
Les entreprises collectent et produisent de plus en plus de données. Pourtant, la majorité d’entre elles peinent à les exploiter pleinement : silos organisationnels, goulots d’étranglement dans les équipes IT, problèmes de qualité, une équipe métier doit attendre parfois des semaines que l’équipe data centrale prépare ses données…Face à ces défis, une nouvelle approche gagne en popularité : le Data Mesh. Mais comment mettre en œuvre concrètement cette vision ? Et quel rôle peut jouer un outil comme Talend ?
1. Rappel : qu’est-ce qu’un Data Mesh ?
Le Data Mesh est une architecture de données décentralisée qui organise les données par domaine d’activité (marketing, vente, service client, etc.), afin d’offrir plus d’autonomie aux producteurs de jeux de données. Contrairement au modèle centralisé et monolithique (data lake ou data warehouse), le data mesh repose sur 4 principes fondateurs :
- Propriété décentralisée : les données sont organisées par domaine et chaque domaine métier (marketing, finance, supply chain, RH…) est responsable de ses propres données.
- Données = produit : chaque équipe doit gérer ses datasets comme un produit, avec des APIs bien définies, de la documentation, de la qualité et de l’accessibilité. L’objectif est que les données soient facilement consommables par d’autres équipes.
- Infrastructure en self-service (libre-service) : des outils doivent être mis à disposition pour permettre aux équipes de publier et consommer les données de manière autonome. Les équipes métiers n’ont pas à réinventer la roue → elles utilisent la plateforme pour exposer leurs données.
- Gouvernance fédérée : un cadre global de standards et de règles assure cohérence, sécurité et conformité. Chaque domaine est responsable de l’appliquer localement.
En résumé : le Data Mesh rapproche la responsabilité des données de ceux qui les produisent, tout en maintenant une gouvernance transversale.
2. Fonctionnement de l’architecture Data Mesh
Ce schéma montre comment l’architecture Data Mesh permet à chaque domaine de produire et de consommer des produits de données de manière décentralisée et interconnectée.
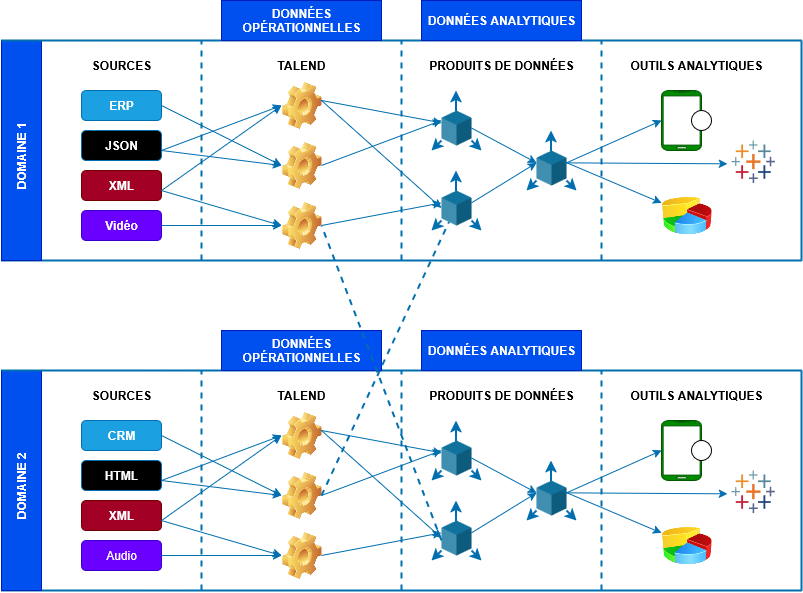
Le diagramme ci-dessus montre comment deux équipes de domaine exploitent ce modèle Data Mesh, la base du modèle étant la plateforme de données en libre-service. Voici une explication détaillée du processus de transformation des données :
Sources de données : chaque domaine collecte des données brutes de différentes sources (indiquées sur la gauche du diagramme).
Données opérationnelles : ces données brutes sont transformées en données opérationnelles, prêtes à être utilisées pour des analyses ou des processus métier.
Produits de données : les données opérationnelles sont ensuite organisées et transformées en produits de données spécifiques. Ces produits sont standardisés et peuvent être utilisés par d’autres domaines.
Données analytiques : les produits de données sont utilisés pour générer des analyses plus ou moins avancées à travers divers outils (visualisation, analyse ad-hoc, data science…).
3. Les défis d’un Data Mesh
Adopter une architecture Data Mesh n’est pas qu’un choix technique :
- Organisationnels : les métiers doivent accepter de devenir “product owners” de leurs données.
- Techniques : il faut une infrastructure pour collecter, transformer et partager les données.
- Culturels : passer d’une approche centrée IT à une approche “produit” des données.
C’est ici que des plateformes d’intégration et de gouvernance comme Talend apportent de la valeur.
4. Le rôle de Talend dans un Data Mesh
Talend, reconnu pour ses solutions d’intégration et de qualité des données, répond à plusieurs piliers du Data Mesh :
a. Préparation et intégration des données
- Extraction depuis des sources multiples (bases SQL/NoSQL, API, fichiers, cloud).
- Nettoyage, standardisation et transformation des données (gestion des doublons, des valeurs manquantes, formats cohérents).
- Automatisation via des jobs ETL/ELT planifiés ou en temps réel.
Chaque domaine peut ainsi préparer ses propres datasets de manière autonome.
b. Données = produit
Avec Talend Data Catalog et Talend Data Quality :
- Chaque domaine peut documenter ses données, définir des règles de qualité et surveiller leur conformité.
- Les datasets sont exposés comme des “produits” utilisables par d’autres équipes.
- Les APIs générées par Talend permettent de publier ces produits de données.
c. Infrastructure en self-service
Talend Cloud offre un environnement as-a-service, accessible même aux métiers non techniques :
- Interfaces low-code pour créer des flux de données.
- Connecteurs préintégrés vers les grandes plateformes cloud (Snowflake, BigQuery, AWS, Salesforce…).
- Automatisation et orchestration facilitée.
Les équipes n’ont plus besoin de solliciter en permanence l’IT pour publier ou consommer des données.
d. Gouvernance fédérée
Talend met en place des standards de gouvernance centralisés :
- Catalogage et traçabilité des données.
- Contrôle qualité automatisé (profiling, règles métiers).
- Conformité réglementaire (RGPD, HIPAA, etc.).
Chaque domaine reste autonome, mais la gouvernance globale garantit sécurité et cohérence.
e. Qlik cloud et Qlik Open Lakehouse : des rôles complémentaires
Dans une architecture Data Mesh, toutes les plateformes n’ont pas le même rôle.
Il est donc essentiel de distinguer Qlik Cloud et Qlik Open Lakehouse, qui répondent à des besoins différents mais complémentaires.
Qlik Cloud
Qlik Cloud est une plateforme SaaS orientée consommation et gouvernance analytique.
Rôle principal :
- Data analytics et data visualization (Qlik Sense)
- Data Integration & Talend Cloud
- Gouvernance transverse (catalogage, métadonnées, lignage)
- Accès self-service pour les métiers
Dans un Data Mesh :
- Point d’entrée centralisé pour découvrir et consommer les data products
- Supporte la gouvernance fédérée
- Facilite l’autonomie des domaines sans multiplier les outils
Qlik Cloud = la couche “expérience & gouvernance” du Data Mesh !
Qlik Open Lakehouse
Qlik Open Lakehouse est une architecture ouverte de stockage et de traitement, basée sur des standards comme Apache Iceberg™.
Rôle principal :
- Stockage des données dans un data lake ouvert
- Gestion des tables Iceberg (schéma, versioning, time travel)
- Interopérabilité avec moteurs de calcul (Spark, Trino, Flink, Snowflake…)
Dans un Data Mesh :
- Socle technique commun pour stocker les data products
- Supporte la décentralisation des domaines
- Évite le verrouillage technologique (vendor lock-in)
Qlik Open Lakehouse = la couche “fondation data” du Data Mesh
Synthèse
| Composant | Rôle clé | Position dans le Data Mesh |
| Qlik Cloud | Gouvernance, analytics, self-service | Cœur transverse |
| Talend | Intégration, qualité, automatisation | Moteur opérationnel |
| Qlik Open Lakehouse | Stockage ouvert, Iceberg | Fondation technique |
5. Exemple concret : un Data Mesh avec Talend dans la distribution
Une grande enseigne de distribution adopte un Data Mesh avec Talend :
- Marketing : prépare un produit de données “Clients” (historique des achats, segmentation).
- Finance : gère le produit de données “Facturation et paiements”.
- Supply Chain : expose un produit de données “Stocks et livraisons”.
Chaque équipe :
- Alimente ses données via Talend (connecteurs vers ERP, CRM, e-commerce).
- Documente et nettoie ses jeux de données dans Talend Data Catalog.
- Publie ses produits sous forme d’API réutilisables par exemple.
Résultat : les données sont disponibles plus rapidement, avec une meilleure qualité, et les métiers peuvent croiser facilement les informations sans attendre un traitement centralisé.
6. Conclusion : Talend, catalyseur du Data Mesh à l’ère d’Apache Iceberg™ et de Qlik
Le Data Mesh n’est pas une technologie, mais un modèle organisationnel et architectural.
Il repose sur la conviction que la donnée doit être décentralisée par domaine, traitée comme un produit, et gérée selon une gouvernance fédérée.
Mais pour que ce modèle fonctionne, il lui faut une infrastructure robuste, capable d’orchestrer :
- l’intégration multi-sources,
- la gouvernance transversale,
- la qualité et la traçabilité,
- et l’automatisation des flux de données.
C’est précisément le rôle de Talend, désormais intégré à l’écosystème Qlik.
Talend assure la collecte, la transformation et la fiabilisation des données, tandis que Qlik enrichit la couche analytique et la gouvernance visuelle.
En parallèle, Apache Iceberg™ devient la brique technique qui consolide la gestion des métadonnées, des schémas et des versions au sein du Data Lake — garantissant ainsi la cohérence, la performance et la conformité des données partagées entre domaines.
En combinant :
- Talend pour la qualité, l’intégration et l’automatisation,
- Apache Iceberg pour la structure et la gouvernance unifiée du stockage,
- et Qlik pour la découverte et la valorisation métier,
les organisations disposent enfin d’un socle complet pour faire vivre le Data Mesh dans la réalité opérationnelle.
Elles passent d’une approche centralisée et rigide à un écosystème fédéré, agile et gouverné, où la donnée devient un produit stratégique au service de la performance et de l’innovation.
