
Orchestration Moderne des Pipelines Data avec Airflow, DBT, Dremio et Cosmos.
Vous trouverez plusieurs articles sur notre site qui présentent DBT, le framework ETL que nous utilisons pour construire les pipelines servant à créer et livrer des produits de données.
Les modèles DBT ont pour objectif d’alimenter régulièrement un data warehouse ou un data lakehouse, afin que les données soient disponibles à temps pour les utilisateurs. Couplées à des solutions de visualisation comme Tableau, Power BI ou Apache Superset, ces données deviennent un levier de décision métier.
La construction et la réalisation des modèles DBT n’est pas le but final. En effet, l’exécution régulière des modèles pour alimenter les bases de données et rendre la donnée disponible aussitôt qu’elle est attendu constitue le vrai défi.
Alors, comment réaliser l’exécution de projet DBT ? Comment suivre dans le détail chacune de ces exécutions ?
Autant de questions auxquelles nous allons chercher à répondre dans cet article.
Le temps, c’est de l’argent, dit-on souvent — et cela n’a jamais été aussi vrai dans les projets data. Aujourd’hui, l’architecture en médaillon s’impose comme le standard pour construire des produits de données robustes et évolutifs.
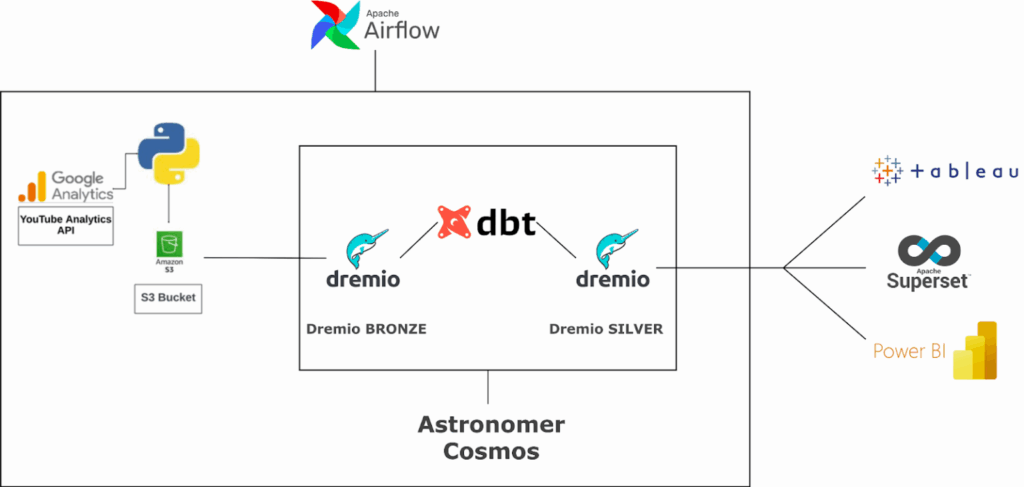
Dans cet article, nous allons explorer la mise en œuvre concrète d’un projet fondé sur ce modèle, orchestré avec Apache Airflow, et destiné à alimenter un data lakehouse sous Dremio.
Les transformations sont réalisées avec DBT, comme mentionné précédemment. Mais ici, nous mettons particulièrement l’accent sur Cosmos, un projet open source qui permet un suivi d’exécution clair, granulaire et en temps réel du pipeline
Stack utilisée : une architecture cohérente et industrialisable
DBT – Le cœur des transformations
« Le cerveau de la transformation »
- Structuration des transformations SQL en modèles clairs et testés
- Gestion des dépendances entre modèles
- Intégration native avec Dremio via profil YAML
- Tests automatiques (unicité, nulls, relations)
Dremio – Le moteur analytique haute performance
« Le moteur d’exécution des requêtes »
- Exécution rapide grâce au cache et aux reflections
- Virtualisation de sources diverses sans ETL
- Génération automatique de vues et tables depuis DBT
- Suivi des performances et accélérations
Airflow – L’orchestrateur central
« Le chef d’orchestre »
- Automatisation de l’exécution via DAGs
- Planification, dépendances, redémarrage intelligent
- Visualisation graphique de chaque étape
Cosmos – Le lien intelligent entre Airflow et DBT
« Le traducteur entre les deux mondes »
- Création automatique de tâches Airflow à partir des modèles DBT
- Centralisation de la configuration (projets, profils)
- Visualisation des groupes de modèles sous forme de TaskGroups

Description du pipeline :
Ce pipeline repose sur Apache Airflow, avec Cosmos pour orchestrer automatiquement l’exécution d’un projet DBT. Chaque modèle DBT est transformé, via Cosmos, en une tâche Airflow indépendante, qui exécute une requête SQL sur Dremio. Cela permet une exécution parallélisée, un suivi détaillé, et une gestion fine des erreurs.
Le pipeline s’appuie sur le modèle en médaillon (Bronze, Silver, Gold), une approche structurante pour les projets data.
- Bronze : les données brutes sont récupérées directement depuis Dremio, à partir des tables d’événements ou de commandes.
- Silver : les données sont nettoyées, enrichies et filtrées via des modèles DBT. Par exemple, on joint les commandes avec les montants, on exclut les produits inactifs, etc.
- Gold : des vues prêtes à l’analyse peuvent ensuite être construites pour servir directement les dashboards métier.
Cas d’usage concret :
Automatisation de la création quotidienne de vues dans Dremio pour l’analyse des ventes par catégorie de produit.
Contexte métier
Une entreprise de e-commerce souhaite suivre chaque jour son chiffre d’affaires par catégorie de produit. Pour cela, plusieurs étapes sont enchaînées dans le pipeline :
- Extraction (Bronze) : récupération des commandes passées au cours des dernières 24 heures.
- Transformation (Silver) :
- Enrichissement avec les montants et les produits associés
- Filtrage pour ne conserver que les produits actifs
- Agrégation (Gold) : calcul du chiffre d’affaires total par catégorie de produit.
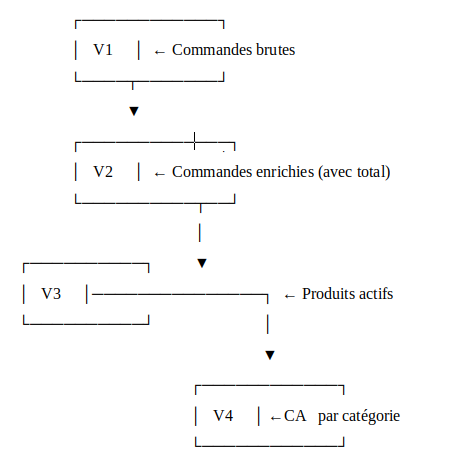
Le résultat est une vue matérialisée et optimisée dans Dremio, actualisée chaque jour, et directement exploitable par les équipes via des outils comme Tableau, Power BI ou Superset..
Implémentation technique
Le pipeline est défini sous la forme d’un DAG Airflow à l’aide de Cosmos :
basic_cosmos_dag = DbtDag(
project_config=ProjectConfig(dbt_project_path=DBT_PROJ_DIR),
profile_config=ProfileConfig(
profile_name="cosmos_test",
target_name="dev",
profiles_yml_filepath=DBT_PROFILE_PATH,
),
operator_args={"install_deps": True},
schedule="@daily",
start_date=datetime(2023, 1, 1),
catchup=False,
dag_id="basic_cosmos_dag",
default_args={"retries": 0},
)Chaque exécution du DAG génère :
- Une exécution (DbtRunLocalOperator) pour l’exécution du projet DBT
- Un test automatique (DbtTestLocalOperator) pour valider automatiquement les modèles
Les tâches sont regroupées par domaine fonctionnel (par exemple : commandes, produits, revenus), ce qui rend le pipeline lisible et maintenable, même en cas de croissance du projet.
Visualisation dans Airflow : comprendre, suivre, corriger
Grâce à Cosmos, chaque modèle DBT, ainsi que chaque fichier SQL qu’il contient, est automatiquement converti en une tâche distincte dans Airflow. Ces tâches sont organisées visuellement dans l’interface graphique, ce qui permet de suivre l’enchaînement logique des transformations de manière claire et intuitive.
Voici un exemple réel du graphe généré dans Airflow :
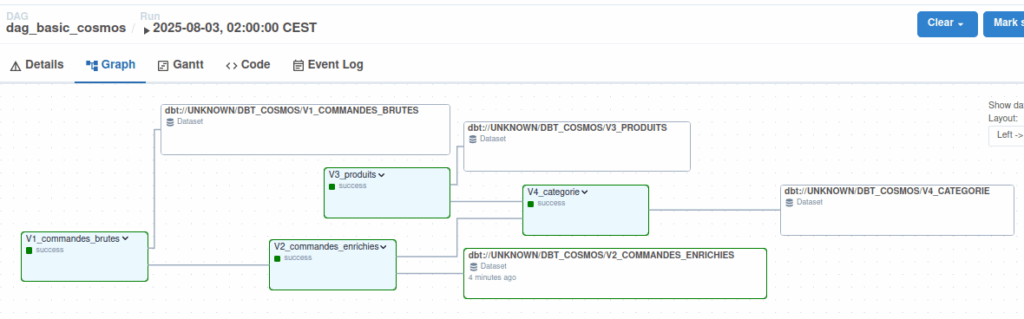
Chaque groupe (V1, V2, V3, V4) représente un sous-ensemble de modèles DBT envoyés à Dremio. Pour chaque modèle :
- L’exécution (run) déclenche la requête SQL dans Dremio
- Le test (test) valide le résultat selon des règles prédéfinies
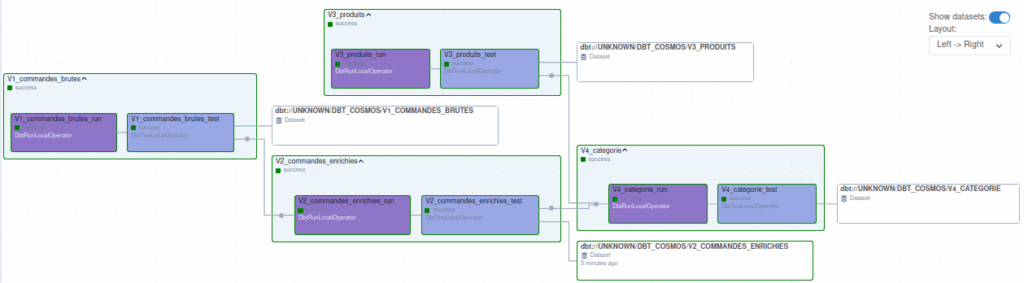
On visualise immédiatement :
- Les tâches exécutées avec succès
- Les éventuels échecs
- Les dépendances entre transformations
Cela permet une supervision en temps réel, avec une capacité de redémarrage sélectif.
Dremio : exécution des requêtes DBT
DBT génère les requêtes SQL en fonction des modèles définis, et les exécute directement dans Dremio, qui crée les vues finales
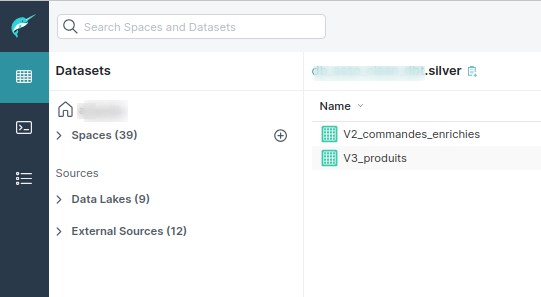
On observe clairement sur l’image ci-dessous que deux vues ont été générées dans la couche Silver, suite aux transformations appliquées via DBT.
Déroulement du pipeline
- Planification quotidienne : Un DAG Airflow est configuré pour s’exécuter une fois par jour. Ce DAG pilote l’ensemble du processus d’orchestration via Cosmos.
- Orchestration avec Cosmos et DBT : Grâce à Cosmos, le DAG lance le projet DBT, qui contient les modèles SQL correspondant aux quatre vues à créer dans Dremio. DBT, connecté à Dremio via un profil dédié, exécute les requêtes SQL dans l’ordre défini par les dépendances entre les vues.
- Création et mise à jour des vues dans Dremio : Chaque vue est matérialisée dans Dremio et optimisée pour un accès rapide et efficace. Ces vues permettent ensuite aux équipes de réaliser des analyses ou traitements métiers spécifiques.
- Suivi en temps réel dans Airflow : Le graphe des tâches dans Airflow affiche clairement chaque étape (création des vues), leur état (succès ou échec), ainsi que l’ordre d’exécution. Cela permet de visualiser facilement quelles vues ont été créées avec succès, et d’identifier rapidement d’éventuels problèmes.
Quels sont les bénéfices concrets de cette méthode ?
- Automatisation complète : Le pipeline s’exécute automatiquement chaque jour, sans intervention manuelle. Cela garantit fiabilité, régularité et gain de temps.
- Suivi et visualisation clairs : Airflow (avec Cosmos) offre une vue graphique de l’ensemble des tâches, leurs dépendances, leur état (succès/échec), et permet un diagnostic rapide en cas d’erreur.
- Gestion des erreurs facilitées : En cas de problème, seules les étapes concernées peuvent être relancées. Pas besoin de tout reprendre depuis le début.
- Traçabilité des transformations : Chaque vue ou requête est liée à ses sources (tables, autres vues), ce qui facilite la compréhension des flux et l’analyse d’impact.
- Performance optimisée : Dremio garantit des temps de réponse rapides, même sur des volumes importants, grâce à la matérialisation et à l’optimisation des vues.
- Standardisation du code : DBT permet de coder les transformations proprement, de les versionner, et d’éviter les scripts isolés non documentés.
- Collaboration fluide : La clarté du pipeline et la structuration des transformations facilitent le travail en équipe entre data engineers, analystes et métiers.
En quoi cette méthode améliore la clarté et la structure d’un projet data ?
- Vue d’ensemble visuelle : Le graphe Airflow rend le pipeline lisible en un coup d’œil – on voit où on en est, ce qui dépend de quoi, et ce qui a échoué.
- Configuration centralisée : Cosmos centralise la configuration de DBT, ce qui évite la dispersion des fichiers et facilite la maintenance.
- Environnements bien gérés : Grâce aux profils DBT, on peut exécuter le pipeline dans différents environnements (développement, production), tout en gardant un contrôle clair sur les versions.
Comment cette approche facilite-t-elle le travail d’équipe ?
- Un cadre pédagogique clair : Chaque étape du pipeline est logique, visible et documentée, ce qui permet à chacun de comprendre rapidement le fonctionnement.
- Des outils standards : La stack repose sur des outils robustes et largement adoptés (Airflow, DBT, Dremio), ce qui assure leur maintenabilité et facilite l’onboarding des nouveaux arrivants.
- Une solution complète : La combinaison DBT + Dremio + Cosmos + Airflow couvre l’ensemble du cycle de vie des données, sans superflu.
Cette architecture offre :
- Robustesse : automatisation fiable et testée
- Lisibilité : pipelines clairs, regroupés par logique métier
- Auditabilité : chaque transformation est traçable et testée
- Performance : traitement rapide, intégré à la couche analytique Dremio
Conclusion :
Une architecture moderne, efficace et maintenable, l’association d’Airflow, Cosmos, DBT et Dremio constitue un socle robuste et évolutif pour orchestrer les pipelines de données. Cette architecture combine automatisation, visibilité et contrôle, tout en s’appuyant sur des outils largement adoptés dans l’écosystème data.
Rôles de chaque composant :
- Airflow (via Cosmos) : orchestre l’exécution des workflows, planifie et structure les tâches via un DAG.
- DBT : transforme les données avec du SQL versionné, en générant des modèles testés et documentés.
- Dremio : exécute les requêtes, gère les vues et optimise l’accès aux données via son moteur analytique
Synaltic est votre partenaire pour mettre en œuvre une plateforme de données solide, au service de vos prises de décision.
Nous accompagnons nos clients dans la conception, la réalisation et l’industrialisation de projets data adaptés à leurs enjeux métiers.
