

Open Kubernetes Data Platform — une réponse aux coûts cachés de l’assemblage.
Vue d’ensemble : le modèle OKDP
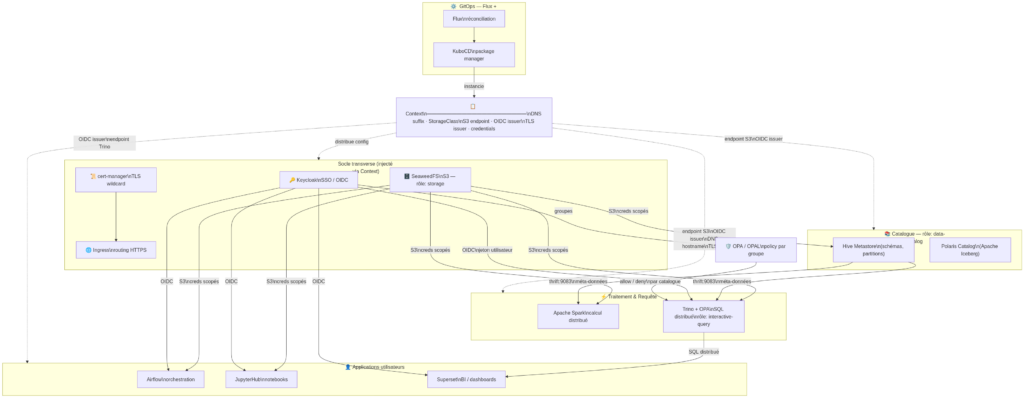
Lecture du schéma. Le Context (centre) distribue une seule fois les paramètres partagés (DNS, S3, OIDC, TLS) à chaque module — les flèches pointillées. Les flèches pleines montrent les flux de données et d’identité à l’exécution : S3 (SeaweedFS) comme lac de données commun, OIDC (Keycloak) comme bus d’identité, OPA comme couche d’autorisation fine-grained sur Trino. La chaîne de dépendances (storage → data-catalog → interactive-query) est résolue automatiquement par KuboCD.
Pourquoi s’intéresser à une plateforme de données intégrée
Pour nos clients Synaltic construit des plateformes de données qui s’appuient sur des solutions de stockage, de requêteurs SQL, d’Apache Iceberg, de solutions de streaming. Depuis Kubernetes nous pouvons de mieux en mieux réexploiter les déploiements des différents composants. Mais qu’en serait-il s’il la glue avait déjà été posée ?
Le paradoxe de la stack data moderne
Chaque brique d’une plateforme data moderne est mature, open-source, et libre. Apache Spark pour le traitement. Dremio, Trino, Apacche Data Fusion, DuckDB pour la requête SQL distribuée. Airflow pour l’orchestration. JupyterHub pour les notebooks. Apache Superset, Metabase pour la visualisation. Un stockage objet compatible S3 pour la persistance.
Pourtant, assembler tout cela prend un temps certain.
Installer Trino prend une heure. Le faire parler à Spark, lire sur votre S3 privé, s’appuyer sur vos groupes Active Directory afin de garantir l’accès aux tableaux de bord dans Apache Superset — voilà projet en tant que tel.
Cette asymétrie est le point de départ d’OKDP : la complexité n’est pas dans les outils, elle est dans leurs intégrations.
Ce que « intégrer » veut vraiment dire
Quand une équipe assemble une stack data from scratch, elle résout en réalité quatre problèmes distincts — et chacun se répète pour chaque outil ajouté.
Le stockage partagé
Spark écrit ses résultats en S3 ou tel une table Apache Iceberg. Trino lit des fichiers Parquet ou des tables Apache Iceberg depuis S3. Airflow archive ses logs en S3 ou exécute des traitements Spark, Trino, Dremio. Jupyter monte des datasets depuis S3 ou issue de votre catalogue Iceberg. Chaque service a besoin d’un endpoint, d’une identité (access key / secret key), d’un périmètre de droits et d’une configuration TLS.
Multiplié par sept outils, c’est quatorze secrets à créer, synchroniser et faire évoluer ensemble. Un endpoint qui change — migration de MinIO vers SeaweedFS, passage en HTTPS — et c’est une mise à jour coordonnée dans toutes les configurations.
L’identité et le SSO
Une organisation dispose d’un référentiel d’identités (Active Directory, Keycloak, Okta). Chaque outil doit l’intégrer — mais chacun a sa propre façon de consommer l’OIDC. Trino attend un issuer-uri et un client-id. Superset attend une base_url de realm et un scope. JupyterHub a sa propre configuration OAuth2. Airflow encore une autre.
Sans une couche d’intégration commune, chaque ajout d’outil est un nouveau projet SSO.
L’autorisation fine-grained
L’authentification (qui est-on ?) et l’autorisation (qu’a-t-on le droit de faire ?) sont deux sujets distincts. Un utilisateur du groupe « data analysts » doit-il pouvoir écrire dans le catalogue Hive ? Lire toutes les tables Trino ? Accéder aux logs Spark ?
Ce niveau de contrôle — essentiel en production — repose sur des politiques (OPA, RBAC Spark, rôles Superset) qui doivent être cohérentes avec les groupes SSO. Sans outillage dédié, cette cohérence est fragile et manuelle.
Routing, TLS et reproductibilité
Chaque service a besoin d’un hostname (trino.mondomaine.interne), d’un certificat TLS valide, d’une règle ingress dans le cluster. Sur un environnement, c’est faisable. Reproduire exactement la même configuration sur dev, staging et production — sans copier-coller de fichiers de configuration — est un problème d’ingénierie à part entière.
Résultat : une équipe qui assemble cette stack from scratch consacre 60 à 80 % de son effort aux intégrations, et seulement le reste à la valeur métier — les pipelines, les analyses, les modèles.
L’approche OKDP : un bus d’intégration déclaratif
OKDP (Open Kubernetes Data Platform) est une plateforme open-source qui s’appuie sur Kubernetes pour packager, déployer et intégrer ces outils. Son modèle repose sur une idée centrale : définir les paramètres d’intégration une seule fois, et les distribuer automatiquement à chaque composant.
Le Context : la configuration partagée
Au cœur d’OKDP se trouve un objet appelé Context. Il contient, une seule fois :
- le domaine DNS de la plateforme (okdp.monentreprise.fr)
- l’endpoint du stockage objet et ses politiques d’accès par service
- l’émetteur de certificats TLS
- l’issuer OIDC (Keycloak) et les clients configurés
- la classe de stockage Kubernetes
Chaque composant déployé hérite de ces valeurs. Déployer Trino ne nécessite pas de lui re-configurer l’endpoint S3 ou l’issuer OIDC — il les reçoit du Context.
Les modules : des briques pré-intégrées
Un module OKDP est un package qui encapsule un outil (Trino, SeaweedFS, Hive Metastore, Spark Operator…) et toute sa logique d’intégration. Il consomme les variables du Context pour se configurer automatiquement : endpoint S3, hostname d’ingress, certificat, credentials scopés.
Ajouter SeaweedFS à une plateforme existante, c’est déployer un package. Trino — qui déclare avoir besoin du rôle storage — détecte automatiquement que le stockage est disponible et se connecte. Pas de copier-coller de configuration. Pas de synchronisation manuelle de secrets.
Les dépendances déclarées
Chaque module déclare les rôles qu’il fournit (storage, data-catalog, interactive-query) et ceux dont il dépend. La plateforme résout l’ordre de déploiement et bloque si une dépendance manque. Un Trino ne peut pas être déployé sans un Hive Metastore (data-catalog) ni sans un stockage objet (storage).
Ce mécanisme élimine une source classique d’erreurs en production : le déploiement dans le mauvais ordre, ou la tentative de démarrer un service dont les dépendances ne sont pas prêtes.
Cette modularisation est proche des paquets linux et des dépendances que l’on peut observer entre services systemd.
Une illustration concrète
Sur un cluster Kubernetes Talos à trois nœuds, la stack complète — SeaweedFS, Hive Metastore, Trino avec politique d’autorisation OPA, authentification SSO Keycloak — se déploie en moins d’une heure, par un kubectl apply sur quatre fichiers YAML. Un job de chargement télécharge automatiquement le dataset public NYC Taxi (243 MiB, trois catégories de trajets) et le dépose dans le stockage S3. Résultat : 11,2 millions de lignes requêtables en SQL distribué, avec contrôle d’accès par groupe d’utilisateurs.
Sans OKDP, chacune de ces intégrations — S3→Trino, Keycloak→Trino, OPA→Trino, Hive→S3 — aurait été un sous-projet à part entière.
De HDP, CDP à OKDP : délivrer la valeur pour les métiers
Time-to-value. Une équipe data peut être productive en heures sur un cluster existant, sans attendre des semaines de configuration. Le socle technique est livré ; l’équipe se concentre sur les cas d’usage.
Reproductibilité. Le même manifeste YAML déploie la même plateforme sur dev, staging et production. Un upgrade de version d’un composant se réduit à changer un tag dans un fichier — la plateforme se réconcilie automatiquement.
Extensibilité maîtrisée. Ajouter un module au catalogue, c’est écrire un package qui consomme le Context. L’intégration S3, OIDC et DNS est automatique. Une organisation peut publier ses propres modules — outils internes, connecteurs propriétaires — selon le même modèle.
Souveraineté. OKDP est 100 % open-source, déployable on-premise ou dans n’importe quel cloud. Aucun vendor lock-in sur les données, les workloads ou l’infrastructure.
Séparation des responsabilités. Les Platform Engineers gèrent le socle (Context, modules, releases). Les Data Engineers consomment les services via un catalogue self-service. Les deux équipes travaillent en parallèle sans se bloquer mutuellement.Avec une telle approche, il est plus évident d’embrasser les conceptes de maillage de données (Data Mesh) avec le contract de données, les data products.
Les limites à connaître
OKDP est un projet jeune (version 0.5 au moment de cet article). La version 0.6, en cours, refonde le modèle d’authentification et améliore la synchronisation entre déploiements déclaratifs et inventaire de l’interface de gestion. Pour une organisation qui l’adopte aujourd’hui, il faut anticiper une courbe d’apprentissage sur le modèle de packaging KuboCD, et accepter de contribuer à une communauté en croissance plutôt qu’à un produit stabilisé.
Où en est le projet et ce qui vient
Ce qui est disponible aujourd’hui
Les modules data du catalogue sont pour la plupart finalisés : Apache Spark (avec History Server, Auth Proxy et Web Proxy), Trino (OIDC + OPA), Apache Superset, Apache Airflow, JupyterHub. Un composant moins visible mais stratégique est également complet : Polaris Catalog, le catalogue de tables Apache Iceberg développé par Snowflake et désormais incubé à l’Apache Software Foundation. Il s’intègre à Trino, supporte l’authentification OIDC et le contrôle d’accès OPA — et ouvre la voie au format de table ouvert Iceberg en remplacement ou en complément de Hive.
Roadmap vers la v1.0 — 14 septembre 2026
La version 1.0 est prévue pour le 14 septembre 2026. Elle matérialise le premier jalon de production : API stable, modèle de packaging figé, documentation complète.
Trois chantiers structurants sont en cours :
1. Refonte du control plane. La v1.0 introduit deux consoles distinctes : une Admin Console (gestion des clusters, des utilisateurs, des groupes) et une Project Console (espaces de travail isolés via un CRD Project, instanciation self-service de JupyterHub, Spark History Server, Trino, Superset, gestion des secrets via Vault). C’est la réponse à la rupture actuelle entre déploiement déclaratif et inventaire de l’interface.
2. Stabilisation de la sandbox. Migration vers une API Gateway (au-delà de l’ingress NGINX), introduction d’un okdp-operator pour piloter le cycle de vie des composants, et un chart Helm okdp-platform pour simplifier l’installation.
3. Documentation et guides. Admin Guide, User Guide et une application de démonstration accompagneront la v1.0.
Au-delà de la v1.0 : vers une plateforme data & AI
La roadmap post-v1.0 étend le périmètre vers deux directions :
- IA/MLOps : Kubeflow est en cours d’intégration, MLflow et le serving de LLM sont planifiés. OKDP se positionne comme socle data et AI, pas seulement data.
- Streaming et gouvernance : Apache Kafka, Flink, NiFi et OpenMetadata (catalogage de données) sont dans le backlog, pour couvrir les cas d’usage d’ingestion temps-réel et de data governance.
La roadmap complète est publiée sur okdp.io/roadmap.
Pour commencer
Le dépôt okdp/okdp-sandbox fournit un environnement complet prêt à l’emploi : un cluster Kind local, tous les composants préconfigurés, des exemples de données inclus.
git clone https://github.com/okdp/okdp-sandbox.git
La documentation d’installation couvre Kind pour un premier essai local, ainsi que le déploiement sur un cluster Kubernetes existant (les prérequis se limitent à une StorageClass par défaut et un LoadBalancer).
OKDP est un projet communautaire. Les contributions — nouveaux modules, retours d’expérience, corrections — sont les bienvenues sur github.com/okdp.
Cet article s’appuie sur une expérience de déploiement d’OKDP v0.5 sur un cluster Talos Kubernetes, incluant SeaweedFS, Hive Metastore, Trino avec OPA, et le chargement du dataset public NYC Taxi Trip Data.

Sections commentaires non disponible.