







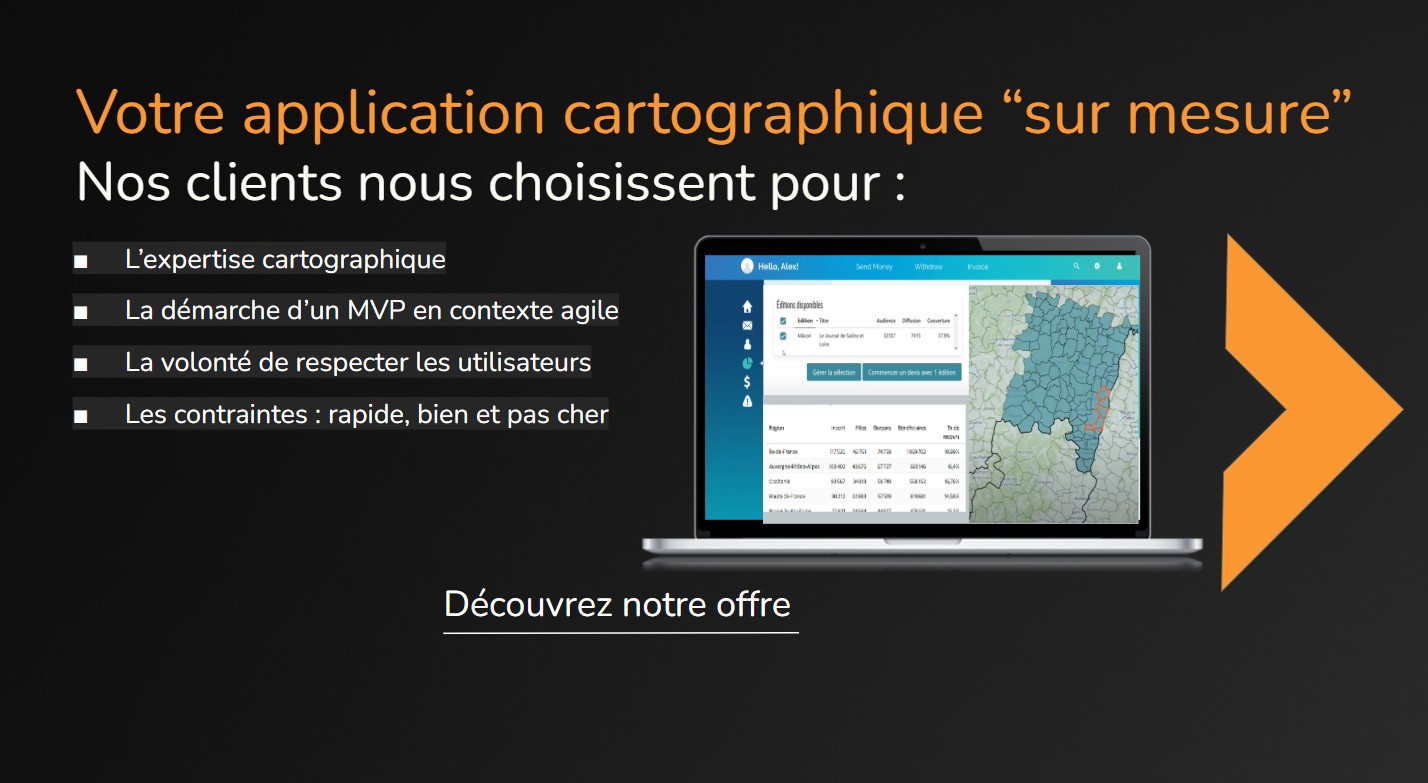

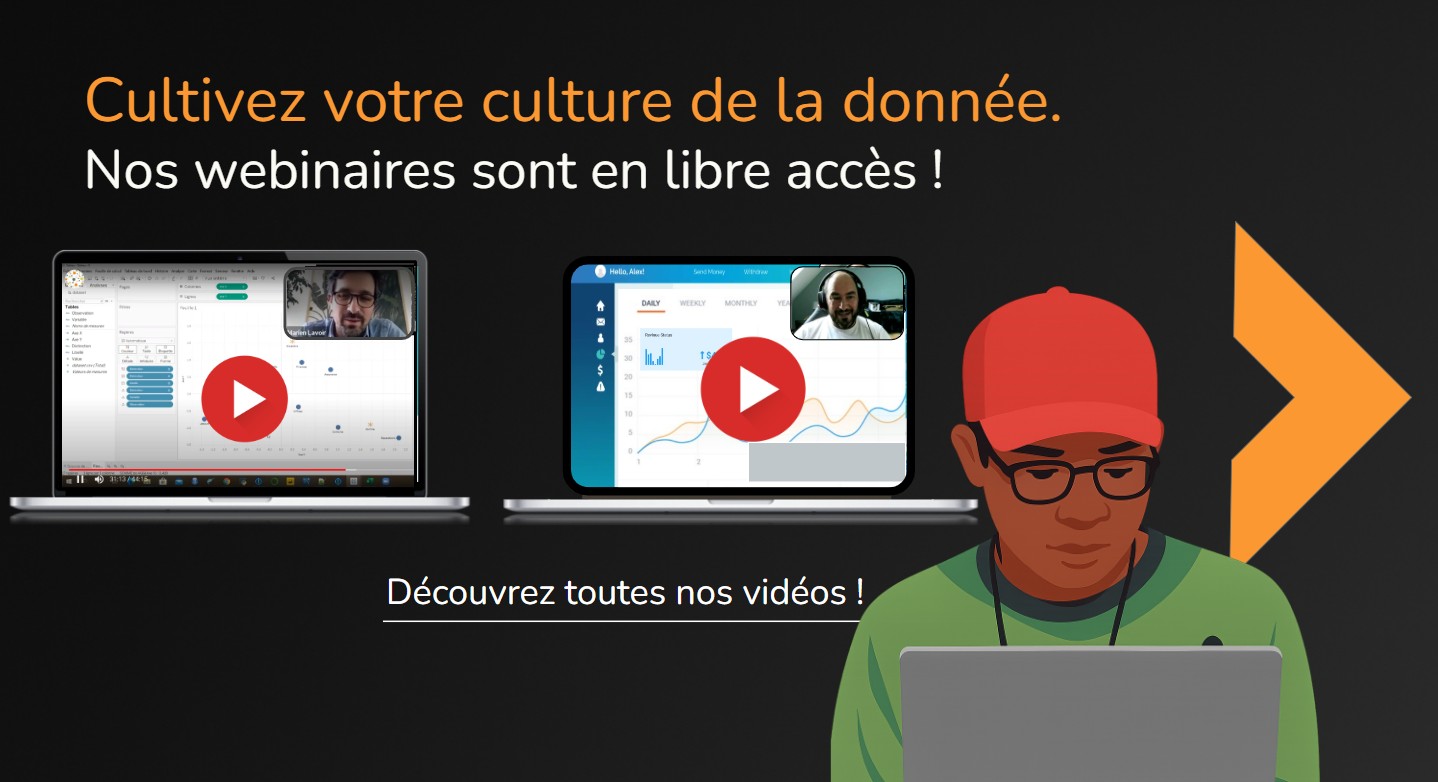
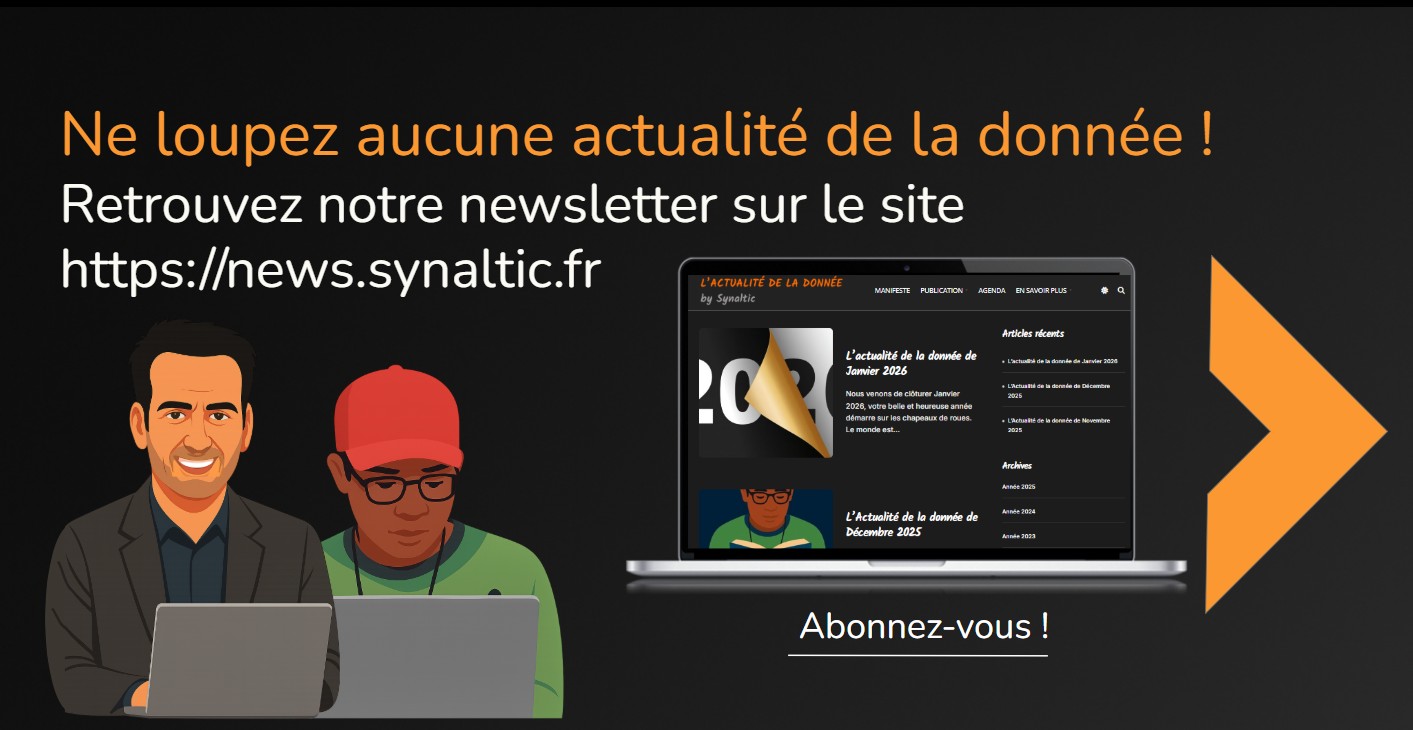
Depuis plus de 20 ans, Synaltic propose des alternatives Open Source — lorsqu’elles existent — pour mener à bien vos projets d’intégration et de consolidation de données.
Aujourd’hui, les enjeux de gouvernance, de souveraineté et de coûts nous incitent plus que jamais à recommander l’Open Data Lakehouse : une plateforme de données fondée sur des solutions Open Source et des formats ouverts.
Découvrez les solutions sur lesquelles nous nous appuyons
Grâce à ses choix de partenaires dès leur plus jeune âge et l’appui de ses collaborateurs certifiés, Synaltic est reconnu comme un pionnier de l’open source, dénicheur de solutions et de talents.







Le parcours data que nous construisons ensemble
Vos données
EXTRACTION & INGESTION MULTICANALE

Synaltic vous accompagne pour récupérer vos données, quel qu’en soit le type et où qu’elles se trouvent (API, applications, bases, fichiers, IoT, logs, événements) et les intégrons dans des pipelines fiables, automatisés et scalables.
Cadre & Gouvernance
Nous définissons ensemble les usages, les sources de données et les règles de gouvernance qui structurent votre plateforme data & IA. Une démarche de co-construction collaborative, maîtrisée et alignée sur vos enjeux métiers.
Fiabilité & Observabilité
Pas de stratégie digitale, pas d’IA ni de pilotage fiable sans qualité de données : nous mettons en place les processus, tests et outils qui garantissent qualité, traçabilité et conformité de vos données.
Enrichissement & Modélisation
Nous enrichissons vos données grâce à des sources internes et externes (open data, web, événements), et construisons des modèles adaptés à vos usages : analytics, prédiction, IA générative.

Activation & Accès
Vos équipes accèdent à des données fiables, documentées et activables via des API, des espaces analytiques, des notebooks ou des outils de visualisation. Le self‑service devient possible et gouverné.
Décision & IA appliquée
Vision client 360°, optimisation opérationnelle, maintenance prédictive, détection d’anomalies, agents IA… Grâce aux tableaux de bord, aux modèles et aux assistants intelligents, vos équipes transforment la donnée en impact.

Vos informations
prêtes pour vos collaborateurs, vos partenaires, vos agents IA, et vos clients !
Contactez-nous et parlons de vos données
Ils nous font confiance
Nous sommes là pour servir, innover et favoriser l’excellence dans un monde axé sur les données.

















