

Apache Hadoop® vous aide à traiter la donnée de bout en bout
Un framework open source utilisé pour le stockage et le traitement des données
Apache Hadoop® est un framework logiciel open source pour adresser le big data. Il offre un espace de stockage massif pour tout type de données, et une immense puissance de traitement. Optez pour Hadoop avec Synaltic.
Pourquoi choisir Apache Hadoop® ?
Hadoop a posé les fondations des architectures data actuelles : stockage distribué, séparation compute/storage, traitement parallèle, formats ouverts.
Les technologies évoluent, cependant Hadoop reste un standard de référence, parfaitement intégré dans les environnements modernes et toujours pertinent pour les workloads intensifs.
Un socle distribué éprouvé
Grâce à son architecture distribuée basée sur HDFS et YARN, Apache Hadoop® est reconnue comme l’une des plateformes les plus robustes pour stocker et traiter de très grands volumes de données.
Un écosystème riche et extensible
L’écosystème Hadoop (Hive, Spark, HBase, Oozie, Ranger, Knox…) permet de couvrir tous les besoins : stockage, calcul, gouvernance, sécurité, orchestration. Cette modularité en fait une plateforme adaptable à des contextes variés, du batch massif au temps réel.
Redynamisez votre plateforme !
Découvrez Apache Iceberg™, le format de table open-source qui transforme votre lac de données en un véritable Data Lakehouse : fiable, performant et agile.
Contrairement aux tables traditionnelles sur HDFS, qui ne sont qu’une collection de fichiers, Iceberg ajoute une couche de métadonnées intelligente qui donne des super-pouvoirs à votre Data Lake !

Un peu d’histoire
Apache Hadoop® avait tout juste franchi l’atlantique… Synaltic a très vite compris qu’il se passait quelque chose, nous avons vu en Hadoop une possibilité pour toute organisation de prétendre à une plateforme de données unifiée et convergente pour gérer toutes ses données de A à Z ! Et c’est bien ce qui est arrivé !
C’est une plateforme dédiée à la donnée, qui traite la donnée de bout en bout et qui exécute tout type de traitements en apportant une gouvernance unifiée des données et des traitements.
Synaltic considère Apache Hadoop® pour son écosystème complet tant pour les projets qui le composent que pour les acteurs qui en offre une distribution tant sur une infrastructure propre que sur le cloud. Apache Hadoop® offre aussi une standardisation des formats de fichiers et de traitements.
Apache Hadoop® est devenue en quelques années un standard pour stocker et traiter la donnée. L’exploitation de ce standard a évolué pour connaître une utilisation où l’on exacerbe le découplage stockage et calcul que l’on retrouve sur l’ensemble des distributions du cloud.
A propos du Hadoop User Group France
Synaltic, sous l’impulsion de Charly Clairmont, a été l’un des tout premiers acteurs français à structurer une véritable communauté autour des technologies Big Data open source. Alors que Hadoop commençait à peine à émerger en France, dès le début des années 2010, Charly initie la création du Hadoop User Group France (HUG France), un espace de partage, de veille et d’échanges techniques destiné à démocratiser les usages du Big Data.
Le groupe devient dès 2013 un point de ralliement pour les ingénieurs, architectes et entreprises cherchant à comprendre et adopter Hadoop. Les rencontres régulières, ateliers techniques et retours d’expérience contribuent à diffuser les bonnes pratiques, à accélérer l’adoption des frameworks de l’écosystème (Hive, HBase, Spark, Oozie…) et à structurer une véritable culture Big Data en France.
Au fil des années, le HUG France s’étend, fédère des centaines de membres et devient un lieu incontournable pour suivre l’évolution de l’écosystème. Les discussions s’ouvrent progressivement à Spark, puis aux architectures modernes, comme en témoigne la présence du groupe sur les plateformes communautaires et les meetups associés .
Cette dynamique communautaire a eu un impact direct sur l’évolution du paysage Hadoop en France :
- accélération de l’adoption des technologies distribuées,
- structuration d’un réseau d’experts,
- diffusion des pratiques open source,
- transition progressive vers les architectures modernes (Spark, Lakehouse, Iceberg)
Aujourd’hui encore, l’héritage du Hadoop User Group France se retrouve dans les communautés modernes comme Spark ou Modern Data Stack France.
Et maintenant ?
Néanmoins, une difficulté et non des moindres est de pouvoir exploiter simplement les nouveaux moteurs d’interrogation plus rapides que ceux qui sont embarqués dans Hadoop. Qui plus est, comme le stockage et le calcul sont quand même couplés… Il n’est point évident de faire évoluer l’un sans l’autre. C’est-à-dire que lorsque vous voulez faire évoluer HDFS, vous faire naturellement évoluer Hive. Et si vous voulez faire évoluer Yarn… Vous faites naturellement évoluer HDFS.
Il est aujourd’hui question d’avoir une stratégie pour pleinement exploiter vos données dans le but d’organiser vos décisions selon les données. Et c’est pourquoi nous vous conseillons d’impémenter Apache Iceberg™, le format de table open-source qui transforme votre lac de données en un véritable Data Lakehouse !
Nos derniers articles de Blog autour d’Hadoop

Moderniser Hadoop, Hive avec Apache Iceberg™

Etes vous prêts pour le Data Lakehouse ?
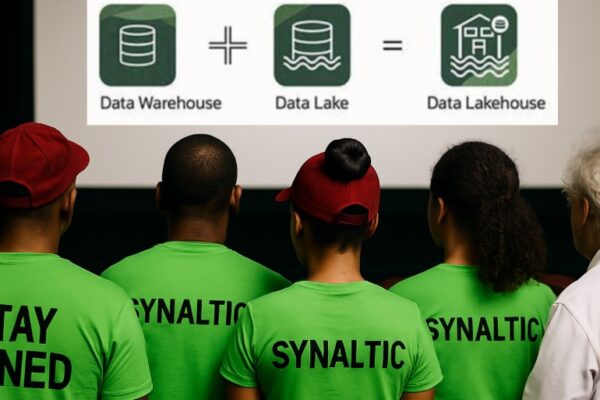
Data Lake vs. Data Lakehouse

Dremio, une nouvelle page s’ouvre

Cloud Data Warehouse: Comment choisir votre data warehouse dans le cloud entre Redshift, Azure, Snowflake, Bigquery ?

#StrataData | Un basculement vers le Fast Data
Contactez-nous pour évoquer Hadoop :
*tous les champs sont obligatoires
