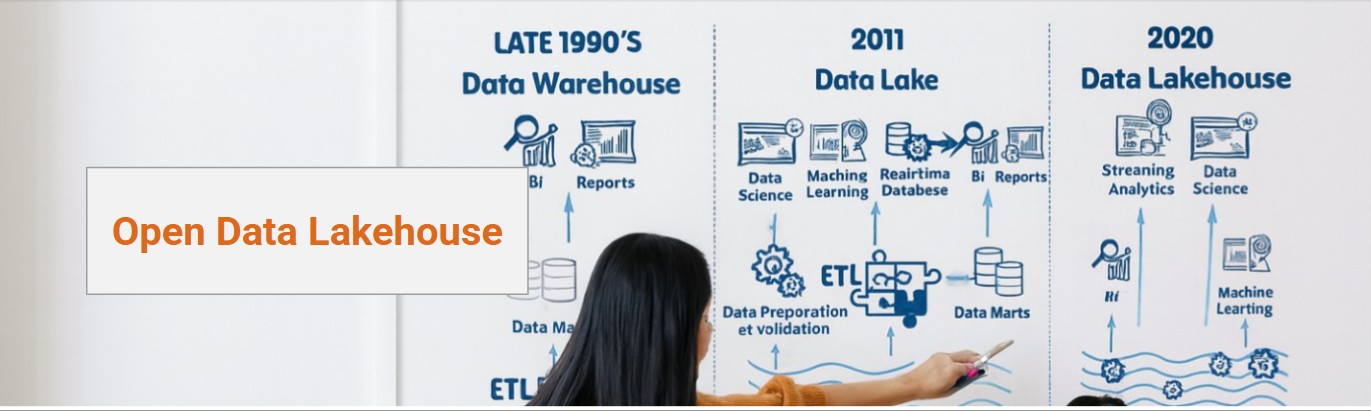
Construire et faire évoluer son open data lakehouse avec Synaltic !
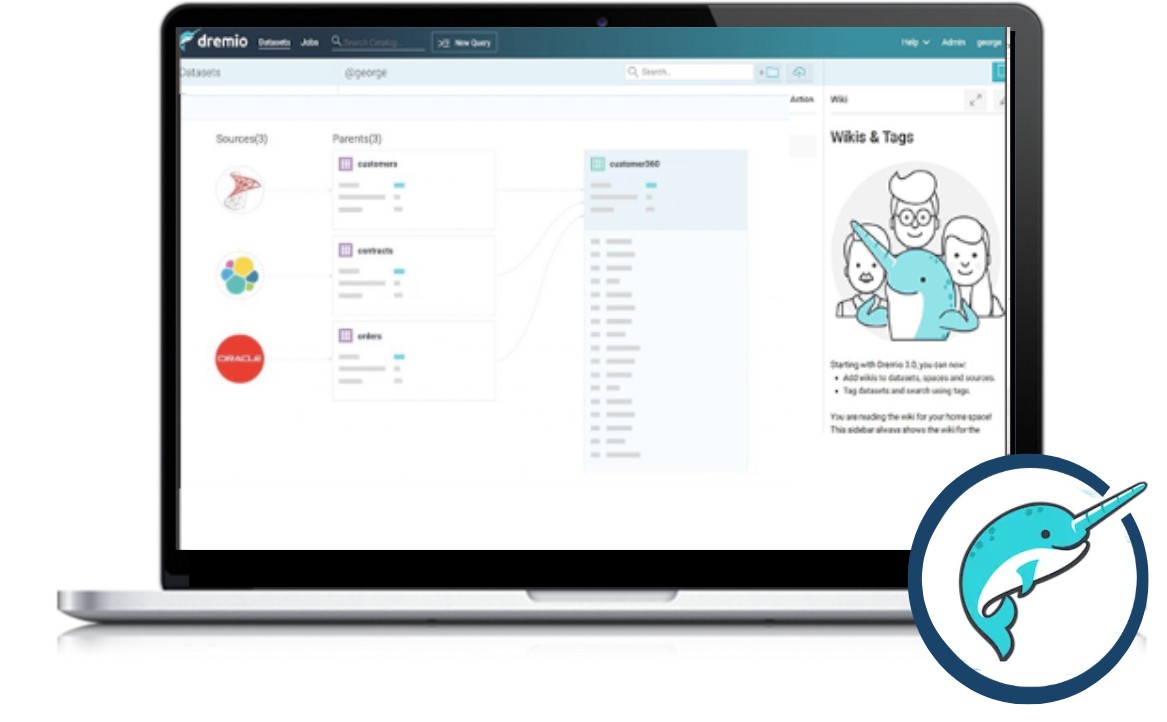
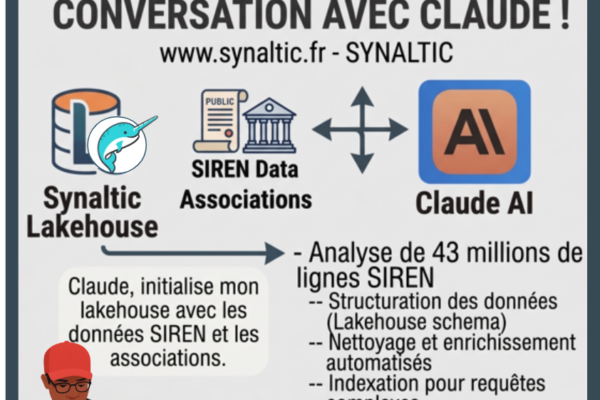
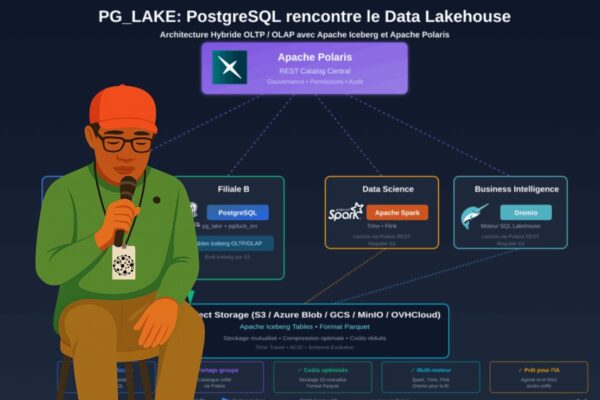
Chez Synaltic, nous considérons l’Open Data Lakehouse comme une évolution naturelle, voire un certain aboutissement. Il y a déjà 20 ans, nous accompagnions nos clients dans la mise en place et l’évolution de leurs data warehouses. Nous parlions de qualité et de gouvernance… puis sont arrivés les projets Big Data et le Cloud. Nous avons vu l’architecture évoluer du data warehouse au data lake en 2011, puis au data lakehouse à partir de 2020.