Ce site stocke des cookies sur votre ordinateur. Nous les utilisons afin de personnaliser votre expérience de navigation ainsi que pour des analyses d'audience.
Le Lakehouse moderne repose sur Apache Iceberg™, mais c’est le catalogue qui en détermine vraiment la puissance, l’ouverture… et le degré de dépendance à un fournisseur.Dans ce livre blanc, nous... Lire la suite →
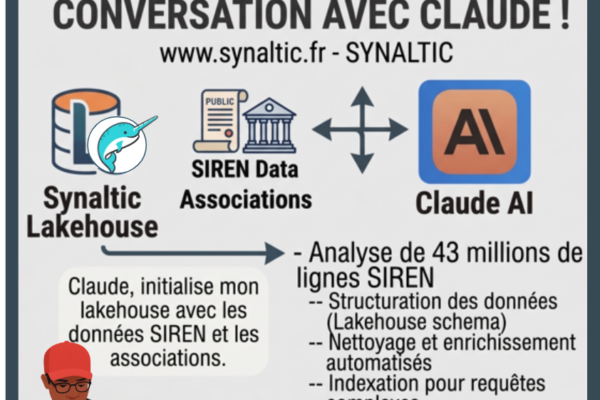
43 millions de lignes SIRENE : initialisation d'un lakehouse "associations" en une conversation avec Claude Et si construire un data lakehouse ne nécessitait plus de connaître par cœur la syntaxe... Lire la suite →
Passer à l'échelle Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons sécurisé notre plateforme : catalogue structuré, modèle de... Lire la suite →
Gouvernance et catalogue Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons construit l'architecture technique : le modèle médaillon, la... Lire la suite →
L'architecture lakehouse Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons posé les bases de la méthode : commencer petit,... Lire la suite →
Commencer petit Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l'article précédent, nous avons rappelé ce qu’est le Data Mesh en 2026. Aujourd'hui,... Lire la suite →
Pourquoi 2026 change la donne ! « Le Data Mesh ? Oui, on en a parlé, et puis on est passé à autre chose. » Cette réaction, nous l'entendons régulièrement... Lire la suite →
Nous avons exploré le paradoxe français, l'architecture révolutionnaire, et le ROI convaincant. Passons maintenant à la pratique : comment déployer concrètement une stack lakehouse moderne sur Kubernetes ? Cet épisode... Lire la suite →
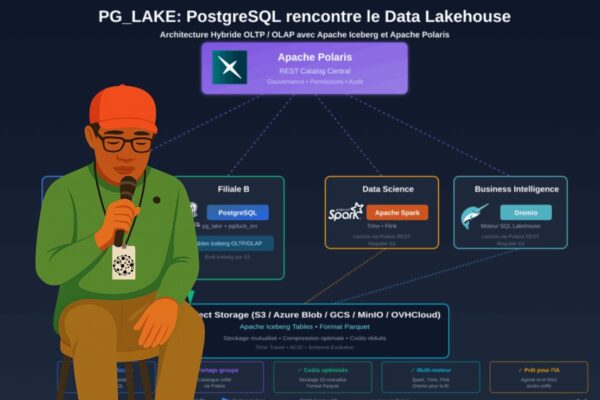
Qu'est-ce que PG_LAKE ? pg_lake est un ensemble d'extensions PostgreSQL open-source (Apache 2.0) qui transforme votre base de données PostgreSQL en une plateforme hybride OLTP/OLAP capable d'interagir nativement avec Apache... Lire la suite →