

Cet article présente une approche simple pour surveiller l’utilisation d’Apache Superset™ directement depuis Superset, en exploitant sa base de métadonnées interne.
Monitorer l’usage d’un outil de dataviz comme Apache SupersetTM est essentiel pour garantir sa bonne adoption, repérer les contenus les plus consultés, et identifier les axes d’amélioration (Qui l’utilise ? Quels tableaux de bord sont consultés ? Quels types de visualisations sont privilégiés ?) Autant de questions clés pour assurer le bon pilotage de l’environnement analytique 🙂
L’idée consiste à connecter la base dans laquelle Superset stocke ses informations (actions utilisateur, tableaux de bord, graphiques, etc.) comme source de données, puis à construire un tableau de bord de supervision en quelques étapes.
Cette méthode permet d’avoir une vue complète de l’utilisation de l’outil en temps réel, que ce soit l’utilisation des jeux de données, l’utilisation des graphiques ou des tableaux de bords. Nous vous donnons ainsi les clés pour suivre certaines activités sur votre Superset.
Étape 1 — Se connecter à la base de métadonnées :
Dans cet article, nous allons adopter une approche directe : connecter directement la base de métadonnées de Superset à Superset lui-même.
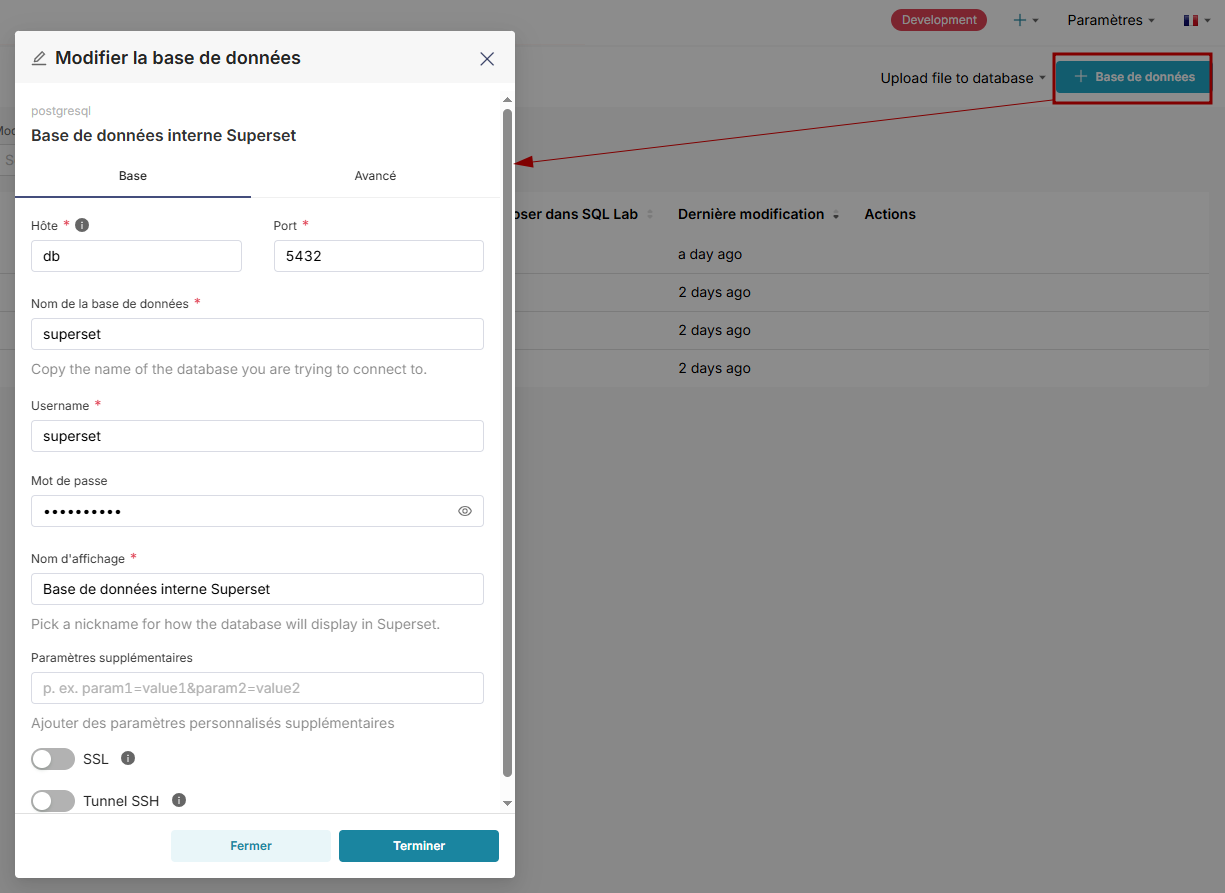
Ajout de la base de métadonnées (Postgres dans notre cas) comme source sur Superset
Bien sûr, cette approche est fortement déconseillée dans un environnement de production, surtout si l’on souhaite :
- Éviter d’exposer directement la base de données de production dans Superset
- Connecter la base de métadonnées via une autre source de données dédiée
- Parser les contenus JSON pour accéder à des logs détaillés
Une solution plus robuste :
- Importer le contenu de la base de métadonnées dans votre plateforme de données (data warehouse, data lakehouse …) avec un ETL ou en temps réel via Debezium ou tout simplement en écoutant un réplica de la base de Superset.
- Modéliser les données par exemple avec DBT
- Ajoutez les datasets sur Superset via votre connexion habituelle ( dans notre cas chez Synaltic, nous utilisons le data lakehouse DREMIO)
Étape 2 — Explorer le modèle de données :
Une fois connecté, vous accédez à 55 tables utilisées en interne par Superset. La documentation étant limitée, un diagramme UML est fourni ci-dessous.
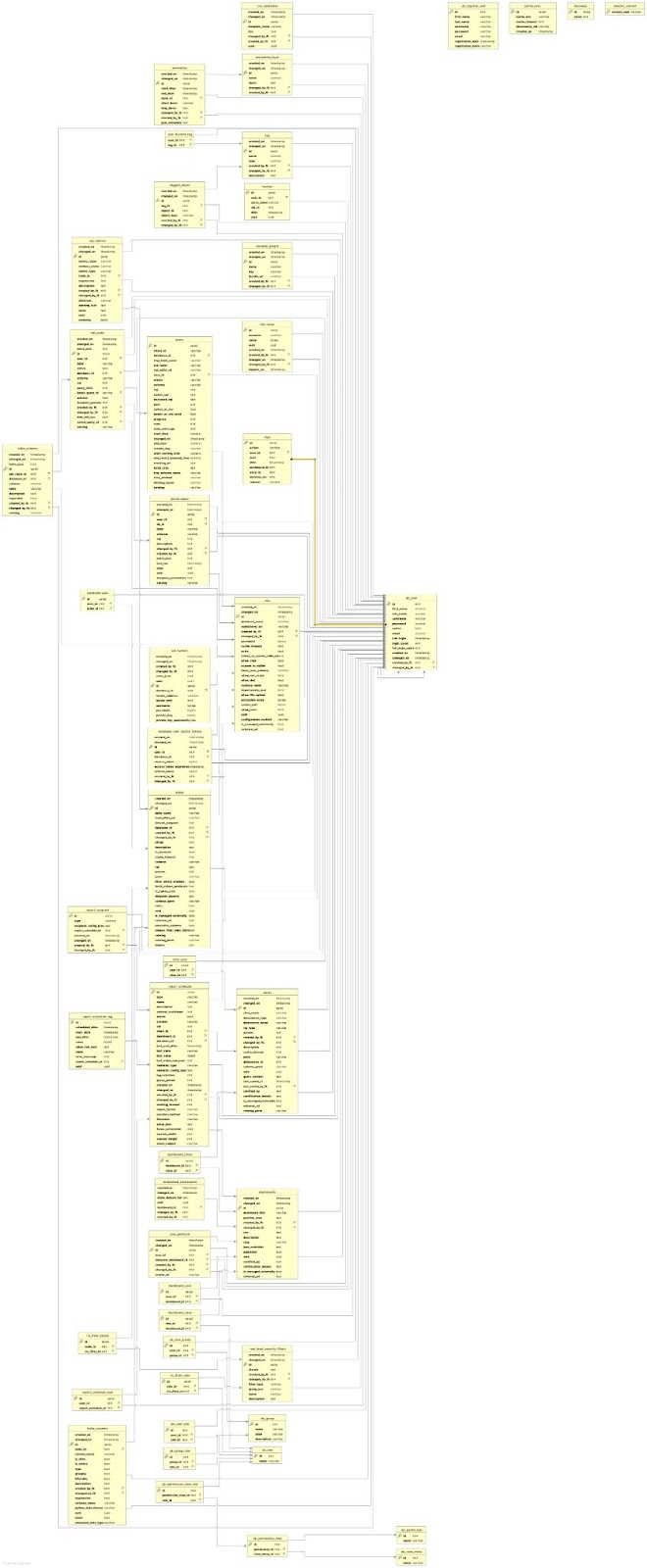
Diagramme UML de la base de métadonnées d’Apache SupersetTM
Nous retiendrons uniquement les tables qui nous intéressent, à savoir :
- logs : toutes les actions utilisateur, avec un champ JSON
- dashboards : contient les informations des tableaux de bords
- slices : informations des graphiques (ou “slices”)
- ab_user : informations des utilisateurs
- tables : les informations sur les ensembles de données (datasets)
En complément, afin de faciliter l’exploitation de la base de métadonnées, nous allons créer un dataset virtuel ( dataset virtuel = un dataset défini directement dans l’interface de Superset à partir d’une requête SQL ) pour effectuer une jointure entre les objets Superset (dashboards, graphiques, datasets, etc.) et les données de logs.
Note :
La requête SQL complète du dataset virtuel est disponible à la fin de l’article.
Étape 3 — Définir les objectifs
Après avoir analysé la structure des tables de base, nous allons définir les principaux axes d’analyse à explorer dans ce projet. Trois grandes thématiques guideront notre démarche :
1. Taux d’adoption des utilisateurs
Nous chercherons à comprendre comment Superset est utilisé au quotidien. Concrètement, nous voulons répondre à des questions telles que :
- Combien d’utilisateurs se connectent et utilisent réellement Superset ?
- Quels tableaux de bord (dashboards) et jeux de données sont les plus consultés ?
Ces informations nous permettront par exemple d’identifier les contenus jamais utilisés, ce qui pourra aider leurs créateurs à les améliorer ou, le cas échéant, à les supprimer.
2. Types de graphiques
Nous analyserons aussi quels types de graphiques sont les plus populaires. Cela nous sera utile pour :
- Déterminer s’il faut prévoir des tests spécifiques lors des mises à jour de Superset, car certains types de graphiques peuvent évoluer d’une version à l’autre.
- Orienter les utilisateurs vers des visualisations plus robustes ou standardisées, par exemple en encourageant l’usage des séries temporelles ECharts plutôt que des simples graphiques linéaires.
3. Utilisation des jeux de données virtualisés
Pour mieux comprendre la construction des analyses dans Superset, nous étudierons également la manière dont les utilisateurs exploitent les jeux de données virtualisés. Ces derniers, créés directement dans Superset, permettent de définir des vues personnalisées à partir de requêtes SQL. Ils sont souvent utilisés pour :
- Effectuer des jointures entre plusieurs tables depuis la même source de données.
- Fusionner différents jeux de données.
- Appliquer des calculs complexes non possibles directement dans les graphiques (fonctions fenêtres par exemple).
Nous observerons notament si certains jeux de données virtuels sont créés pour faire des transformations très simples, comme un simple renommage de colonnes ou l’ajout de conditions élémentaires. Dans ce cas, nous privilégierons l’intégration de ces ajustements directement dans la couche de données en amont (dans le data lakehouse DREMIO) afin d’éviter une prolifération inutile de jeux de données dans Superset.
Étape 4 — Construire le tableau de bord de monitoring
Une fois les jeux de données prêts, nous allons créer les graphiques et assembler le dashboard. Le but est que ce tableau de bord répond aux questions que nous avons définies lors de l’étape précédente, chacun apportant une réponse à une question.
Exemples de visualisations :
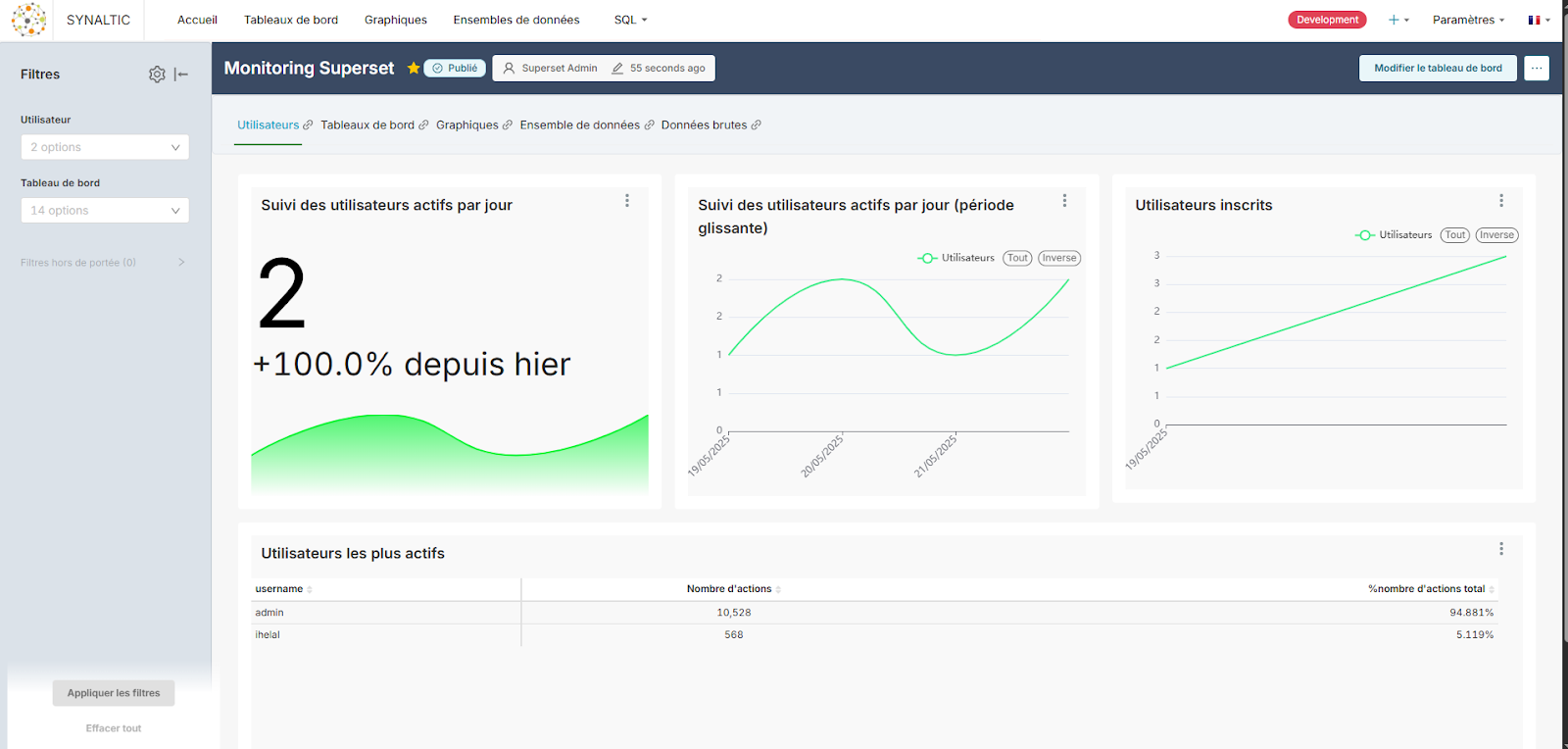
Évolution et activité des utilisateurs
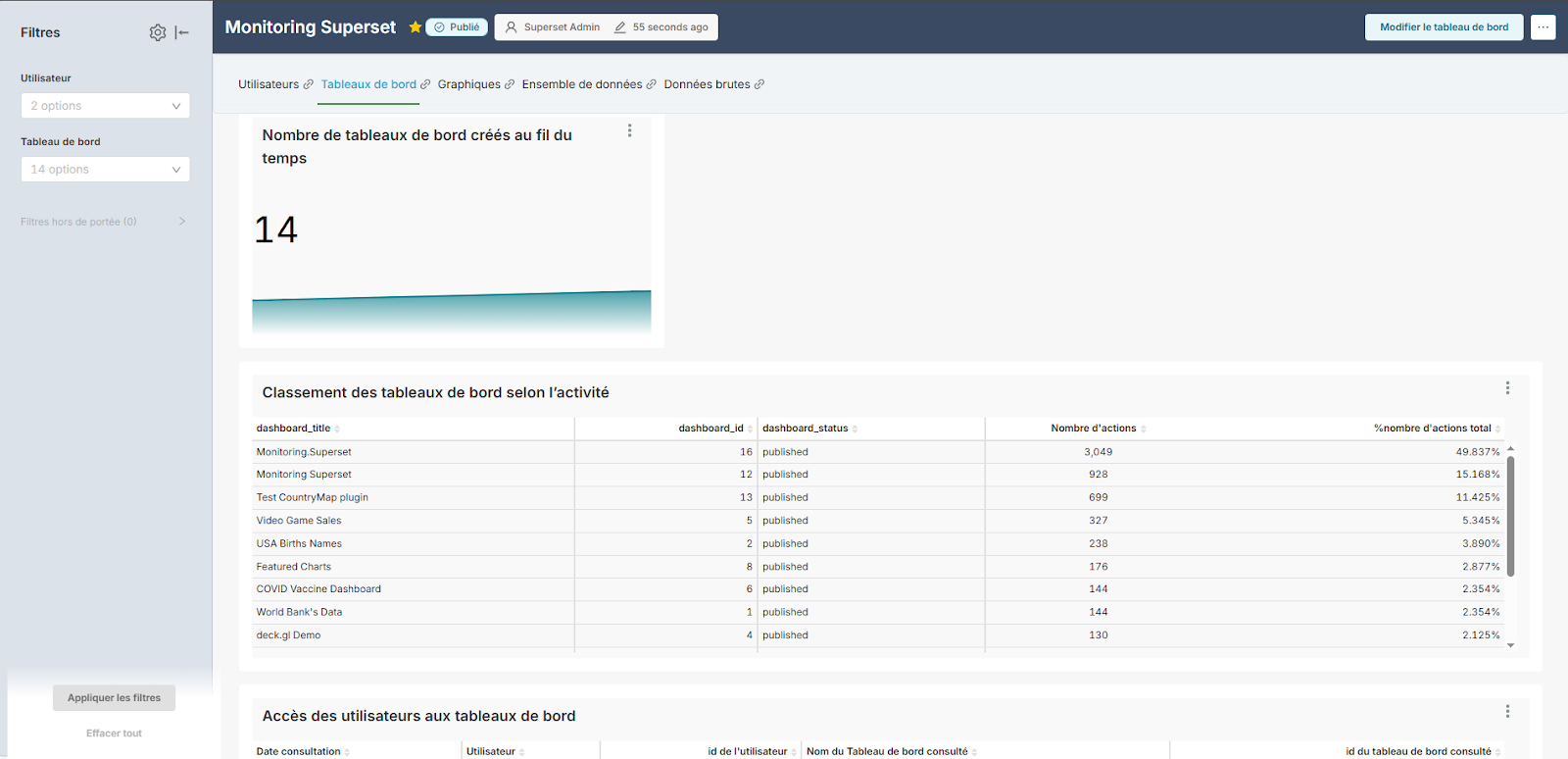
Évolution des tableaux de bords et taux d’accès
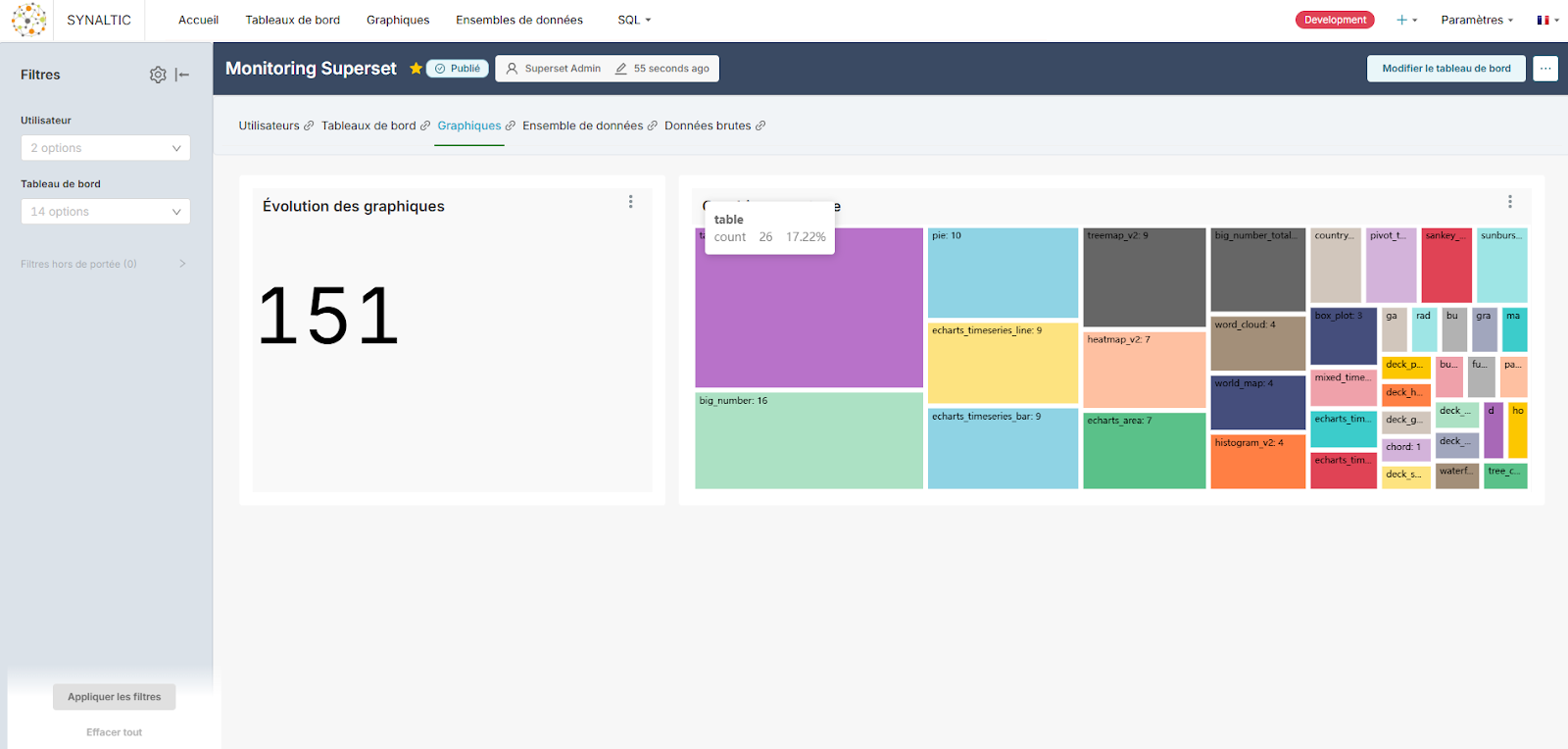
Évolution des graphiques et choix les plus fréquents

Évolution des jeux de données.
Quelles suites ?
Bien que cette première itération du tableau de bord nous ait déjà permis de dégager des enseignements intéressants, plusieurs pistes d’amélioration restent à explorer.
Mieux classifier l’activité
Il est possible d’aller plus loin dans la classification des événements enregistrés dans la colonne action de la table des logs, afin d’en tirer un meilleur parti. À ce jour, 104 types d’actions sont définis dans notre base, incluant notamment :
- welcome (déclenchée lorsqu’un utilisateur accède à la page d’accueil)
- annotation* (lorsqu’un utilisateur interagit avec des calques d’annotations)
- divers appels API get ou list
- des actions internes comme explore_json.
Certaines de ces actions se produisent en arrière-plan et ne sont pas aussi pertinentes à analyser que d’autres, plus représentatives de l’utilisation réelle de Superset, comme :
- queries (lorsqu’une requête est exécutée depuis SQL Lab),
- ChartRestApi.data (chargement de données via un composant graphique),
- dashboardrestapi.get (consultation d’un tableau de bord).
Un axe d’amélioration serait d’analyser le contenu au format JSON des entrées où action = ‘log’ cela permettrait d’obtenir des informations plus fines sur la classification des actions.
Intégrer une vision de la performance
À ce stade, nous n’avons pas encore trouvé de méthode satisfaisante pour construire une vue orientée performance, combinant à la fois le temps d’exécution des requêtes et l’impact du cache interne de Superset.
Nous avons expérimenté l’utilisation de la colonne duration_ms dans la table des logs, mais sans certitude quant à sa fiabilité.
Annexes:
Code SQL pour le dataset virtuel : superset_activity_log :
SELECT
l.dttm AS action_datetime, -- Date et heure de l'action
-- Classification des actions pour les regrouper par type fonctionnel
CASE
-- Requête SQL depuis SQL Lab
WHEN lower(l.action) = 'queries' THEN 'query from sqllab'
-- Données chargées via un graphique
WHEN lower(l.action) = 'chartrestapi.data' THEN 'query from charts'
-- Consultation d'un dashboard
WHEN lower(l.action) = 'dashboardrestapi.get' THEN 'dashboard view'
-- Action liée aux annotations
WHEN lower(l.action) LIKE 'annotation%' THEN 'annotations'
-- Modification ou chargement de CSS
WHEN lower(l.action) LIKE 'css%' THEN 'css'
-- Autres actions laissées telles quelles
ELSE lower(l.action)
END AS action,
-- Informations sur l'utilisateur ayant réalisé l'action
l.user_id,
u.username,
u.created_on AS user_registration_date,
-- Informations sur le dashboard concerné par l'action
l.dashboard_id,
d.dashboard_title,
-- Statut du dashboard : publié ou brouillon (draft)
CASE
WHEN l.dashboard_id IS NOT NULL AND d.published = TRUE THEN 'published'
WHEN l.dashboard_id IS NOT NULL AND d.published = FALSE THEN 'draft'
ELSE NULL
END AS dashboard_status,
-- Informations sur le graphique (slice)concerné
l.slice_id,
s.slice_name,
s.datasource_type,
s.datasource_name,
s.datasource_id,
-- Type de dataset : physique ou virtuel, basé sur la présence d'une requête SQL
CASE
WHEN t.sql IS NULL OR t.sql = '' THEN 'physical' -- Dataset relié directement à une table
ELSE 'virtual' -- Dataset défini via une requête SQL (virtuel)
END AS dataset_type
-- Jointures avec les tables utilisateurs, dashboards, slices, et tables (datasets)
FROM logs AS l
LEFT JOIN ab_user AS u ON u.id = l.user_id
LEFT JOIN dashboards AS d ON d.id = l.dashboard_id
LEFT JOIN slices AS s ON s.id = l.slice_id
LEFT JOIN tables AS t ON t.id = s.datasource_id AND s.datasource_type = 'table'
-- Filtrage : pour le moment, on exclut les événements 'log' qui sont de type JSON
WHERE l.action != 'log'
