Ce site stocke des cookies sur votre ordinateur. Nous les utilisons afin de personnaliser votre expérience de navigation ainsi que pour des analyses d'audience.
Open Kubernetes Data Platform — une réponse aux coûts cachés de l’assemblage. Vue d'ensemble : le modèle OKDP Lecture du schéma. Le Context (centre) distribue une seule fois les paramètres... Lire la suite →
Traduction libre du billet “What’s New in Apache Iceberg 1.11.0” publié par Alex Merced de Dremio en mai 2026. Un tournant architectural pour le Lakehouse moderne La version 1.11.0 d’Apache Iceberg™ n’est pas une... Lire la suite →
Le Lakehouse moderne repose sur Apache Iceberg™, mais c’est le catalogue qui en détermine vraiment la puissance, l’ouverture… et le degré de dépendance à un fournisseur.Dans ce livre blanc, nous... Lire la suite →
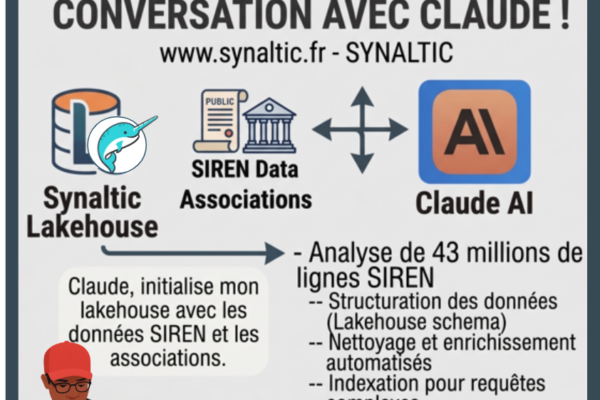
43 millions de lignes SIRENE : initialisation d'un lakehouse "associations" en une conversation avec Claude Et si construire un data lakehouse ne nécessitait plus de connaître par cœur la syntaxe... Lire la suite →
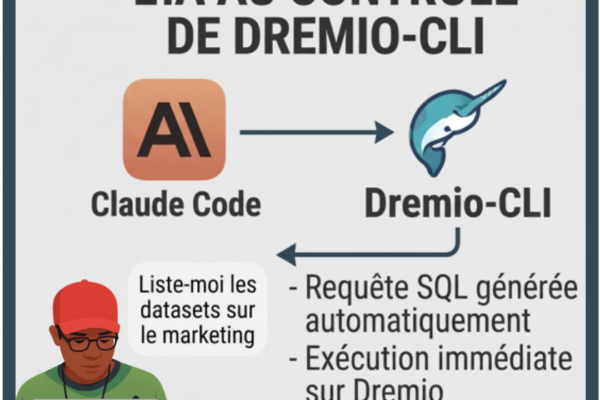
dremio-cli + Claude Code : piloter Dremio en langage naturel Dremio Cloud embarque désormais un CLI pensé pour être orchestré par un agent IA. Couplé aux skills Claude Code dédiés,... Lire la suite →
Passer à l'échelle Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons sécurisé notre plateforme : catalogue structuré, modèle de... Lire la suite →
Gouvernance et catalogue Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons construit l'architecture technique : le modèle médaillon, la... Lire la suite →
L'architecture lakehouse Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons posé les bases de la méthode : commencer petit,... Lire la suite →
Commencer petit Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons rappelé ce qu’est le Data Mesh en 2026. Aujourd'hui,... Lire la suite →