

L’architecture lakehouse
Cet article fait partie de la série « Maillage de données avec Dremio ». Dans l’article précédent, nous avons posé les bases de la méthode : commencer petit, choisir le bon premier domaine, constituer la bonne équipe. Aujourd’hui, nous passons à la technique : comment construire concrètement votre architecture lakehouse avec Dremio et Apache Iceberg™.
Vous avez jusque-là construit une vision globale du projet. Vous avez l’opportunité de vous lancer. Le projet est maintenant palpable. Lancez-vous !
Les choses se corsent un peu… Pour faire la démonstration de votre preuve de valeur et en tirer un enseignement, vous devez certainement commencer techniquement. Vous allez devoir passer par cette phase qui peut être redoutée.
Installez maintenant la toute première mouture de votre plateforme.
N’industrialisez pas ce que vous n’avez pas encore compris
Ici, un rappel crucial : c’est la valeur qui nous intéresse. Pas la technologie pour la technologie.
Dremio présente un avantage certain. Vous prenez juste une machine avec suffisamment de ressources et cet Agentic Lakehouse sait d’ores et déjà vous servir. Vous connectez une ou deux sources de données. Et c’est parti, vous êtes en mesure de délivrer un produit de données.
Vous êtes encore en itération zéro… Ne vous encombrez pas trop avec différentes propositions pour vos différents types de traitements. Il vous faut déjà une solution qui marche. Au cours de votre projet, vous aurez l’organisation pour répéter des POCs et des MVPs afin de mettre en œuvre de nouvelles fonctionnalités basées sur des briques nouvelles. Bien sûr, le but étant d’industrialiser — par la suite, vous prendrez le temps pour valider tel ou tel composant.
L’Open Lakehouse : Dremio + Apache Iceberg
L’architecture proposée est celle de l’open lakehouse avec Apache Iceberg™ soutenu par Dremio.
Voilà ! Vous y êtes ! Vous avez votre architecture lakehouse avec sa zone d’atterrissage pour votre tout premier domaine.
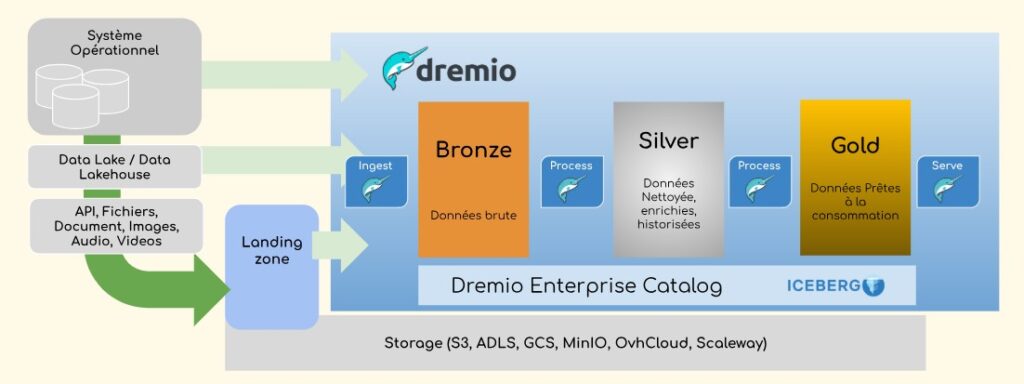
Cette logique correspond autant à une infrastructure sur site, en cloud ou hybride. Lancés comme vous êtes, vous êtes enfin prêt à faire atterrir vos données au plus près de la plateforme. Certes, nous avons parlé de plusieurs domaines ou des entreprises organisées par processus. Mais vous commencez à peine ! N’ayez dans un premier temps qu’une seule zone d’atterrissage (Landing Zone) ! C’est ici que vous amenez les données issues de vos sources.
Le modèle médaillon : Bronze, Silver, Gold
Comme vous pouvez le voir, vos données amenées dans la zone d’atterrissage vont suivre différents traitements afin d’être raffinées au fur et à mesure via des couches souvent nommées « bronze » puis « silver » pour finalement être servies aux utilisateurs métier depuis une couche dite « gold ».
On parle alors de “modèle médaillon”.
De la même manière que l’on parle de cube alors qu’il y a bien plus de 3 dimensions dans un modèle de données d’analyse, de la même manière les 3 couches du modèle médaillon correspondent à une abstraction. Certainement que vous pourriez avoir besoin de plus de couches. Nous vous invitons toutefois à bien structurer votre approche afin qu’elle puisse être comprise et reprise selon un « formalisme » bien identifié.
En résumé :
- Bronze — Données brutes, telles qu’extraites des sources. Vous créez vos tables au format Apache Iceberg et vous les alimentez. L’historisation se fait ici.
- Silver — Données nettoyées, enrichies, historisées. Ce sont des vues Apache Iceberg™ gérées par Dremio.
- Gold — Données prêtes à la consommation pour les utilisateurs métier. Ce sont également des vues. Vous pouvez, pour des questions de performance, « accélérer » certaines vues.
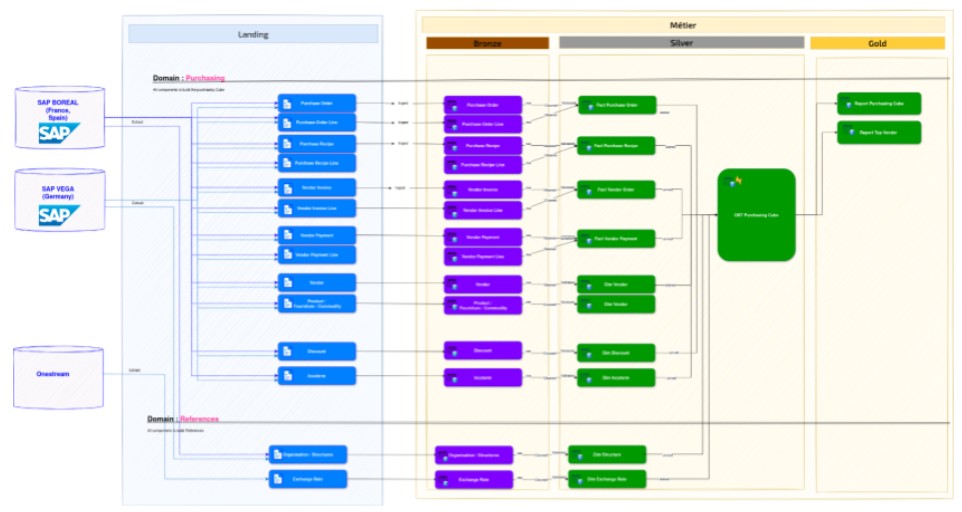
Structurer votre zone d’atterrissage
Pour mieux vous aider, Synaltic vous propose d’organiser votre zone d’atterrissage par exemple de cette manière :
| container://landing/ │ ├── {source}/ │ │ ├── {domain} │ │ │ ├── {subject} │ │ │ │ ├──{_version schema} │ │ │ │ │ ├──date={transaction date yyyy-MM-dd} │ │ │ │ │ │ ├── {subject}-{context}-{timestamp}.(csv|parquet) │ │ │ │ │ │ └── …. |
| Modèle | Désignation | exemple |
| {source} | Libellé, identifiant unique de la source de vos données (ERP, CRA, Solution de gestion…) | SAP_R3 |
| {domain} | Libellé, identifiant unique du processus | purchasing |
| {subject} | Libellé, identifiant unique de la table | order |
| {_version schema} | numéro de version de votre schéma de données pour la table | _V001 |
| date={transaction date yyyy-MM-dd} | partitions de vos données. Bien entendu vous pouvez avoir plusieurs partitions | date=2026-01-12 |
| {subject}-{context}-{timestamp}.parquet | Nom du fichier csv, parquet | order-purchase-20260112T224855.parquet |
Tables vs Vues : où persister, où virtualiser
Il est bien évident que ce sont des équipes compétentes qui vont tirer la donnée des sources pour la mettre à disposition dans la zone d’atterrissage. Néanmoins, il faut bien retenir que ces derniers agissent sous la responsabilité des utilisateurs métiers.
Ainsi, cette première équipe métier, le propriétaire du produit de données à bâtir et les ingénieurs de données travaillent en étroite collaboration pour rendre les données disponibles. Ils commencent par extraire les données des systèmes sources et les ingèrent dans la couche Bronze.
Il va de soi que le travail s’effectue avec Dremio. Synaltic vous recommande d’héberger vos transformations via un référentiel Git afin d’être en mesure de rejouer vos requêtes. Vous pouvez employer l’interface de Dremio, son API REST ou simplement son moteur SQL pour transformer vos données vers cette première couche Bronze.
Notre recommandation :
- Couche Bronze → Tables Apache Iceberg™ (persistées, historisées)
- Couches Silver et Gold → Vues Apache Iceberg™ gérées par Dremio (virtualisées)
Votre dernière couche Gold expose finalement la donnée aux utilisateurs métiers. Vous pouvez, pour des questions de performance, « accélérer » certaines vues grâce aux Reflections de Dremio.
Un premier test rapide avec EXTERNAL_QUERY
Vous voulez valider rapidement que tout fonctionne ? Dremio permet d’exécuter vos requêtes existantes directement sur vos sources avec EXTERNAL_QUERY :

Et c’est parti ! Vous venez d’éliminer un nombre certain d’interrogations que vous aviez.
Ce que vous avez maintenant
Avec une idée de plus en plus précise de la méthodologie, avec l’assurance gagnée durant la mise en œuvre des premières briques de votre plateforme, vous allez être en mesure d’étendre le périmètre à d’autres domaines, à d’autres cas d’usage.
L’objectif de cette série n’est pas forcément d’expliquer dans le détail tous les concepts. Il s’agit bien de vous transmettre une méthodologie et de vous la rendre claire et accessible. Bien sûr, Synaltic vous épaule durant toutes ces phases.
Industrialiser avec DBT
Bien sûr, vous devrez trouver des mécanismes pour industrialiser la livraison de vos modèles. Vous pouvez utiliser divers outils disponibles. DBT présente des avantages certains parce que Dremio maintient une extension DBT. Synaltic vous propose différents articles sur le sujet.
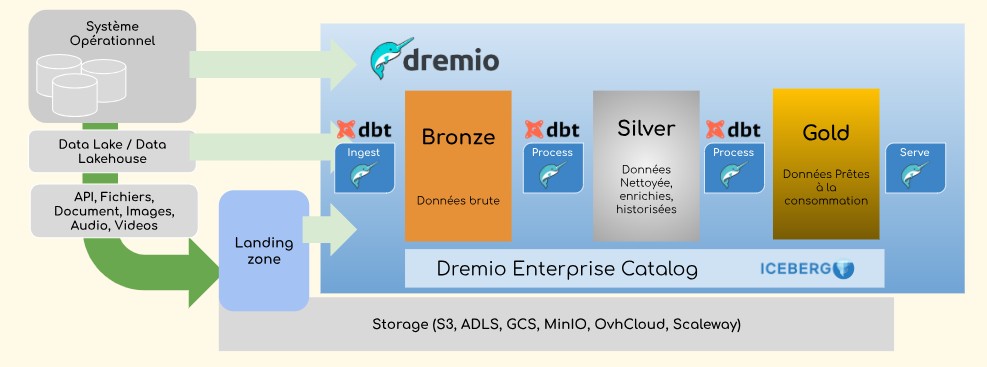
Votre couche Gold présente des vues très orientées métiers, définitivement prêtes à la consommation comme des datamarts (modèle aplati : One Big Table) ou encore des vues agrégées.
Ce qu’il vous reste à faire
Vous y êtes ! Vous approchez votre tout premier modèle pour votre premier domaine. Qu’avez-vous appris ? Que retenez‑vous de cette première étape ? Faites évoluer votre cadre. Vous pouvez poser les bases d’une industrialisation avec ce nouveau recul.
Profitez-en pour vérifier quel a été votre budget pour arriver à l’obtention de ce premier data product. Extrapolez et construisez votre budget pour vos prochains domaines.
Avant d’aller plus loin, revenez une fois sur vos modèles pour deux raisons :
- S’assurer que le modèle répond à vos besoins et qu’il rentre dans votre industrialisation (et l’automatisation)
- S’assurer qu’il répond à vos futurs besoins afin de coopérer avec d’autres équipes pour d’autres produits de données
Rendez-vous au prochain article pour découvrir comment sécuriser vos données sans freiner vos équipes : Gouvernance, catalogue et gestion des droits avec Apache Polaris™.

Sections commentaires non disponible.