

Gouvernance et catalogue
Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l’article précédent, nous avons construit l’architecture technique : le modèle médaillon, la structure de la landing zone, les tables et vues Apache Iceberg™. Aujourd’hui, nous abordons un sujet que beaucoup redoutent : la gouvernance. Comment sécuriser vos données sans freiner vos équipes ?
Votre projet aura à peine commencé que vous serez assez vite confronté à la problématique de gestion des droits d’accès à la donnée. On arrive donc rapidement à l’organisation de notre catalogue de données.
La bonne nouvelle ? Avec Dremio et Apache Polaris™, la gouvernance n’est plus un frein. C’est un accélérateur.
Dremio Enterprise Catalog : cartographier toutes vos données
Dremio se base désormais sur Apache Polaris™ (précédemment Nessie).
Au sein d’Apache Polaris™, vous pouvez distinguer 3 niveaux :
Catalogue → Namespace → Table
Par exemple :
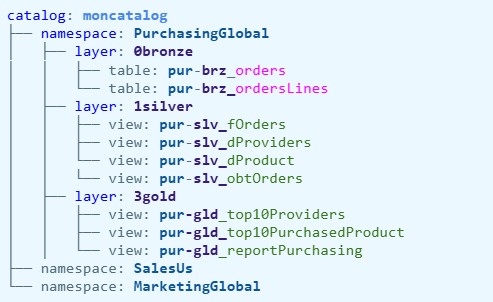
Cette structure vous permet d’organiser vos données par domaine métier tout en maintenant une cohérence globale. Chaque namespace correspond à un périmètre fonctionnel. Chaque couche (bronze, silver, gold) reste clairement identifiable.
Des utilisateurs nommés, pas seulement des comptes de service
Les tables sont accédées par des utilisateurs ! Nous vous recommandons d’avoir des utilisateurs nommés et non uniquement des comptes de services.
En effet, à l’heure des attaques cyber quotidiennes, mieux vaut prévenir que guérir. Nous vous invitons à mettre en place l’authentification unique (SSO).
Néanmoins, nous vous déconseillons d’appliquer des droits pour chaque utilisateur. C’est sans doute très chronophage. Bien sûr, le mieux consiste à exploiter les rôles dans Dremio et d’appliquer des droits d’accès via ces rôles — et non forcément à l’utilisateur.
Le modèle de rôles : qui accède à quoi ?
Analysez uniquement les domaines qui font partie de votre projet. Intégrez un domaine à la fois, l’un après l’autre. Divisez et regroupez vos sources de données au sein de la plateforme de manière logique.
Le point clé ici est que chaque actif de chaque source de données ou application ne peut être stocké que dans un seul emplacement de votre catalogue. Nous vous déconseillons de dupliquer la donnée. Attention aux phases de maintenance qui ne seraient alors pas si simples. Par contre, fédérez les données, adoptez le maillage des données. Pensez bien que vous pouvez dériver un jeu de données à partir d’un autre avec les vues (au lieu de copier les données).
Par la suite, vous distinguez différents types ou grands types d’utilisateurs :
- Administrateurs des sources (landing zone, sous-répertoire au sein de la landing zone) — Ils ont accès en lecture / écriture à la source.
- Data ingénieurs — Ils ont un accès en lecture aux sources de données et en lecture / écriture pour la couche bronze et la couche silver.
- Analystes — Ils ont accès en lecture sur la couche silver et en lecture / écriture sur la couche gold.
- Utilisateurs finaux — Accès en lecture à la couche gold uniquement.
Bien sûr, dans les structures ramassées, cela peut être le même data ingénieur pour tous ces rôles.
Apache Polaris™ sait nous aider à gérer les différents groupes à associer aux catalogues, espaces de noms et aux dossiers.
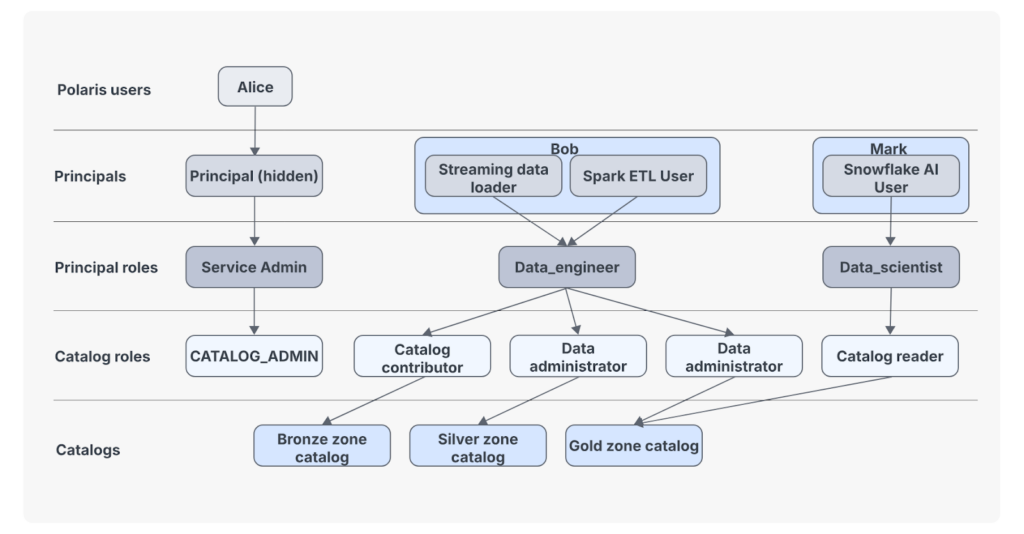
Figure 1 : Modèle de rôles et droits d’accès avec Apache Polaris™
Gérer les droits : SQL ou interface graphique ?
Depuis Dremio, vous pouvez aussi bien gérer ces droits via SQL ou via l’interface graphique.
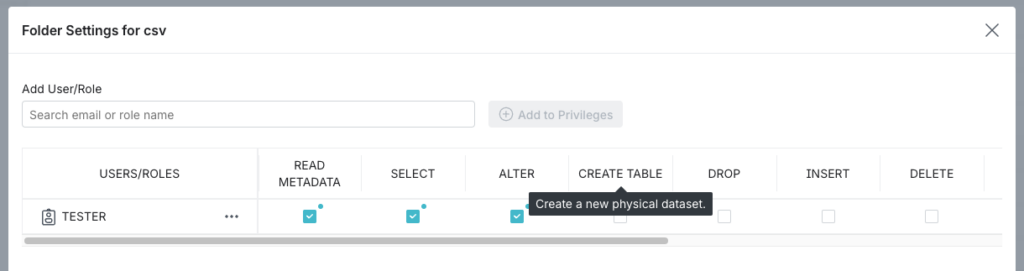
Figure 2 : Gestion des droits via l’interface graphique de Dremio
Bien que l’interface graphique présente un aspect convivial, privilégiez les commandes SQL afin de pouvoir les répéter au sein de vos différents environnements.
C’est un point que nous ne cessons de répéter chez Synaltic : ce qui peut être scripté doit être scripté. Vos configurations de sécurité font partie de votre code. Elles doivent être versionnées, rejouables, auditables.
Se connecter à votre fournisseur d’identité
Pour aller plus loin, Dremio présente des connexions vers les services d’authentification unique. Nous vous invitons fortement à vous y connecter.
Par exemple, gérez les utilisateurs et les groupes au niveau de votre annuaire ou votre fournisseur d’identité. Vous ne gérerez alors au niveau de Dremio que la gestion des droits.
Remarque importante :
Si vous possédez des solutions d’informatique décisionnelle, vous devrez redéfinir les accès aux tableaux de bord et aux rapports. Une authentification unique permet une gestion de la sécurité de bout en bout : tant au niveau du logiciel décisionnel qu’au niveau de Dremio.
Le volet socialisation : communiquer pour faire adopter
Finalement, ici nous avons largement évoqué la gouvernance. Cette phase est cruciale et devra faire l’objet de communication auprès des utilisateurs.
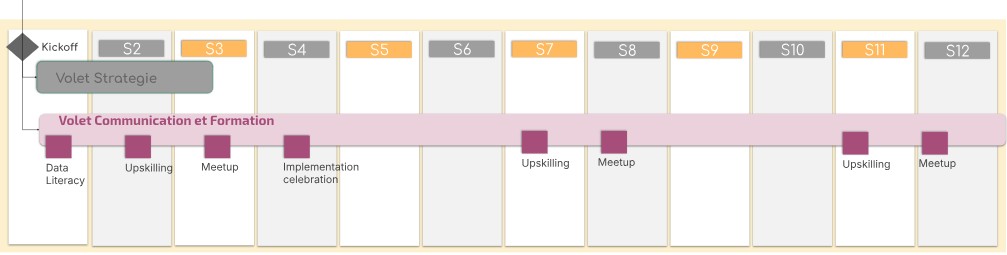
Figure 3 : Feuille de Route Data Mesh – volet « Socialisation » (Eric Broda – 2022)
Tout au long du projet, communiquez les avancées aux utilisateurs. Ayez un rythme régulier pour vos animations. N’hésitez pas à adopter les rites et coutumes des communautés open source avec des réunions informelles comme les meetups… voire des modèles de réunions plus anciens comme les hackathons ou plus anciens encore les barcamps.
De même, n’ignorez pas les formations, la documentation avec une large couverture — pourquoi pas un blog ? Forts de connaissances, l’utilisateur s’inscrit mieux dans les processus. Il est valorisé. Il est engagé.
Documenter pour les humains… et pour les machines
Les utilisateurs ayant les autorisations peuvent identifier des tables, des vues dont ils vont pouvoir se saisir afin de construire leurs modèles, leurs vues personnalisées.
Dremio présente l’avantage de pouvoir à la fois fédérer vos données et offir une interface graphique conviviale. Vos utilisateurs peuvent chercher dans tout le catalogue.
Figure 4 : Dremio Semantic Search
Les utilisateurs ont accès à la documentation pour les différents jeux de données. Et Dremio sait tirer parti d’une telle documentation via la recherche — ou exploitable via les IA.
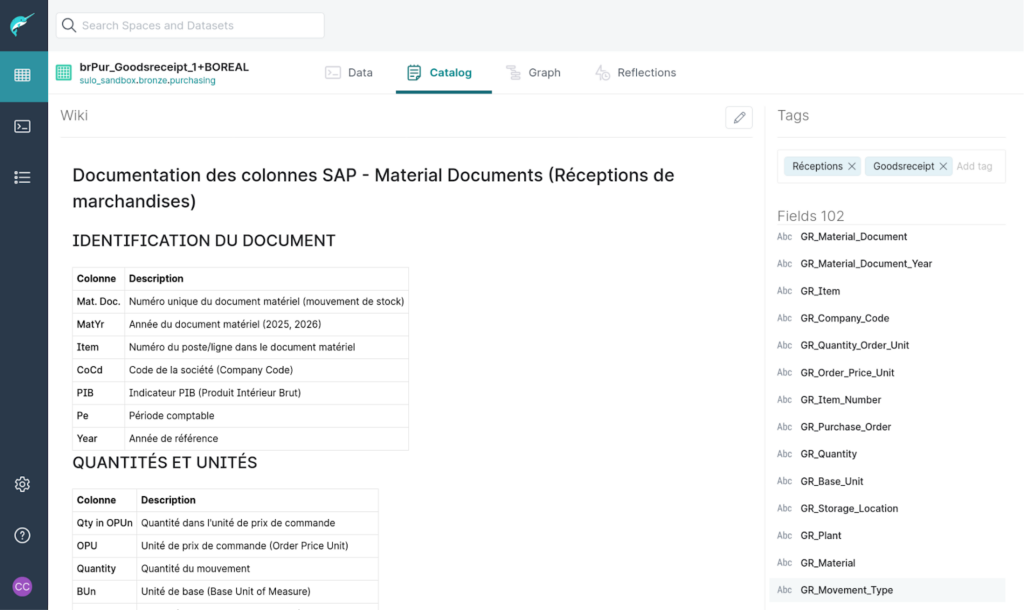
Figure 17 : Dremio Catalog Wiki
L’accessibilité des données passe par le sens qu’on leur donne — pour les humains, et pour les machines aussi. Aujourd’hui, quand vous définissez une table « client », une table « produit », le sens joue pour beaucoup dans l’appropriation de ces tables et de leurs contenus.
Modéliser la donnée, certes pour une interrogation performante, mais surtout pour une appropriation instantanée par l’humain — et désormais pour la machine — prend une toute nouvelle dimension. Cela renforce l’utilité d’une donnée répondant directement au sens, à la sémantique.
Ce que vous avez maintenant
À ce stade, vous avez :
- Une architecture lakehouse fonctionnelle (article 3)
- Un catalogue structuré par domaines et par couches
- Un modèle de rôles clair et maintenable
- Une connexion à votre fournisseur d’identité
- Une documentation accessible à tous
De même, vous pourriez avoir besoin de gérer des métadonnées sur vos flux, pour suivre la qualité des données. Vous pouvez par exemple gérer un domaine « système » afin de gérer ce type de besoins.
Vous êtes prêts pour le maillage des données !
Ainsi, pour construire les nouveaux domaines, plus question de repartir de zéro ! Vous avez l’expérience du premier domaine. Vous avez même à votre disposition toutes les vues et tables de ce premier domaine. Vous avez déjà bâti votre modèle pour gérer les « fournisseurs ». Ne recommencez pas un nouveau modèle. En effet, vous parlez bien du même concept.
Rendez-vous au prochain article pour découvrir comment passer à l’échelle : architecture multi-domaines, réutilisation des modèles, et perspectives avec l’IA.

Sections commentaires non disponible.