kafka m’a tuer ! Ou comment j’ai appris à mieux l’utiliser
Dans cet article, Charly Clairmont vous présente quelques subtilités d'Apache Kafka, outil open source de système de messagerie distribué, originellement... Lire la suite →
22/06/2018

Ne limitez plus votre BI, passez à une approche Data Lake !
J’aurais aussi bien pu appeler cet article "Pourquoi est-ce qu’il est temps de vous intéressez à Hadoop" car il me... Lire la suite →
16/03/2018

Le Data Lake, véritable atout pour l’entreprise data driven
« Le Data Lake est une réponse technologique au Big Data. Il permet de créer et de gérer dans un espace... Lire la suite →
11/04/2016

Big Data Hadoop, un déploiement de plus en plus simple
Je voulais intituler cet article "Big Data aussi simple que LAMP". J'ai vite trouvé que c'était réducteur. Depuis que Synaltic... Lire la suite →
14/09/2015