
43 millions de lignes SIRENE : initialisation d’un lakehouse « associations » en une conversation avec Claude
Et si construire un data lakehouse ne nécessitait plus de connaître par cœur la syntaxe SQL de chaque moteur ? C’est ce que nous avons expérimenté chez Synaltic avec Dremio Cloud et Claude Code — sur des données ouvertes de l’INSEE, en une session de travail.
Le point de départ : un parquet, une idée
Un fichier StockEtablissement_utf8.parquet — le registre complet SIRENE de tous les établissements français, fourni par l’INSEE. 2 Go, 43,3 millions de lignes. L’objectif : construire un espace analytique autour du monde associatif français, de zéro, en architecture médaillon Bronze / Silver / Gold.
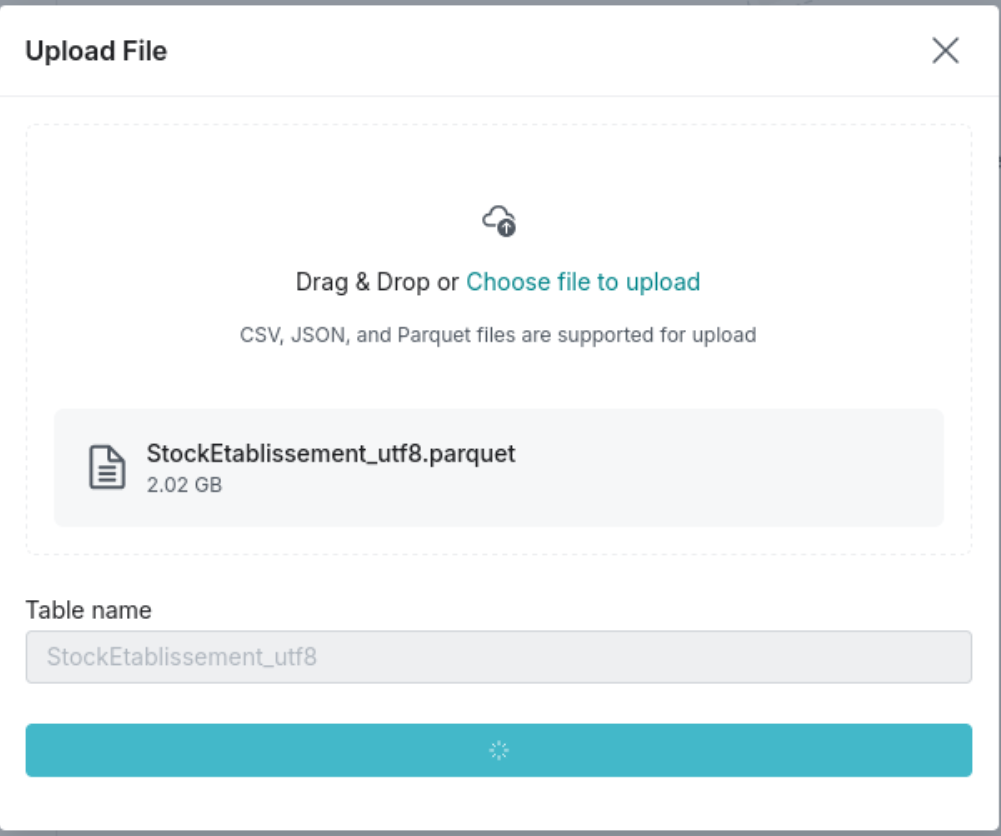
Upload du fichier SIRENE 2.02 Go dans Dremio Cloud Le fichier source est chargé en source connectée — Dremio en hérite automatiquement le schéma Parquet.
Premier échange avec Claude :
Plaintext"On travaille avec une architecture médaillon. Élabore selon les bonnes pratiques une structuration de tables Iceberg et de vues pour construire différentes analyses autour des associations. Propose d'abord le plan."
Retour immédiat : structure des couches, justification du filtre NAF 94xx pour isoler les associations, 6 vues analytiques identifiées avec leur grain et leur usage. Une conversation de planification qui remplace une réunion d’architecture.
Et voilà nous étions partis pour construire ces différentes tables.
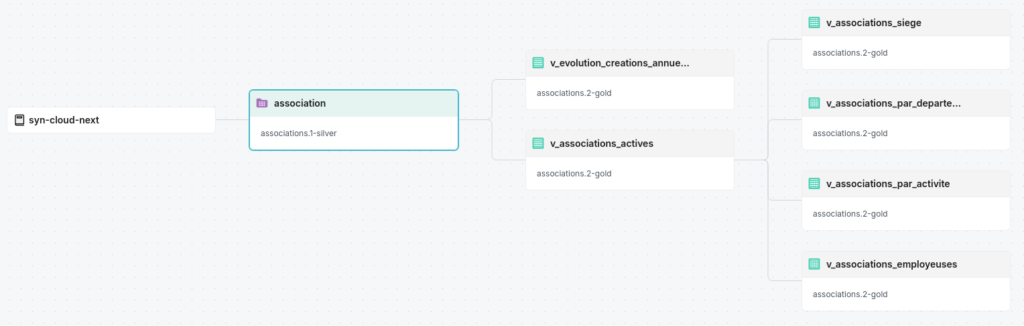
Bronze : l’ingestion sans friction
"Crée la table stg_etablissement dans 0-bronze depuis la source parquet."Claude génère le CREATE TABLE ... AS SELECT * avec deux colonnes d’audit (_ingested_at, _source_file). Il découvre en cours d’exécution que le chemin SQL du catalogue Dremio (associations."0-bronze") est différent du chemin API (syn-cloud-next.associations.0-bronze) — et corrige sans intervention.
Quand une valeur [ND] dans les coordonnées Lambert fait échouer le CAST, il identifie la valeur problématique, propose le CASE guard adapté, et relance.
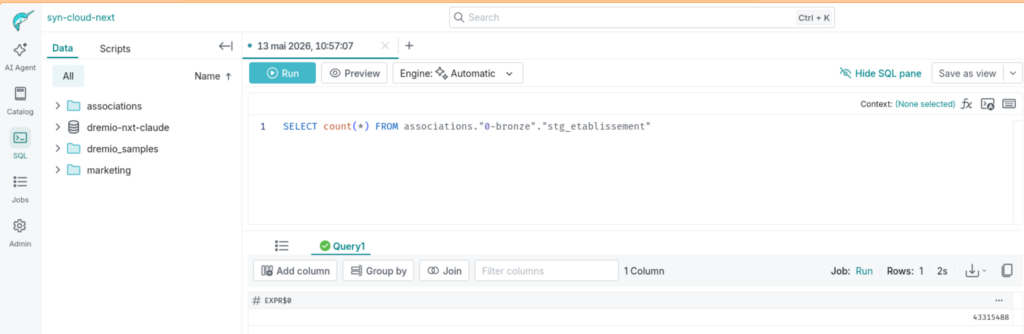
SQL editor — COUNT(*) = 43 315 488 dans la table bronze 43,3 millions de lignes ingérées en table Iceberg. La structure médaillon est déjà visible dans le catalogue à gauche.
Silver : nettoyage et focus métier
Deux tables Iceberg construites depuis Bronze :
etablissement— tous établissements, coordonnées Lambert castées enDOUBLE, colonnedepartementdérivée du code commune (Corse 2A/2B, DOM 97x/98x inclus)association— filtreLIKE '94%'sur le code NAF, 27 colonnes renommées en snake_case lisible
Résultat : 856 836 établissements associatifs isolés parmi 43 millions.
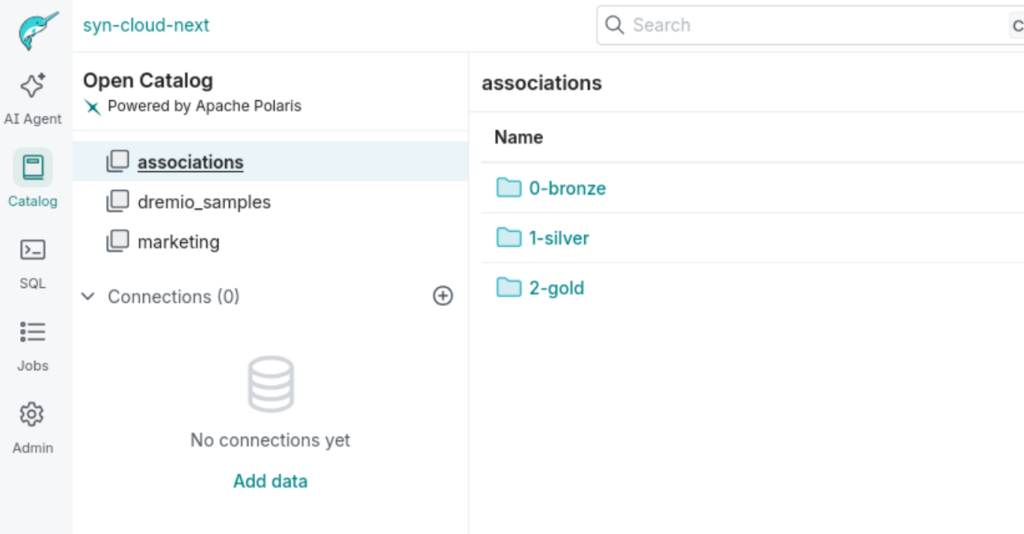
L’Open Catalog Apache Polaris reflète instantanément la structure créée par Claude via le CLI.
Gold : 6 vues analytiques prêtes à l’emploi
| Vue | Ce qu’elle révèle |
|---|---|
v_associations_actives | 677 020 associations en activité |
v_associations_par_departement | Paris (50 503), Bouches-du-Rhône, Nord en tête |
v_associations_par_activite | Distribution par code NAF 94xx |
v_associations_employeuses | Associations déclarant des salariés |
v_evolution_creations_annuelles | Courbe historique créations + taux de survie |
v_associations_siege | Référentiel siège — 1 ligne = 1 association |
Toutes construites en SQL pur sur v_associations_actives comme base commune — pas de stockage redondant, logique modifiable en un endroit.
Documentation : 9 objets documentés sans effort
"Documente les tables et vues créées via le wiki et les étiquettes."Le skill document-dataset a pris la main : description métier, colonnes clés avec types, lineage upstream/downstream, cas d’usage — puis dremio wiki update et dremio tag update sur chacun des 9 objets.
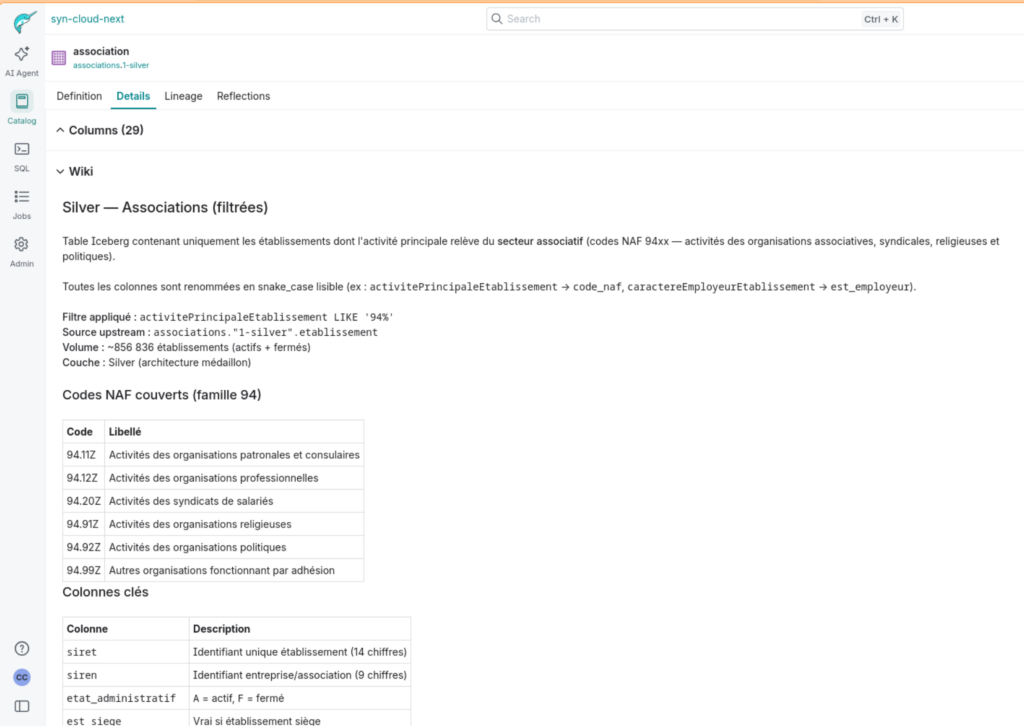
Wiki « Silver — Associations (filtrées) » visible dans l’interface Dremio Le wiki généré par Claude est immédiatement visible dans l’onglet Details du catalogue. Codes NAF, colonnes clés, lineage — tout y est
Et maintenant : l’AI Agent Dremio prend le relais
Une fois le lakehouse construit, les vues gold sont directement exploitables par l’AI Agent intégré à Dremio Cloud. Sans écrire une ligne de SQL :
"Montre moi l'évolution des associations depuis les années 60."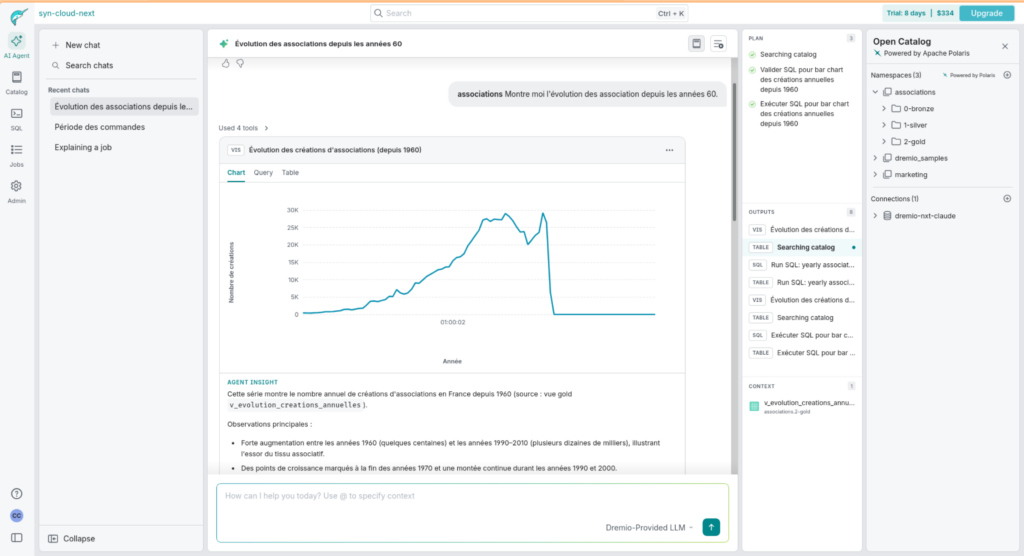
L’agent interroge `v_evolution_creations_annuelles`, génère le graphique, et commente : forte croissance dans les années 1990-2010, pic visible, reprise post-2020.
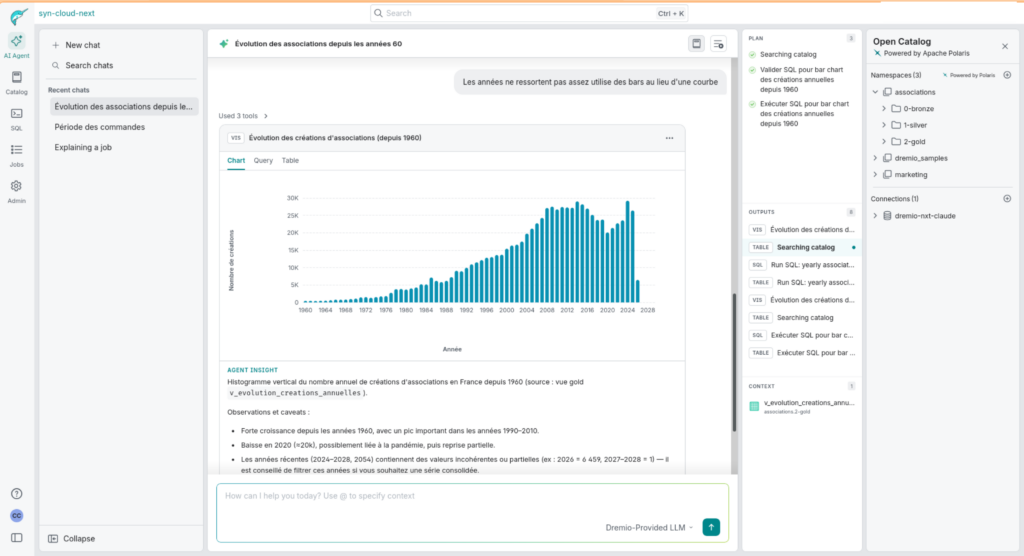
Il pousse l’analyse plus loin de lui-même — taux de survie par cohorte d’année de création :
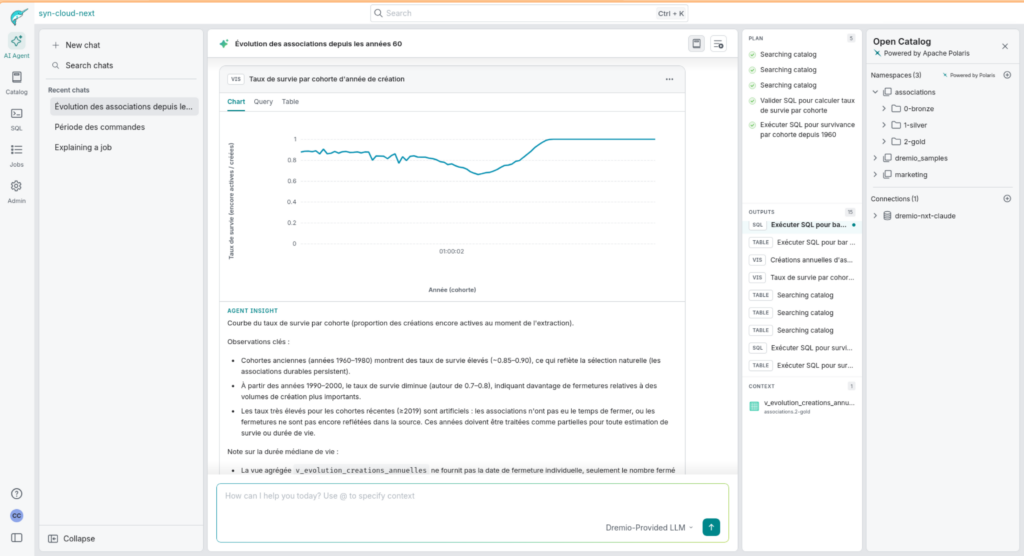
Les cohortes anciennes (1960-1990) affichent des taux de survie de 0,85-0,90. À partir des années 1990-2000, le taux diminue — davantage de fermetures relatives aux créations.
Le rôle de l’ingénieur de données évolue
La vraie valeur n’est pas que Claude écrit du SQL à notre place. C’est qu’il maintient le contexte de bout en bout : pourquoi le filtre est NAF 94xx, pourquoi les coordonnées sont en Lambert-93, pourquoi `v_evolution_creations_annuelles` pointe directement sur Silver plutôt que sur Gold. Le lakehouse est cohérent parce que la conversation l’est.
Les prochaines étapes naturelles ? Jointure avec le RNA (Répertoire National des Associations), reflections Dremio sur la table Silver pour accélérer les vues Gold, et cartographie des coordonnées Lambert déjà présentes.
Le projet data qui prenait une semaine prend maintenant une session.
Pour supprimer des emplois, il faudrait que l’IA ait déjà quelqu’un à remplacer. Toutes les organisations n’ont pas d’équipe data, ni de stratégie guidée par les données. C’est précisément là qu’un outil comme Dremio couplé à Claude change la donne : il rend la culture de la donnée accessible là où elle n’existait pas encore.
Pour le consultant ou le data ingénieur, le métier ne disparaît pas — il se déplace. Moins de temps sur l’exécution technique, plus de temps sur ce qui compte vraiment : comprendre le métier, bien spécifier, bien documenter. Le lakehouse, Claude le construit. L’analyse qu’il doit servir, c’est encore une affaire humaine.

Sections commentaires non disponible.