

Passer à l’échelle
Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l’article précédent, nous avons sécurisé notre plateforme : catalogue structuré, modèle de rôles, documentation accessible. Aujourd’hui, nous bouclons la boucle : comment passer du premier domaine réussi au véritable maillage des données à l’échelle de l’organisation ?
Vous y êtes ! Vous approchez votre tout premier modèle pour votre premier domaine. Qu’avez-vous appris ? Que retenez-vous ? Faites évoluer votre cadre. Vous pouvez poser les bases d’une industrialisation avec ce nouveau recul.
Profitez-en pour vérifier quel a été votre budget pour arriver à l’obtention de ce premier data product. Extrapolez et construisez votre budget pour vos prochains domaines.
Plus question de repartir de zéro
Ainsi, pour construire les nouveaux domaines, plus question de repartir de zéro ! Vous avez l’expérience du premier domaine. Vous avez même à votre disposition toutes les vues et tables de ce premier domaine.
Vous avez déjà bâti votre modèle pour gérer les « fournisseurs ». Ne recommencez pas un nouveau modèle. En effet, vous parlez bien du même concept.
C’est ici que le maillage prend tout son sens. Un modèle de données produit par une équipe, ou à un moment donné, peut être utilisé pour tout ou partie afin de constituer un autre jeu de données, un autre « Produit de données ».
Le maillage des données est palpable.
L’architecture multi-domaines
Un exemple d’architecture multi-domaines peut être vu dans l’image ci-dessous.
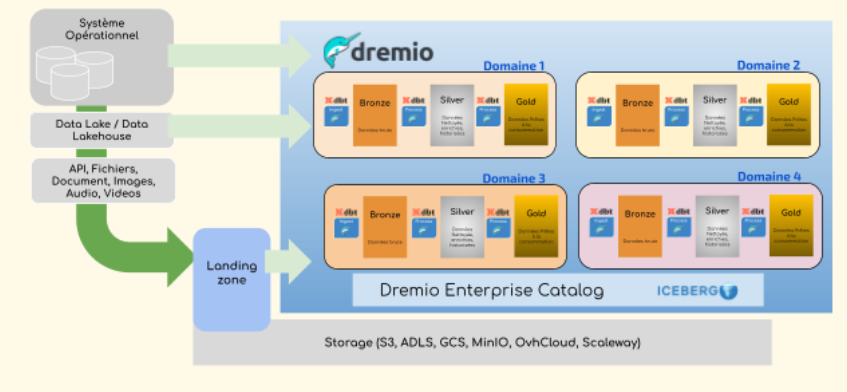
Figure 1 : Dremio Data Mesh avec DBT
Dremio propose carrément de gérer des données multimodales afin de pleinement rentabiliser votre lakehouse. Vous pouvez y héberger toutes vos données quel que soit leur type : vidéo, PDF, texte… Dremio a intégré des fonctionnalités basées sur l’IA afin de répondre à ces nouveaux enjeux.
- AI_GENERATE : Votre outil multifonction pour l’extraction de données complexes
- Pilier de notre suite de fonctions d’IA, AI_GENERATE offre un traitement flexible et polyvalent des données non structurées. Cette fonction excelle dans les tâches d’extraction complexes nécessitant de multiples champs structurés à partir de fichiers sources, vous permettant de transformer des PDF, des documents et des images en données interrogeables avec une facilité sans précédent.
- AI_COMPLETE : Génération et résumé intelligents de texte
- Spécialisée dans la génération de texte créative et le résumé intelligent, AI_COMPLETE renvoie des résultats VARCHAR parfaits pour générer des synthèses, créer des descriptions narratives ou produire des explications contextuelles des tendances de données.
- AI_CLASSIFY : Catégorisation simplifiée à grande échelle
- Conçue spécifiquement pour l’analyse des sentiments et la catégorisation des données, AI_CLASSIFY permet une classification rapide des données textuelles ou non structurées, renvoyant des résultats VARCHAR structurés qui s’intègrent parfaitement à vos flux de travail analytiques.
- LIST_FILES : Prise en charge du traitement des données non structurées
- Pour exploiter pleinement le potentiel de l’analyse basée sur l’IA, nous introduisons une fonctionnalité essentielle : la fonction LIST_FILES. Cette nouvelle fonctionnalité liste récursivement les fichiers des répertoires sources, permettant ainsi le traitement par lots des documents stockés dans votre lac de données.

Figure 2 : Dremio SQL Ai fonction
La question de la centralisation vs décentralisation reviendra. Vous observerez que l’autonomie des utilisateurs permettra de pousser la décentralisation toujours un cran plus loin. Pour chaque nouveau service, évaluez le besoin. Vous observerez une fois encore qu’il se trouve que nombre de modèles existent déjà.
Vous retirerez les POCs et autres MVPs afin cette fois d’aller plus loin dans l’autonomie des équipes et leur confier de nouvelles responsabilités.
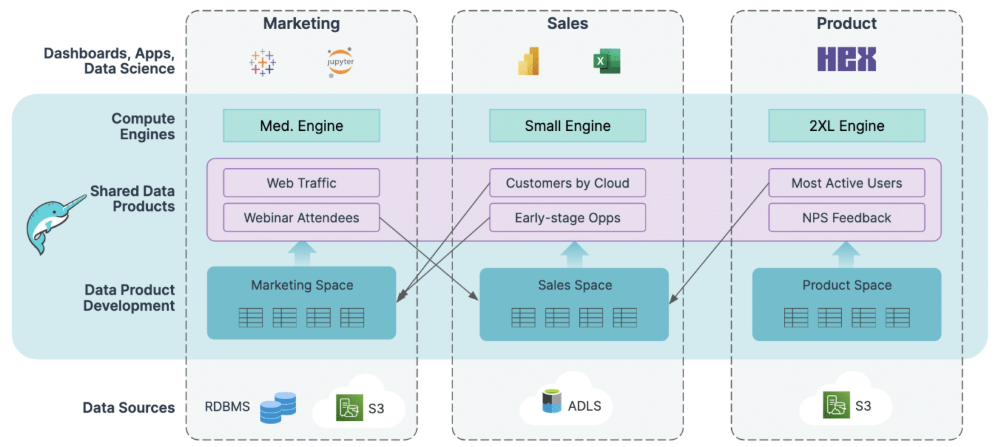
Figure 3 : Dremio Data Mesh Data Product
Industrialiser avec DBT
Bien sûr, vous devrez trouver des mécanismes pour industrialiser la livraison de vos modèles. Vous pouvez utiliser divers outils disponibles. DBT présente des avantages certains parce que Dremio maintient une extension DBT.
Synaltic vous propose différents articles sur le sujet. L’essentiel à retenir : vos transformations deviennent du code, versionné, testé, déployable automatiquement.
Votre couche Gold présente des vues très orientées métiers, définitivement prêtes à la consommation comme des datamarts (modèle aplati : One Big Table) ou encore des vues agrégées.
Suivre l’usage et anticiper les problèmes
Dremio vous met aussi différents outils à disposition afin de suivre l’utilisation qui est faite de la plateforme, la consommation des budgets, l’usage des ressources qui lui sont associées.
Vous pourrez être proactif afin de résoudre les problèmes avant que les utilisateurs n’aient le temps de se rendre compte.
Le zéro copie : l’avantage décisif de Dremio
Dremio présente un aspect singulier dans la gestion des données. Nombre d’acteurs prônent l’ETL ou l’ELT ! Dans les deux cas, il est question de copier la donnée.
Peu insistent sur ces mécanismes de vues pour exploiter aisément le modèle médaillon et les couches sémantiques. Avec une telle approche, Dremio réduit les délais des projets et les coûts qui y sont associés.
L’approche qui a été décrite dans cette série fait référence au livre de Piethein Strengholt Data Management at Scale. Si ce livre fait une large place à Data Factory de Microsoft, il ne présente pas les clés pour optimiser l’approche avec le zéro copie.
Gardez l’approche de Piethein Strengholt mais avec Dremio pour avoir une gestion de vos données bien plus optimale.
Ce que vous avez construit
Au fil de cette série, vous avez parcouru le chemin complet :
- Article 1 — Comprendre pourquoi 2026 change la donne : les standards sont là, l’infrastructure est mature
- Article 2 — Poser les bases : commencer petit, choisir le bon domaine, constituer la bonne équipe
- Article 3 — Construire l’architecture : Dremio, Apache Iceberg, le modèle médaillon
- Article 4 — Sécuriser sans freiner : gouvernance, catalogue, documentation
- Article 5 — Passer à l’échelle : réutilisation, industrialisation, perspectives
Vous n’êtes pas obligé de tout faire d’un coup. Chaque itération nourrit la suivante. Ce que nous aimons à répéter chez Synaltic, c’est que vous devez tout de même avoir la vision « holistique » du projet et de la plateforme. Parce qu’à chacune de vos itérations, vous vous rapprocherez un peu plus de la cible.
Vos perspectives
Une chose que nous avons apprise au cours de nos 20 années d’expérience, c’est la « fatigue » des systèmes — dit autrement, leur obsolescence : la fameuse dette technique. En posant vos fondations technologiques, vous savez déjà qu’à un moment donné vous devrez les faire évoluer. Vous devrez en changer.
La gouvernance, la gestion de la qualité, les automatisations, la culture de la donnée constituent des invariants que vous garderez, pour sûr, même après la mise en place de votre architecture et en ayant atteint des succès avec votre projet de data lakehouse.
Dremio, avec ses nouvelles fonctionnalités — à la fois basées sur l’IA et afin d’y répondre en même temps — se place tel le nouveau cœur de votre système de gestion des données.
N’oubliez pas qu’Apache Iceberg sait tout autant servir la donnée à vos agents intelligents.
Ce qu’il vous reste à faire
Vous avez maintenant une feuille de route claire. La méthodologie est posée. Les outils sont identifiés.
Chez Synaltic, nous accompagnons des organisations sur ces sujets depuis 20 ans. Nous avons très tôt eu une approche agile pour ce type de projets. Nous avons rapidement préféré un découpage domaine par domaine, une livraison des artefacts qui suivait les principes du développement logiciel.
Force est de constater que tous ces principes et bonnes pratiques se retrouvent dans l’approche Data Mesh.
Vous voulez explorer ce sujet pour votre organisation ? Parlons-en.

Sections commentaires non disponible.