

Pourquoi 2026 change la donne !
« Le Data Mesh ? Oui, on en a parlé, et puis on est passé à autre chose. » Cette réaction, nous l’entendons régulièrement chez les décideurs français. Et pour cause : après l’engouement de 2020-2021, la phase de désillusion a fait son œuvre. Trop conceptuel. Trop organisationnel. Pas assez concret.
Pourtant, nous sommes en 2026. Et quelque chose a changé.
Le chaos a accouché de standards
Les trois dernières années ont bousculé les directions des systèmes d’information. L’IA générative d’abord, l’IA Agentique ensuite. L’explosion du nombre de solutions a souvent noyé les DSI : choisir une plateforme pour l’analytique et l’IA relève d’un vrai parcours du combattant.
Néanmoins, de ce chaos, des standards sont nés. Et il serait dommage de ne pas le reconnaître.
Apache Iceberg™ s’est imposé comme le format ouvert de référence. Les catalogues REST Apache Iceberg™ (IRC pour les intimes) permettent l’interopérabilité entre moteurs. Les architectures lakehouse ont prouvé leur pertinence. Ce qui manquait au Data Mesh existe désormais.
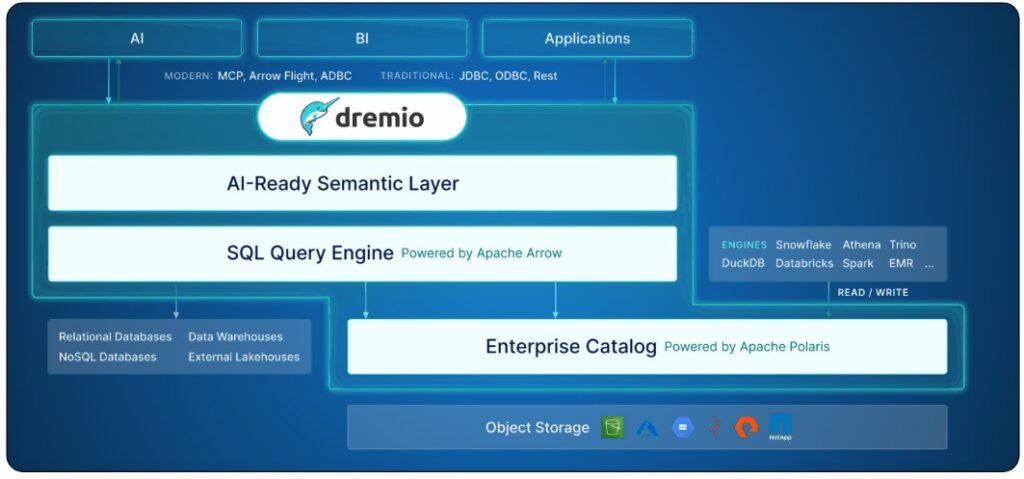
Afficher l’image Figure 1 : Dremio Agentic Lakehouse
La spécificité française : entre héritage et prudence
En France, nous avons une relation particulière avec les « Univers » de Business Objects. Après tout, c’est né ici, ce produit-là ! Cette culture de la couche sémantique, de l’intelligibilité des données pour les utilisateurs métier, nous l’avons dans l’ADN.
Dès 2020, nous parlions de Data Mesh sur le blog de Synaltic. À cette époque, nous étions peu à en comprendre l’impact réel. L’approche a connu sa médiatisation. Puis les critiques sont arrivées : trop ambitieux, trop déstabilisant pour les organisations.
Quoi qu’on en dise, le maillage des données constitue une vision d’entreprise de la consolidation de données à l’échelle de toutes les branches de l’organisation. Chez Synaltic, nous avons aidé nombre d’organisations dans la mise en œuvre de leurs data warehouses tout au long de ces 20 dernières années. Nous avons très tôt eu une approche agile pour ce type de projets. Nous avons rapidement préféré un découpage domaine par domaine, une livraison des artefacts qui suivait les principes du développement logiciel.
Force est de constater que tous ces principes et bonnes pratiques se retrouvent dans l’approche Data Mesh.
Ce que le Data Mesh change concrètement
Il faut avoir en tête une vision « holistique » d’un pareil projet. Ce dernier touche toute l’organisation.
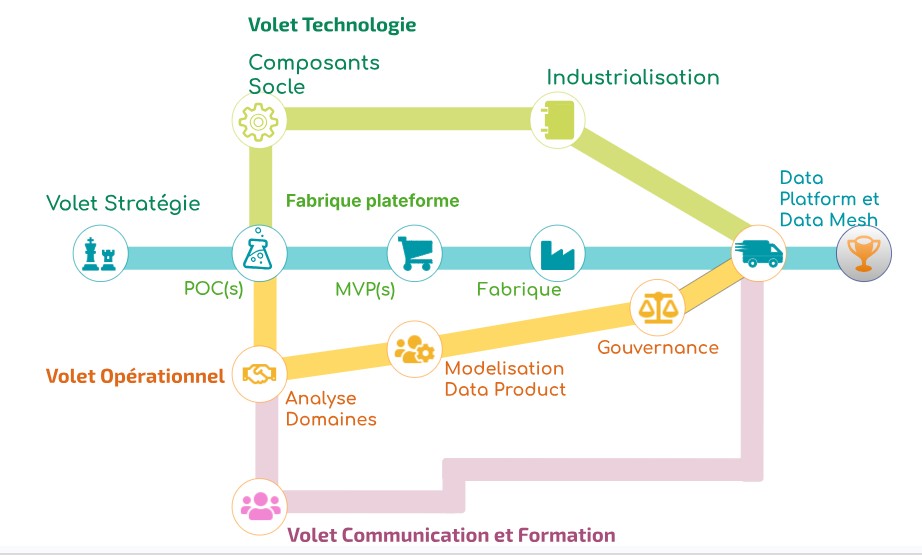
Figure 2 : Une feuille de route pragmatique du Data Mesh pour les organisations (Eric Broda – 2022)
Il est fort probable que l’on comprenne rapidement que ce projet va impliquer de nombreuses équipes. Il est tout aussi concevable qu’un modèle de données produit par une équipe, ou à un moment donné, soit utilisé pour tout ou partie afin de constituer un autre jeu de données, un autre produit de données.
Le maillage des données est palpable. Bien évidemment, dans les organisations de taille restreinte, il peut s’agir des mêmes personnes ! Néanmoins, le découpage par domaine demeure. Le fameux maillage prend forme.
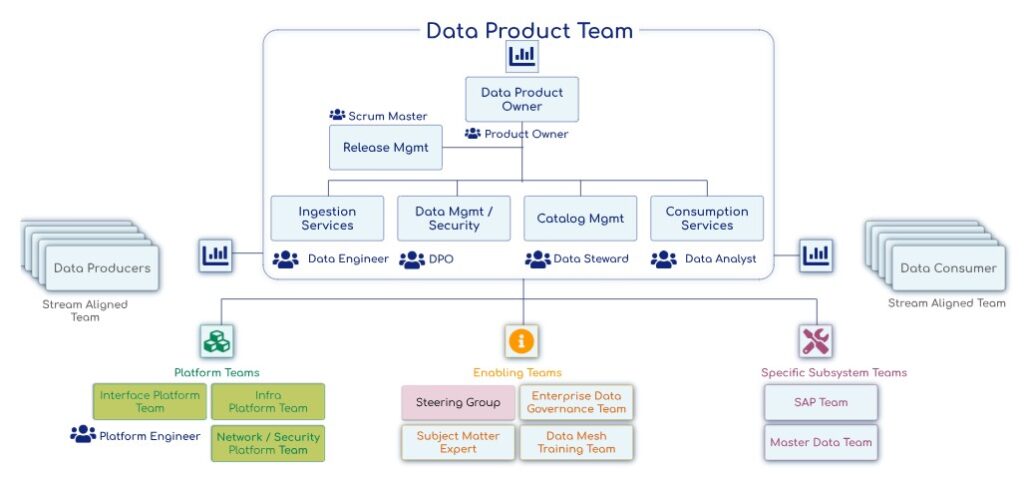
Figure 3 : Equipe Data Product (Eric Broda – 2022)
Centralisé ou décentralisé ? La vraie question
Toutes les organisations ont besoin de consolidation de données. Il est évident que toutes n’auront pas les mêmes approches.
Les organisations petites et moyennes ont souvent une DSI qui s’occupe de tout, et en plus avec peu de moyens : le schéma directeur, l’opérationnalisation de l’infrastructure, le support aux utilisateurs. Ils prennent aussi en charge l’échange de données entre les logiciels de gestion. C’est encore souvent eux qui gèrent la consolidation des données. Dans ce cas, bien sûr qu’une approche centralisée est la bonne manière d’aborder ce type de projets.
Dans les organisations plus larges, l’autonomie des équipes métier (avec des ingénieurs de données, des analystes, des data scientists à leur côté) favorise à la fois la cohésion autour des données et la vélocité des projets. La DSI garde l’infrastructure. Elle s’assure qu’un socle commun est fonctionnel. Elle s’assure aussi que toutes les équipes fonctionnent avec un cadre qui répond à tous les besoins en matière de gestion de données.
Ces éléments centraux portés par la DSI peuvent, eux aussi, faire l’objet d’une décentralisation progressive.
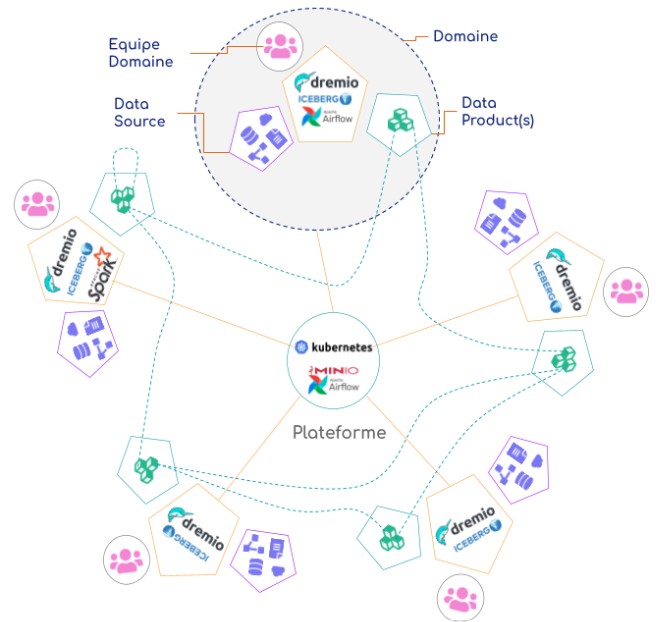
Figure 4 : Data Mesh : Équipes Data Product décentralisées, Équipe Plateforme centralisée
Pour le maillage des données, il est primordial de conserver une structure de partage sur laquelle tous les domaines s’accordent. C’est ici qu’Apache Iceberg™ prend son rôle : à la fois avec son format ouvert et avec son catalogue REST. Aujourd’hui, ce dernier est intégré au sein de nombreux moteurs et outils.
N’oubliez pas qu’Apache Iceberg™ sait tout autant servir la donnée à vos agents intelligents.
Ce qui vous attend dans cette série
Construire un projet de consolidation de données à l’échelle de l’organisation est un projet qui s’avère forcément complexe. S’assurer que tout le monde possède une culture de la donnée et que tout le monde soit aligné ? Rien que ça, vous pourriez mettre un temps certain à l’obtenir.
C’est pourquoi cette série va vous guider pas à pas :
- Article 2 vous donnera la méthode pour vous lancer
- Article 3 détaillera l’architecture technique avec Dremio et Apache Iceberg™
- Article 4 couvrira la gouvernance et le catalogue sans freiner vos équipes
- Article 5 vous montrera comment passer à l’échelle et mailler vos domaines
Une chose que nous avons apprise au cours de nos 20 ans, c’est la « fatigue » des systèmes… dit autrement, leur obsolescence : la fameuse dette technique. En posant vos fondations technologiques, vous savez déjà qu’à un moment donné vous devrez les faire évoluer. Vous devrez en changer.
La gouvernance, la gestion de la qualité, les automatisations, la culture de la donnée constituent des invariants que vous garderez, pour sûr, même après la mise en place de votre architecture.
Rendez-vous au prochain article pour découvrir comment vous lancer en commençant petit 🙂

Sections commentaires non disponible.