QLIK OPEN LAKEHOUSE
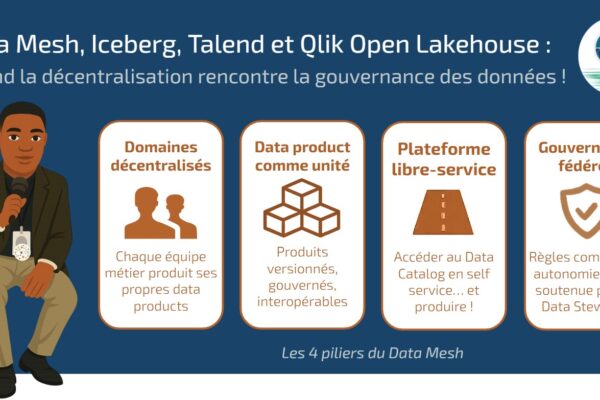
Qlik Open Lakehouse étend les capacités de Qlik Cloud avec une architecture ouverte et évolutive basée sur Apache Iceberg™.
Pensée pour l’ingestion en temps réel, la gouvernance avancée et l’analyse augmentée par l’IA, cette solution permet de gérer efficacement des données massives et hétérogènes, tout en s’adaptant aux architectures distribuées et aux usages émergents.