

Guide des Reflections
Types | Cas d’usage | Règles | Exemples SQL
| Qu’est-ce qu’une Reflection ? Une Reflection est un jeu de données pré-calculé et stocké en format colonnaire (Parquet/Arrow) que Dremio utilise automatiquement pour accélérer les requêtes SQL. L’utilisateur écrit son SQL normalement — Dremio redirige la requête vers la Reflection sans aucune modification du code. |
Sommaire
1.Les Deux Type de Reflections
1.1 Raw Reflection (Reflection Brute)
1.2 Aggregation Reflection (Reflection d’Agrégation)
1.3 Tableau Comparatif
2. Règles de Configuration
2.1 Règles de Matching — Quand Dremio active une Reflection
2.2 Règles de Refresh
2.3 Règles de Partitionnement, Tri et Distribution
3. Cas d’Usage Détaillées
Cas 1 — Dashboard analytique sur table de transactions
Cas 2 — Export de données brutes vers Excel / CSV
Cas 3 — Remplacement d’un filtre IN() long par une JOINT
Cas 4 — Multi-Reflections sur un même Dataset
4. Lire un Profil de Requête Dremio
4.1 Champs de l’accélération Profile
4.2 Profil : Reflection Activée
4.3 Profil : Reflection Non Activée — Diagnostic
5. Erreurs Fréquentes et Checklist
5.1 Erreurs à Éviter
5.2 Checklist de Creation
5.3 Les 5 Règles d’Or
1. Les Deux Types de Reflections
Dremio propose deux types de Reflections complémentaires. Le choix dépend uniquement de la nature des requêtes à accélérer.
1.1 Raw Reflection (Reflection Brute)
Une Raw Reflection est une copie optimisée de la table source en format colonnaire, sans aucune transformation ni agrégation. Toutes les lignes sont conservées.
Quand utiliser une Raw Reflection ?
- La requête ramène toutes les colonnes d’une table (SELECT *)
- La source est lente ou distante : fichiers HDFS, S3, base relationnelle PostgreSQL / Oracle / MySQL
- Les requêtes effectuent des jointures entre grandes tables sans agregation
- Les utilisateurs font des exports de données brutes (CSV, Excel, outils tiers)
- Les filtres WHERE sont variables d’une requête à l’autre (colonnes changeantes)
Exemple 1 — Accélérer un export de commandes depuis S3
Contexte : une table de commandes stockée en JSON sur S3, 200 millions de lignes, exportée chaque semaine par plusieurs équipes.
Requête utilisateur
SELECT
order_id,
customer_id,
order_date,
product_id,
product_name,
quantity,
unit_price,
total_amount,
status,
region
FROM s3_catalog.sales.orders
WHERE order_date >= '2024-01-01'
AND region = 'EUROPE'
ORDER BY order_date DESCConfiguration de la Raw Reflection
-- Dans l'interface Dremio : onglet "Reflections" du dataset
s3_catalog.sales.orders
-- Type : Raw Reflection
-- Nom : raw_orders_europe
-- Display (colonnes incluses dans la Reflection) :
-- order_id, customer_id, order_date, product_id, product_name,
-- quantity, unit_price, total_amount, status, region, country, city
-- Partition by : YEAR(order_date) <- une partition par annee
-- Sort by : order_date, region <- pre-tri sur les colonnes de filtre
-- Refresh schedule : Toutes les nuits a 02h00
-- TTL : 25 heures
| Résultat mesure Avant Reflection : 8 minutes (scan complet JSON S3, 200M lignes) Apres Reflection : 25 secondes (lecture Parquet partitionne sur 2024) Gain : x20 | Seule la partition 2024 est lue (partition pruning) Profil Dremio : accelerated = true |
Exemple 2 — Cache d’une base relationnelle PostgreSQL
Contexte : les équipes interrogent une base PostgreSQL de production via Dremio. Chaque requête charge la base. Objectif zéro connexion directe sur PostgreSQL.
-- Sur le dataset "postgres_src.public.customers" :
-- Type : Raw Reflection
-- Nom : raw_customers_cache
-- Display : toutes les colonnes
-- Partition by : country_code
-- Refresh : toutes les heures
-- TTL : 65 minutes
-- Après configuration, cette requête est servie depuis Dremio, pas depuis Postgres :
SELECT
c.customer_id,
c.first_name,
c.last_name,
c.email,
c.country_code,
c.signup_date,
c.segment
FROM postgres_src.public.customers c
WHERE c.country_code = 'FR'
AND c.segment = 'PREMIUM'1.2 Aggregation Reflection (Reflection d’Agrégation)
Une Agrégation Reflection pré-calcule des résultats agrégés (SUM, COUNT, AVG, MIN, MAX, COUNT DISTINCT) sur des dimensions définies. Dremio répond aux requêtes d’analyse directement depuis ces agrégats, sans toucher à la table source.
Quand utiliser une Agrégation Reflection ?
- Les requêtes contiennent des GROUP BY et des fonctions d’agrégation
- Les requêtes contiennent uniquement des fonctions d’agrégation sans GROUP BY (ex: COUNT(*),
SUM(montant), AVG(prix) sur toute la table) - Les dashboards BI (Tableau, Power BI, Qlik, Métabase…) chargent des métriques résumés
- Les mêmes calculs agrégés sont répétés par de nombreux utilisateurs simultanément
- La table source est très volumineuse et les agrégats la réduisent de 95 à 99%
Exemple 3 — Dashboard de ventes par région et catégorie
Contexte : un dashboard charge 100 fois par jour. Il effectue des GROUP BY sur une table de transactions de 500 millions de lignes. Temps de réponse initial 2 minutes.
Requête envoyée par l’outil BI
SELECT
YEAR(sale_date) AS annee,
MONTH(sale_date) AS mois,
region,
country,
product_category,
product_subcategory,
SUM(revenue) AS ca_total,
SUM(quantity_sold) AS qte_totale,
COUNT(DISTINCT order_id) AS nb_commandes,
AVG(revenue) AS panier_moyen
FROM hdfs_catalog.sales.transactions
WHERE YEAR(sale_date) IN (2023, 2024)
GROUP BY
YEAR(sale_date), MONTH(sale_date),
region, country,
product_category, product_subcategory
ORDER BY ca_total DESCConfiguration de l’Agrégation Reflection
-- Dans l'interface Dremio : onglet "Reflections" du dataset hdfs_catalog.sales.transactions
-- Type : Aggregation Reflection
-- Nom : agg_sales_region_category
-- Dimensions (= colonnes du GROUP BY) :
-- sale_date, region, country, product_category,
-- product_subcategory, channel, store_id, salesperson_id
-- Measures (= fonctions d'agrégation pré-calculées) :
-- revenue -> SUM, MIN, MAX, AVG
-- quantity_sold -> SUM
-- order_id -> COUNT DISTINCT
-- margin -> SUM, AVG
-- Partition by : YEAR(sale_date)
-- Refresh schedule : Quotidien à 03h00 (après ETL 02h30)
-- TTL : 25 heures
| Résultat mesure Avant Reflection : 2 minutes (GROUP BY sur 500M lignes HDFS) Apres Reflection : 0.6 seconde (lecture des agrégats pre-calcules) Gain : x200 | Volume Reflection : ~500 000 lignes (au lieu de 500M)100 utilisateurs servis simultanément sans dégradation |
1.3 Tableau Comparatif
| Critère | Raw Reflection |
|---|---|
| Type de données | Toutes les lignes, non agrégés |
| Agrégation | Aucune |
| Cas d’usage principal | SELECT *, export, jointures |
| Volume stocke | 100% de la source |
| Gain typique | x5 a x30 |
| Outils BI | Compatible mais non optimal |
| Colonnes obligatoires | Toutes les colonnes du SELECT |
| Critère | Aggregation Reflection |
|---|---|
| Type de données | Agrégats pre-calcules |
| Agrégation | SUM, COUNT, AVG, MIN, MAX, COUNT DISTINCT |
| Cas d’usage principal | Dashboards, KPI, rapports périodiques |
| Volume stocké | Réduit de 90 à 99% |
| Gain typique | x50 a x1000 |
| Outils BI | Ideal (Tableau, Power BI, Qlik) |
| Colonnes obligatoires | Dimensions = GROUP BY | Measures = fonctions |
2. Règles de Configuration
2.1 Règles de Matching — Quand Dremio active une Reflection
Pour qu’une Réflexion soit utilisée automatiquement, toutes les conditions suivantes doivent être réunies au moment de la requête.
Conditions communes aux deux types
- Statut DONE : la Reflection a terminé son dernier refresh (pas en cours, pas FAILED)
- TTL non expiré : la Reflection n’a pas dépassé sa durée de vie configurée
- Toutes les colonnes du SELECT sont présentes dans la Reflection
- Les filtres WHERE peuvent etre evalues sur les colonnes disponibles dans la Reflection
Conditions spécifiques à une Agrégation Reflection
- Chaque colonne du GROUP BY est déclarée comme Dimension dans la Reflection
- Chaque fonction agrégée du SELECT (SUM, COUNT…) est déclarée comme Measure
- Le HAVING peut être évalué sur les Dimensions et Mesures existantes
Causes les plus fréquentes d’échec de matching
- Clause IN() avec une liste très longue : WHERE id IN (val 1,…,val 500) empêche la normalisation du plan. Solution : remplacer par une JOINT.
- Colonne absente de la Réflection : une seule colonne manquante dans Display/Dimensions force le retour à la source.
- Expression calculée non matérialisée : SELECT prix * 1.2 AS ttc si cette expression n’est pas dans la Reflection.
- Reflection en cours de refresh : Dremio retombe sur la source pendant le refresh.
Exemple — IN() long vs JOIN : impact sur la Reflection
Un filtre avec une longue liste de valeurs IN() est l’une des causes les plus fréquentes de non-utilisation d’une Reflection.
AVANT (sans Reflection)
-- IN(500 valeurs) : matching echoue
-- millisTakenSubstituting = 1500ms+
-- accelerated = FALSE
SELECT
product_id,
SUM(revenue) AS ca
FROM sales.transactions
WHERE YEAR(sale_date) = 2024
AND product_id IN (
'P001','P002','P003',
'P004','P005','P006',
-- ... 500 valeurs ...
'P999'
)
GROUP BY product_id
APRES (avec Reflection)
-- JOIN : matching reussi
-- millisTakenSubstituting < 80ms
-- accelerated = TRUE
-- Etape 1 : creer table de filtrage
-- CREATE TABLE ref.selected_products
-- (product_id VARCHAR(10));
SELECT
t.product_id,
SUM(t.revenue) AS ca
FROM sales.transactions t
INNER JOIN ref.selected_products sp
ON t.product_id = sp.product_id
WHERE YEAR(t.sale_date) = 2024
GROUP BY t.product_id
2.2 Règles de Refresh
| Mode | Quand l’utiliser |
|---|---|
| Manuel (Neuer Refresh) | Données historiques figées, jamais mises à jour. À éviter en production. |
| Scheduled (Planifie) | Recommandé. Aligner l’heure de refresh sur la fin de l’ETL source. |
| Incremental Refresh | Table avec colonne date/croissant. Refresh partiel, très rapide. Idéal pour les grandes tables. |
| Full Refresh | Après un changement de schéma, de logique métier, ou si la table source contient des mises à jour/suppressions. Planifier hors heures de pointe. |
Règle du TTL — éviter les gaps
Le TTL (Time To Live) définit combien de temps une Reflection reste valide. Si le TTL expire avant le prochain refresh, Dremio retombe sur la source.
-- Bonne configuration (pas de gap) :
-- Refresh planifie : toutes les 24h a 03h00
-- TTL : 25 heures <- toujours valide quand le refresh arrive
-- Mauvaise configuration (gap possible) :
-- Refresh planifie : toutes les 24h a 03h00
-- TTL : 20 heures <- Reflection expiree a 23h00, gap de 4h
2.3 Règles de Partitionnement, Tri et Distribution
| Option | Usage recommandé |
|---|---|
| Partition by | Colonnes de filtrage temporel (année, mois) ou catégorique basse cardinalité (pays, région). Maximum 4 colonnes. |
| Sort by | Colonnes de filtres récurrents (ORDER BY, jointures). Accélère la recherche et le tri. |
| Distribution by | Jointures entre deux Reflections volumineuses. Utiliser la même colonne des deux côtés. |
| Display (Raw) | Toutes les colonnes utilisées dans SELECT, WHERE, JOIN. Sans elles, la Reflection n’est pas utilisée. |
Exemple — Partitionnement pour requêtes temporelles
-- Raw Reflection sur une table de logs applicatifs (1 milliard de lignes) :
-- Partition by : YEAR(event_date) <- une partition par annee
-- Sort by : event_date, user_id <- pre-tri pour filtres frequents
-- Requete qui beneficie du partition pruning (seule l'annee 2024 est lue) :
SELECT event_id, user_id, event_type, event_date, payload
FROM app_catalog.logs.events
WHERE event_date BETWEEN '2024-01-01' AND '2024-06-30'
AND event_type = 'LOGIN'
-- Requete qui NE beneficie PAS du pruning (filtre sur colonne non partitionnée) :
SELECT event_id, user_id, event_type, event_date
FROM app_catalog.logs.events
WHERE user_id = 'U12345' -- pas de pruning : scan de toutes les partitions3. Cas d’Usage Détaillées
Cas 1 — Dashboard analytique sur table de transactions
| Contexte | Dashboard charge 80 fois/jour. GROUP BY sur 500M lignes. Temps de réponse : 2 minutes. |
| Solution | Aggregation Reflection avec toutes les dimensions du dashboard et les mesures nécessaires. |
| Résultat | 0.6 seconde. Gain x200. 80 utilisateurs simultanément sans dégradation de performance. |
SQL du dashboard (inchangé)
SELECT
YEAR(sale_date) AS annee,
MONTH(sale_date) AS mois,
region,
product_category,
SUM(revenue) AS ca_total,
COUNT(DISTINCT order_id) AS nb_commandes,
AVG(revenue) AS panier_moyen
FROM hdfs_catalog.sales.transactions
WHERE YEAR(sale_date) = 2024
GROUP BY YEAR(sale_date), MONTH(sale_date), region, product_categoryConfiguration de la Reflection
-- Aggregation Reflection : agg_sales_monthly_dashboard
-- Dimensions : sale_date, region, country, product_category,
-- product_subcategory, channel, store_id
-- Measures : revenue (SUM, MIN, MAX, AVG),
-- order_id (COUNT DISTINCT),
-- quantity_sold (SUM), margin (SUM)
-- Partition : YEAR(sale_date)
-- Refresh : Quotidien a 03h00
-- TTL : 25 heuresCas 2 — Export de données brutes vers Excel / CSV
| Contexte | Export hebdomadaire de 5M lignes depuis une table HDFS JSON. Temps initial : 12 minutes. |
| Solution | Raw Reflection avec toutes les colonnes, partitionnée par année, triée par date. |
| Résultat | 45 secondes. Gain x16. Seule la partition de l’année courante est lue. |
SQL d’export (inchangé)
SELECT
order_id,
customer_id,
customer_name,
order_date,
product_id,
product_name,
category,
quantity,
unit_price,
total_amount,
discount_pct,
status,
shipping_address,
delivery_date
FROM hdfs_catalog.sales.orders
WHERE order_date >= '2024-01-01'
ORDER BY order_date, customer_idConfiguration de la Reflection
-- Raw Reflection : raw_orders_full_export
-- Display : toutes les colonnes (order_id, customer_id, customer_name,
-- order_date, product_id, product_name, category,
-- quantity, unit_price, total_amount, discount_pct,
-- status, shipping_address, delivery_date, region, country)
-- Partition : YEAR(order_date)
-- Sort : order_date, customer_id
-- Refresh : Quotidien a 01h00
-- TTL : 25 heuresCas 3 — Remplacement d’un filtre IN() long par une JOINT
| Contexte | Requête avec WHERE product_id IN (500 valeurs). Reflection existante non utilisée. 3 minutes. |
| Solution | Créer une table de référence des IDs cibles. Remplacer IN() par une INNER JOIN. |
| Résultat | 4 secondes. Reflection activée. millisTakenSubstituting passe de 1500ms à 60ms. |
Etape 1 — Créer la table de référence
-- Creer une table de reference dans un espace Dremio (ou via ETL)
CREATE TABLE "$scratch".ref_selected_products (
product_id VARCHAR(20),
selection_label VARCHAR(100)
);
-- Alimenter depuis votre source de reference :
INSERT INTO "$scratch".ref_selected_products
SELECT DISTINCT product_id, 'SELECTION_2024'
FROM catalog.ref.product_selection
WHERE campaign_id = 'CAMP_2024_Q1';Etape 2 — Modifier la requête
-- AVANT : IN(500 valeurs) -> accelerated = false
SELECT
t.product_id,
t.product_name,
SUM(t.revenue) AS ca,
COUNT(DISTINCT t.order_id) AS nb_commandes
FROM sales.transactions t
WHERE YEAR(t.sale_date) = 2024
AND t.product_id IN ('P001','P002','P003', ... , 'P500')
GROUP BY t.product_id, t.product_name
-- APRES : JOIN -> accelerated = true
SELECT
t.product_id,
t.product_name,
SUM(t.revenue) AS ca,
COUNT(DISTINCT t.order_id) AS nb_commandes
FROM sales.transactions t
INNER JOIN "$scratch".ref_selected_products sp
ON t.product_id = sp.product_id
WHERE YEAR(t.sale_date) = 2024
GROUP BY t.product_id, t.product_nameCas 4 — Multi-Reflections sur un même Dataset
Il est possible et recommandé de créer plusieurs Reflections sur le même dataset. Dremio choisit automatiquement la plus adaptée à chaque requête entrante.
-- Sur le dataset hdfs_catalog.sales.transactions, on crée 3 Reflections :
-- Reflection 1 : Raw (exports et requêtes ad-hoc)
-- raw_transactions_all_columns
-- Display : toutes les colonnes
-- Partition : YEAR(sale_date)
-- Sort : sale_date, region
-- Reflection 2 : Aggregation (dashboard mensuel par région/catégorie)
-- agg_sales_monthly_region
-- Dimensions : sale_date, region, country, product_category, channel
-- Measures : revenue (SUM, AVG), order_id (COUNT DISTINCT), quantity_sold (SUM)
-- Partition : YEAR(sale_date)
-- Reflection 3 : Aggregation (rapport annuel par vendeur)
-- agg_sales_annual_salesperson
-- Dimensions : YEAR(sale_date), salesperson_id, salesperson_name, region
-- Measures : revenue (SUM), order_id (COUNT DISTINCT)
-- Dremio choisit automatiquement :
-- GROUP BY mois, region, catégorie -> Reflection 2
-- GROUP BY annee, vendeur -> Reflection 3
-- SELECT * -> Reflection 14. Lire un Profil de Requête Dremio
Après chaque exécution, Dremio génère un profil JSON téléchargeable (bouton « Profile » dans l’historique des jobs). Voici les champs clés à analyser pour diagnostiquer l’utilisation des Reflections.
4.1 Champs de l’accélération Profile
| Champ JSON | Valeur / Signification |
|---|---|
| accelerated | true = Reflection utilisée. false = scan de la source (a investiguer) |
| numSubstitutions | Nombre de tentatives. > 0 avec accelerated=false = Reflection trouvée mais non matchee |
| millisTakenSubstituting | Temps de recherche de Reflection. > 500ms = probleme (IN long, requête trop complexe) |
| millisTakenNormalizing | Temps de normalisation du plan. > 1000ms = requête difficile à analyser |
| layoutProfiles[].name | Nom de la Reflection candidate trouvée |
| layoutProfiles[].substitutions | [] vide = aucune substitution réussie pour cette Reflection |
| numPlanCacheUsed | 1 = plan utilise du cache (plus rapide). 0 = plan recalcule |
4.2 Profil : Reflection Activée
-- Profil JSON : requete acceleree avec succes
{
"start": 1700000000000,
"end": 1700000000650, -- durée totale : 0.65 seconde
"accelerationProfile": {
"accelerated": true, -- Reflection utilisee
"numSubstitutions": 1,
"millisTakenGettingMaterializations": 2, -- recherche Reflection : 2ms
"millisTakenNormalizing": 95, -- normalisation plan : 95ms
"millisTakenSubstituting": 38, -- substitution reussie : 38ms
"layoutProfiles": [{
"name": "agg_sales_monthly_region", -- nom de la Reflection utilisee
"type": 2, -- 2 = Aggregation
"numSubstitutions": 1,
"substitutions": ["MATCHED"] -- match reussi
}]
}
}4.3 Profil : Reflection Non Activée — Diagnostic
-- Profil JSON : requête non accélérée (IN() trop long)
{
"start": 1700000000000,
"end": 1700000180000, -- duree totale : 3 minutes
"accelerationProfile": {
"accelerated": false, -- Reflection NON utilisee
"numSubstitutions": 1, -- 1 tentative, échec
"millisTakenGettingMaterializations": 3,
"millisTakenNormalizing": 980, -- 980ms : IN long a normaliser
"millisTakenSubstituting": 1520, -- 1520ms : matching echoue
"layoutProfiles": [{
"name": "agg_sales_monthly_region",
"type": 2,
"numSubstitutions": 1,
"substitutions": [] -- [] vide = aucun match reussi
}]
}
-- Diagnostic : millisTakenSubstituting eleve + substitutions vide
-- => cause probable : filtre IN() avec liste trop longue
-- Solution : remplacer IN() par une JOIN (voir Cas 3, section 3)
}5. Erreurs Fréquentes et Checklist
5.1 Erreurs à Éviter
Ne jamais faire
- Créer une Agrégation Reflection sur un dataset dont les requêtes ne font ni GROUP BY ni fonctions d’agrégation Ex : une requête SELECT client_id, nom, montant FROM ventes n’agrège rien → une Raw Reflection sera bien plus adaptée
- Oublier d’inclure une colonne dans le Display : une seule colonne manquante empêche l’utilisation de la Raw Reflection Ex : ta Raw Reflection inclut client_id, nom, montant mais pas date_commande → une requête qui sélectionne date_commande ignorera complètement la Reflection et interrogera la source directement
- Configurer un TTL(Time To Live) inférieur à l’intervalle de refresh : gap inévitable où les requêtes ne profitent plus de la Reflection Ex : TTL à 1h mais refresh toutes les 2h → pendant la 2ème heure, la Reflection est expirée et Dremio retombe sur la source
- Créer des Reflections sur des tables mises à jour toutes les minutes : le refresh constant annule tout bénéfice Ex : une table de logs applicatifs alimentée en temps réel → chaque refresh relit toute la table, consomme du CPU et du stockage pour un gain quasi nul
- Multiplier les Reflections inutilement : chaque Reflection a un coût de stockage et CPU au refresh Ex : créer 10 Agrégation Reflections légèrement différentes sur la même table alors que 2 ou 3 bien conçues couvrent 95% des cas d’usage
- Ignorer le statut FAILED : vérifier régulièrement le tableau de bord Reflections Ex : une Réflection en statut FAILED depuis 3 jours suite à un changement de schéma de la table source → toutes les requêtes tapent directement la source sans que personne ne s’en aperçoive
5.2 Checklist de Creation
- Identifier les requêtes les plus lentes via le Job History Dremio (filtrer duree > 5 secondes)
- Déterminer : la requête fait-elle GROUP BY ou des fonctions d’agrégation (SUM, COUNT, AVG…) ? → Aggregation. SELECT * ou des colonnes sans agrégation ? → Raw
- Lister toutes les colonnes nécessaires : SELECT, WHERE, GROUP BY, ORDER BY, JOIN
- Vérifier l’absence de IN() long dans le WHERE. Si présent, prévoir une JOINVérifier l’absence de IN() long dans le WHERE. Si présent, prévoir une JOIN
- Choisir la colonne de partitionnement (généralement la date ou l’année)
- Créer la Réflection dans l’interface Dremio (onglet Reflections du dataset)
- Attendre la fin du premier refresh (statut DONE) avant de tester
- Executer la requete test et vérifier accelerated = true dans le profil JSON
Ex: »accelerationProfile »: {
« accelerated »: true,
« numSubstitutions »: 1,
« millisTakenGettingMaterializations »: 6,
… } - Configurer le refresh schedule après l’heure de fin de l’ETL source
- Fixer le TTL(Time To Live) = intervalle de refresh + 1 heure minimum
Ex: TTL = 5h, refresh = 4h →Même si le refresh a 1h de retard, la Reflection reste valide - Documenter la Reflection : objectif, colonnes, responsable, date, fréquence
- Monitorer le statut hebdomadairement et alerter en cas de statut FAILED par levérification manuelle dans l’interface Dremio ou via l’API Dremio (pour automatiser)
5.3 Les 5 Règles d’Or
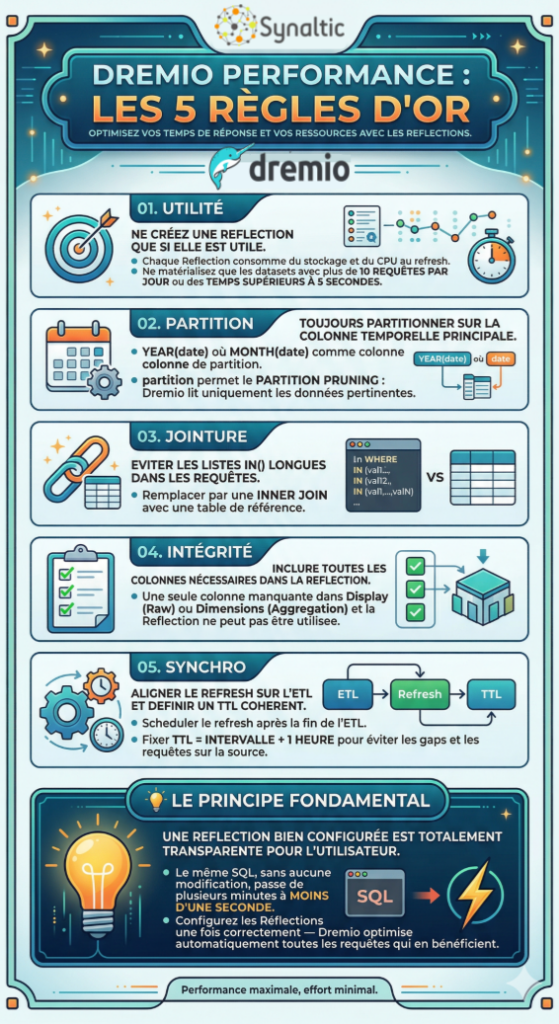

Sections commentaires non disponible.