

Si vous utilisez dbt Core, vous vous êtes sûrement déjà posé la question : “comment orchestrer les commandes que je tape à la main 🤔?” Que ce soit pour vérifier la qualité ou la fraîcheur de vos données, ou pour mettre à jour vos modèles, l’automatisation devient vite indispensable.
Depuis le rachat de dbt Labs par Fivetran en octobre 2025, une nouvelle voie s’est ouverte : celle d’une orchestration intégrée, propriétaire et payante, au sein de la plateforme Fivetran. Cette solution peut séduire les équipes cherchant une expérience tout-en-un, avec ingestion et transformation réunies dans un même environnement.
Mais si vous préférez garder la main sur vos outils, rester dans l’univers open source, ou simplement éviter les coûts et la dépendance à une plateforme fermée, alors cet article est fait pour vous. Nous vous proposons ici une alternative simple et efficace : orchestrer vos commandes dbt avec Mage AI, un outil open source apparu en 2021 qui permet de créer et orchestrer des pipelines de données en python principalement sur une plateforme collaborative. libre, léger et collaboratif.

Dans le cadre de cet article, on suppose que l’on a déjà un projet dbt et que l’on cherche à l’orchestrer avec MageAI. Nous allons pour cela réutiliser le projet dbt créé dans un article précédant où on y trouve 10 modèles et une source avec 7 tables, avec des tests définis au niveau des tables sources et des modèles. Ces modèles sont matérialisés dans Dremio avec les dépendances comme sur le schéma ci-dessous.
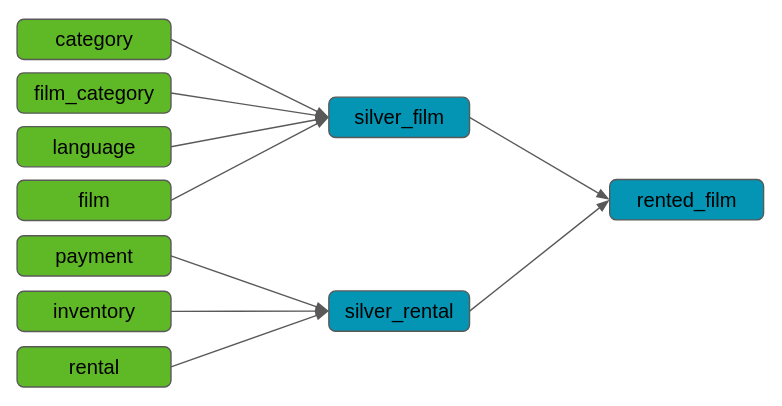
Pour l’exercice on va chercher à orchestrer la suite de commandes suivantes :
dbt debug -q: pour vérifier que la connexion avec Dremio est fonctionnelle.dbt source freshness -q: pour vérifier que les données des sources sont fraîches avant de mettre à jour nos tables.dbt test -s "source:*" -q: pour vérifier que les données des sources sont conforme à nos attentes.dbt build -s 1+rented_film -q: pour mettre à jour les tables et contrôler la conformité des données (dans ce projet les 3 modèles en bleu sont des vues, les données sont toujours à jour mais supposons pour l’exemple que ce sont des tables).
Note : cet article utilise la version 0.9.76 de Mage AI et la version 1.8.1 de dbt-dremio (et version 1.8.7 de dbt-core). Mage AI est déployé en local avec docker tout comme Dremio.
Mise en œuvre dans MAge AI
Étape 1 : Vérifier que dbt est bien installé dans Mage AI
Étape 2 : Importer votre projet dbt dans Mage AI + le fichier profiles.yml
Étape 3 : Création d’un nouveau pipeline
Étape 4 : Ajouter un trigger au pipeline pour planifier son exécution
Etape 1 : Vérifier que dbt est bien installé dans Mage AI
Mage AI embarque déjà plusieurs connecteurs dbt, il suffit de vérifier que celui dont vous avez besoin est bien installé et avec la bonne version, sinon il faudra l’installer.
Dans Mage AI, allons dans le menu et cliquons sur Terminal.
Une fois dans le terminal, tapez la commande dbt --version, pour vérifier que le connecteur est bien installé et avec la bonne version.
Dans notre cas, le connecteur dbt-dremio est bien installé.
Etape 2 : Importer votre projet dbt dans Mage AI + le fichier profiles.yml
Dans cet article, on ne verra pas la chaîne d’intégration continue qu’il faudrait mettre en place si on était en production. On va seulement voir comment planifier des commandes dbt. Ici, on a simplement importé le projet dbt en copiant le répertoire dans le conteneur docker de Mage AI.
Il faut placer le projet dbt dans le répertoire dbt/ de Mage AI (/home/src/<votre_nom_de_projet_mage>/dbt/) et dans le projet dbt ajouter le fichier profiles.yml (dbt/<votre_nom_de_projet_dbt>/profiles.yml).
Ci-dessous on a ajouté le projet dbt nommé webinaire_demo avec le fichier profiles.yml à l’intérieur.
Dans le fichier profiles.yml, il faut renseigner les informations de connexion de votre plateforme de données. Vous pouvez définir plusieurs environnements, ici on a juste définit un environnement dev. Pour masquer les paramètres de connexion user/password, il y a la possibilité d’utiliser les variables d’environnement ou les secrets.

Etape 3 : Création d’un nouveau pipeline
Dans la page des pipelines (menu>pipeline), ajoutons un nouveau pipeline article_dbt_demo :
Ajoutons un blocs dbt de type “Generic dbt command” :
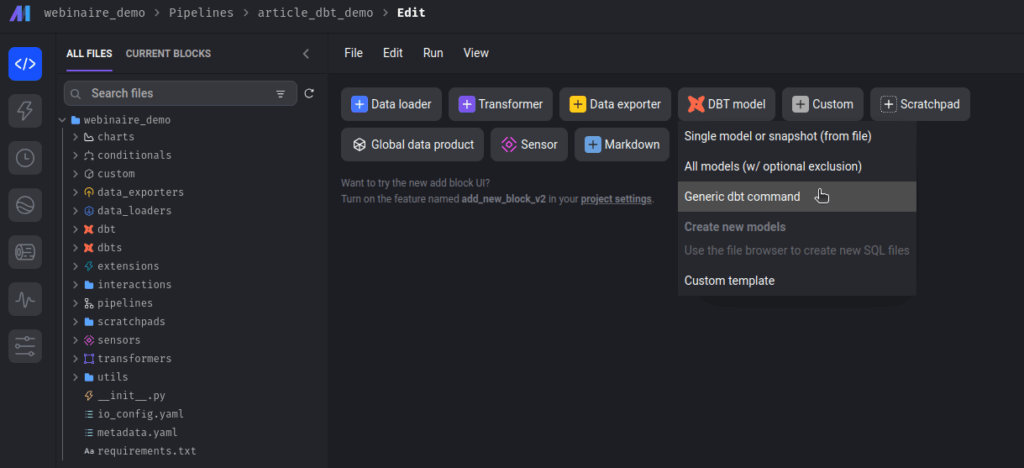
Nommons ce bloc dbt_debug pour notre première commande dbt à exécuter.
Pour chaque bloc “dbt de type generic dbt command” il faut renseigner :
- le projet dbt
- une target de votre profile de connexion (l’environnement sur lequel vous souhaitez exécuter votre commande)
- la commande dbt que vous souhaitez exécuter
- des options de commandes (optionnelles)
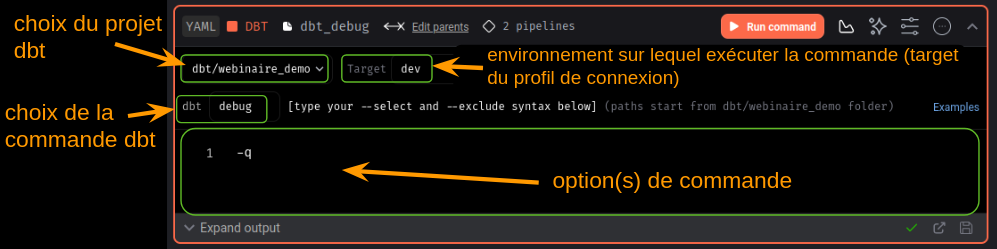
Pour ce 1er bloc on va choisir notre projet dbt webinaire_demo, dev comme target et la commande dbt debug. On a rajouté ici l’option de commande -q pour limiter les logs dans la console en sortie.
On peut ensuite cliquer sur le bouton Run command pour exécuter la commande et vérifier la configuration.
Ajoutons 3 autres blocs de la même manière pour les commandes définit plus haut (dbt source freshness, dbt test et dbt build) :
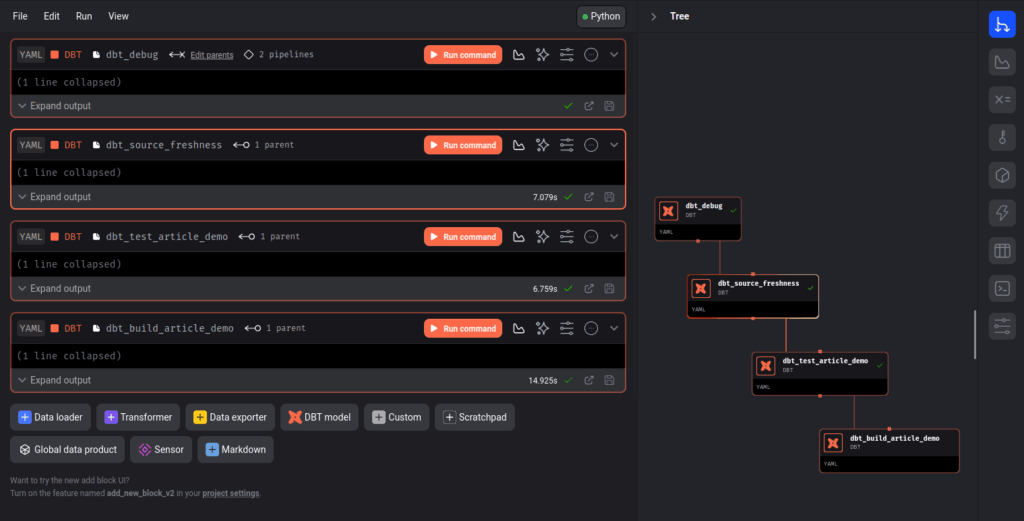
Note : pour la commande dbt source freshness, si lorsque vous mettez ‘source freshness’ dans l’espace commande prévu et que ça vous retourne le message d’erreur « dbt source freshness command not found », alors mettez uniquement source dans la commande et mettez freshness dans la console pour les options de commande, comme ci-dessous.
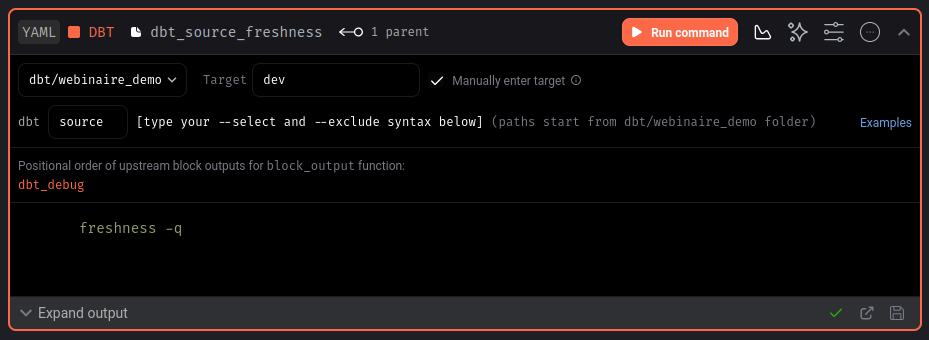
Notre pipeline est maintenant prêt, il ne reste plus qu’à planifier l’exécution de notre pipeline.
Information :
Lorsqu’un nouveau bloc dbt est créé (generic dbt command), un fichier yml portant le même nom est créé sous le répertoire dbts/ contenant les options de commande tapées dans le bloc.
Toutes les autres informations définies dans le pipeline (projet, target, commande, etc.) sont sauvegardées dans le fichier metadata.yml du pipeline (pipelines>pipeline_name>metadata.yml).
Etape 4 : Ajouter un trigger au pipeline pour planifier son exécution
À gauche dans le menu du pipeline, allons dans Triggers :
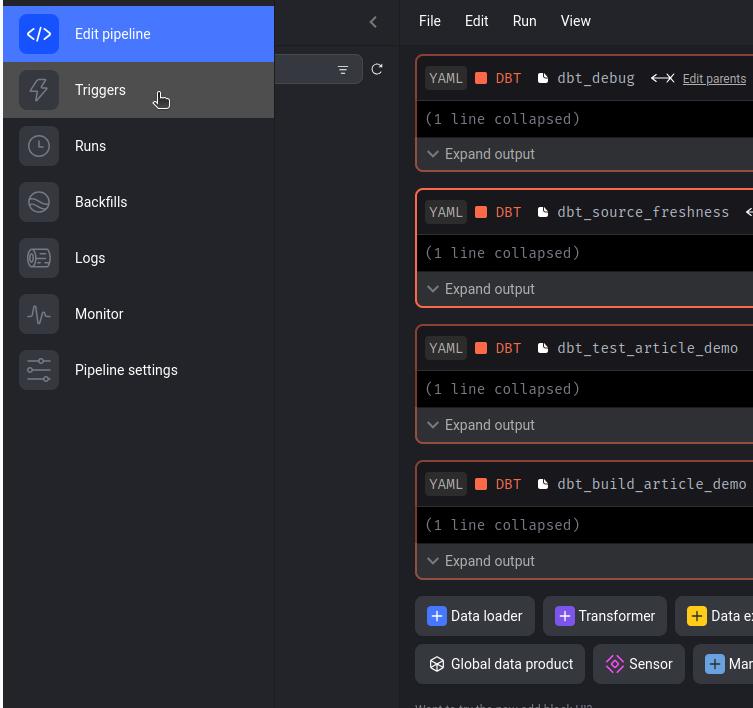
Ajoutons un trigger :
Choisissons Schedule pour le type du trigger.
Nommons le daily_execution et ajoutons lui une fréquence d’exécution.
Vous avez la possibilité de choisir une fréquence prédéfinie ou alors de la customiser avec un cron :
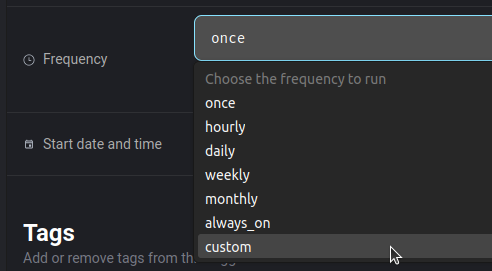
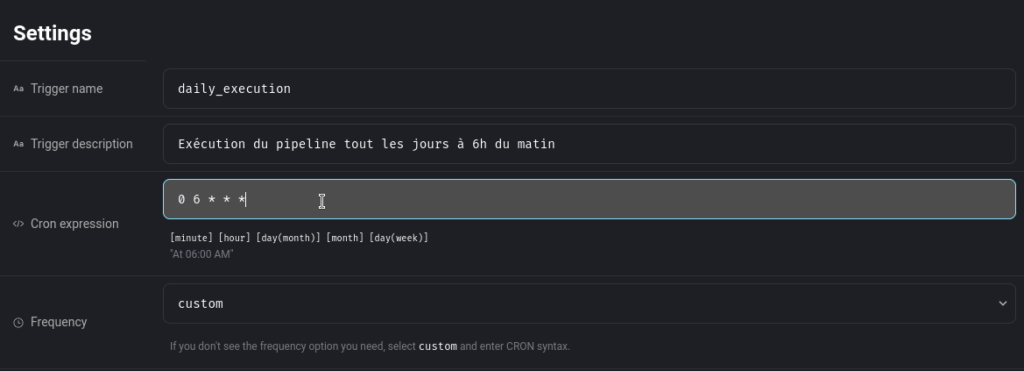
À droite, vous avez des configurations plus avancées pour le trigger mais nous ne les verrons pas dans cet article.
Enregistrons le trigger. Il ne reste plus qu’à l’activer en cliquant sur le bouton Enable trigger.
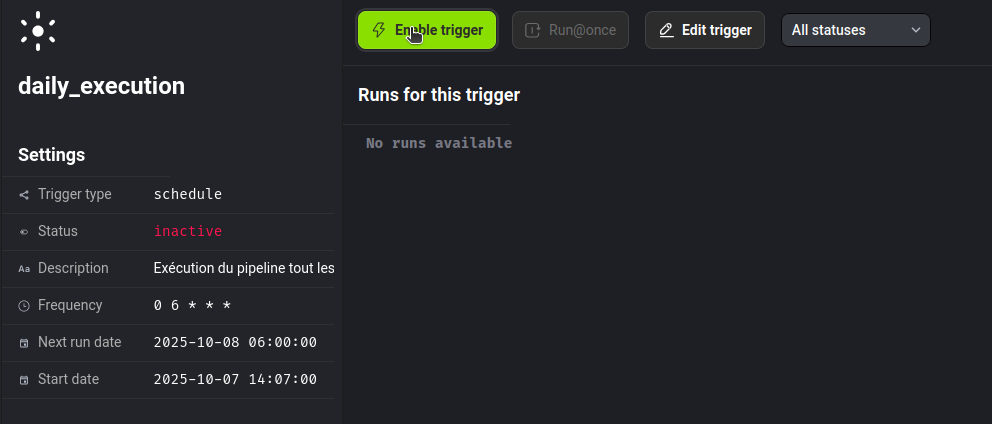
Notre pipeline est maintenant bien planifié pour s’exécuter tous les jours à 6h.

En cliquant sur le nom du trigger, on peut voir l’historique de toutes les exécutions et on a la possibilité de lancer manuellement le trigger en cliquant sur le bouton Run@once :

Exemple d’exécution en succès (status=Done) :

On peut regarder les logs d’exécution en cliquant sur le bouton de la colonne logs.
Exemple (les derniers logs de l’exécution) :
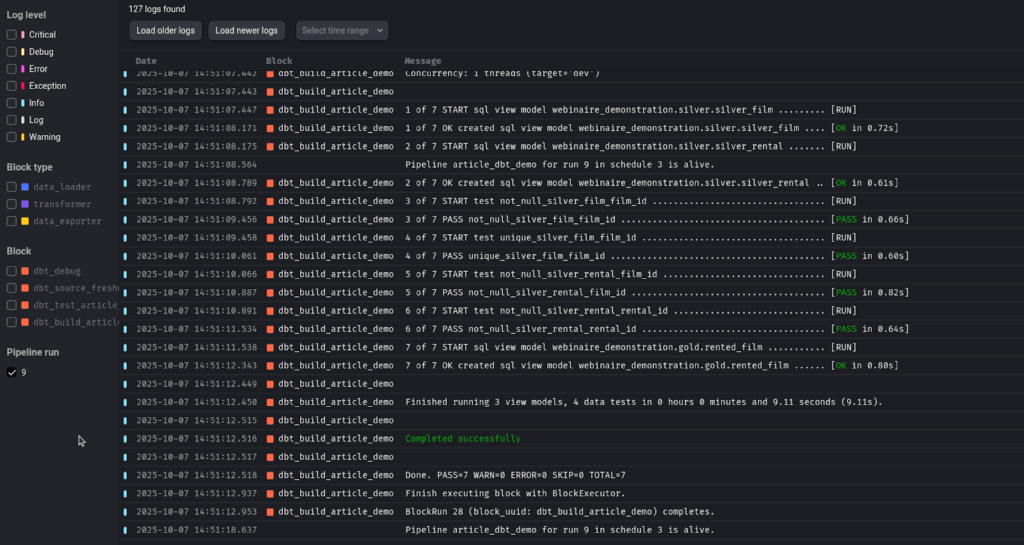
A gauche vous avez la possibilité de filtrer les logs par bloc ou par niveau de log. Cela permet de déboguer rapidement.
Exemple d’exécution en échec (status=Failed) :

Seulement 1 bloc sur 4 est en succès, il y a donc eu une erreur dans le 2ème bloc (les 2 autres blocs ont été sautés), regardons les logs :
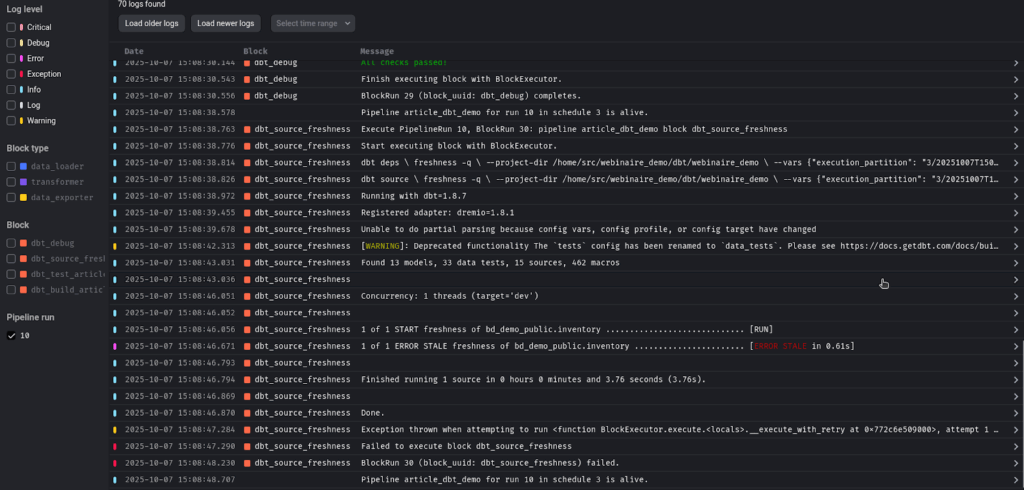
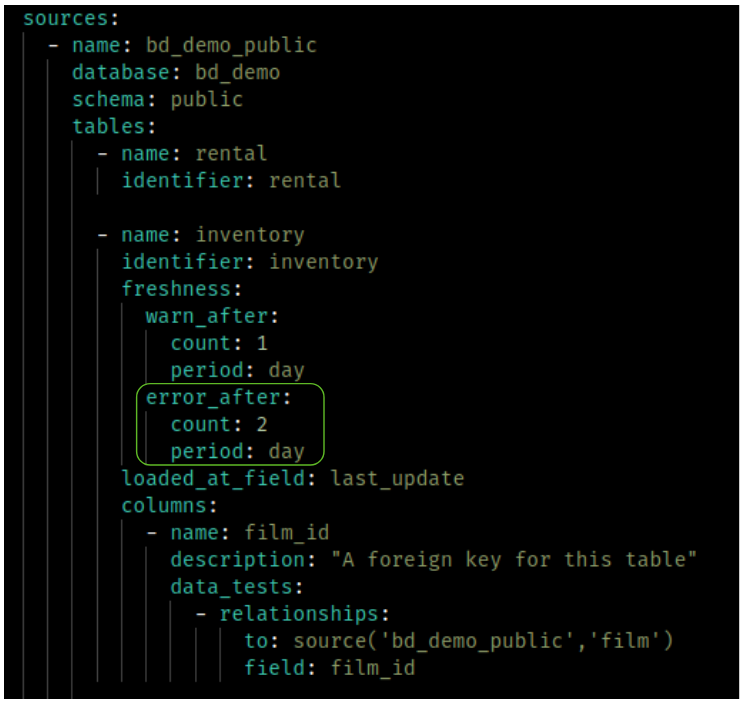
La table source inventory est en erreur pour la commande dbt source freshness.
Et effectivement dans la base, les données ne respectent pas la configuration sur la fraîcheur des données.
Conclusion
En conclusion, nous avons vu dans cet article comment orchestrer facilement et de manière centralisé nos commandes dbt dans Mage AI. Maintenant à vous de jouer 😉.
La documentation :
- https://docs.mage.ai/guides/dbt/add-existing-dbt
- https://docs.mage.ai/guides/dbt/run-single-model
- https://docs.mage.ai/guides/dbt/run-selected-model
D’autres articles sur dbt :
