
Qu’est-ce que PG_LAKE ?
pg_lake est un ensemble d’extensions PostgreSQL open-source (Apache 2.0) qui transforme votre base de données PostgreSQL en une plateforme hybride OLTP/OLAP capable d’interagir nativement avec Apache Iceberg et votre data lakehouse.
Développé initialement chez Crunchy Data puis repris par Snowflake après l’acquisition, pg_lake permet de :
- Créer et gérer des tables Iceberg directement depuis PostgreSQL avec transactions ACID
- Requêter des fichiers Parquet, CSV, JSON stockés en object storage (S3, Azure Blob, GCS)
- Importer/exporter des données avec la commande COPY native de PostgreSQL
- Bénéficier de performances analytiques élevées grâce à l’intégration de DuckDB dans le moteur de requêtes
Particularité technique : pg_lake utilise une syntaxe 100% PostgreSQL. Vous créez simplement une table USING iceberg ou une foreign table avec SERVER pg_lake, et tout fonctionne de manière transparente.
PostgreSQL : Le système de gestion de base de données de référence
PostgreSQL n’est plus à présenter. Présent dans des milliers d’organisations à travers le monde, de la startup à la multinationale, il s’est imposé comme le SGBD relationnel open-source de référence pour :
- Sa robustesse et sa fiabilité : ACID, réplication, haute disponibilité
- Sa richesse fonctionnelle : types avancés, JSON, PostGIS, extensions tierces
- Sa communauté active : développement continu, écosystème d’outils mature
- Sa flexibilité : du petit site web au data warehouse multi-téraoctets
Cependant, PostgreSQL reste fondamentalement une base OLTP, conçue pour les transactions rapides et les lectures/écritures concurrentes. Les workloads analytiques sur de gros volumes de données peuvent saturer les ressources et impacter la production.
Un historique mouvementé : de Crunchy Data à Snowflake
L’histoire de pg_lake illustre l’évolution rapide de l’écosystème data :
2022 – Crunchy Bridge for Analytics : Crunchy Data intègre DuckDB dans PostgreSQL pour permettre l’analyse de fichiers Parquet, CSV et JSON directement depuis Postgres. L’extension bénéficie également du support PostGIS et de nombreuses optimisations.
2023 – Crunchy Data Warehouse : Ajout du support complet d’Apache Iceberg avec mise à jour, changements de schéma et transactions distribuées entre tables PostgreSQL classiques et tables Iceberg.
2024 – Acquisition par Snowflake : Crunchy Data est racheté par Snowflake. Le projet est rebaptisé pg_lake et publié en open-source sur GitHub (snowflake-labs/pg_lake).
Comme le souligne Marco Slot, core developer du projet :
« pg_lake is not experimental software. It is already powering large scale production workloads as part of Crunchy Data Warehouse, and we designed for that from the start. »
Les motivations : réconcilier OLTP et OLAP
Les créateurs de pg_lake ont identifié une frustration récurrente dans l’industrie : la séparation forcée entre systèmes transactionnels (OLTP) et systèmes analytiques (OLAP).
Cette dichotomie impose :
- Des architectures complexes : ETL, pipelines de synchronisation, orchestration
- De la duplication de données : coûts de stockage et risques de désynchronisation
- Des délais dans l’analyse : les données analytiques sont souvent en retard sur la production
- Des compétences fragmentées : DBA PostgreSQL vs ingénieurs data lake
Leur vision : permettre aux développeurs et data engineers de travailler avec un seul outil, PostgreSQL, tout en bénéficiant des avantages du lakehouse moderne (coûts de stockage réduits, format ouvert, interopérabilité).
L’extension compagnon pg_incremental complète cette vision en gérant les pipelines incrémentaux :
- Détection automatique de nouveaux fichiers dans l’object storage
- Traitement incrémental basé sur séquences ou timestamps
- Gestion transparente des échecs avec bookkeeping transactionnel
Pourquoi Apache Iceberg dans les organisations modernes ?
Apache Iceberg s’est imposé comme le format de table open-source de référence pour les data lakehouses, et ce n’est pas un hasard :
Pour l’analytique traditionnelle
- Performance : partition pruning intelligent, statistiques au niveau colonne
- Évolution de schéma sans douleur : ajout/suppression de colonnes sans réécrire les données
- Time-travel et audit : requêtes sur des snapshots historiques
- ACID garanti : pas de lectures sales même avec des écritures concurrentes
Pour l’IA agentique et le RAG (Retrieval-Augmented Generation)
L’émergence des agents IA et des applications LLM transforme les besoins en données :
- Accès unifié : un agent peut interroger des milliards de lignes avec la même interface SQL
- Fraîcheur des données : les agents ont besoin de contexte à jour, pas de snapshots de la veille
- Traçabilité : capacity à auditer quelles données ont alimenté quelle décision (time-travel)
- Coût : stocker des embeddings et features sur S3/Parquet coûte 10x moins cher qu’en base relationnelle
Les architectures d’IA moderne ne séparent plus « données transactionnelles » et « données analytiques ». Elles requièrent un accès unifié, rapide et économique à l’ensemble du data estate.
Le paysage des initiatives PostgreSQL + Lakehouse
pg_lake n’est pas seul dans l’écosystème PostgreSQL HTAP (Hybrid Transactional/Analytical Processing). Voici un comparatif rapide :
| Initiative | Approche | Avantages | Limitations |
|---|---|---|---|
| pg_lake | Extensions natives + DuckDB intégré | Transparence totale, production-ready, Iceberg natif | Nécessite compilation (pas de binaires officiels encore) |
| pg_duckdb | Extension FDW DuckDB | Simple, focus sur la rapidité analytique | Pas de support Iceberg write natif |
| Mooncake | Cache vectorisé pour pg_analytics | Performance analytique pure | Architecture plus complexe, moins mature |
| BemiDB | Fork PostgreSQL avec moteur colonnaire | Performances exceptionnelles | Fork = divergence du core PostgreSQL |
pg_lake se distingue par :
- Support complet des écritures Iceberg avec transactions
- Interface 100% PostgreSQL native (pas de nouvelle syntaxe)
- Production-ready avec déploiements industriels existants
- Support de pg_incremental pour les pipelines ETL
Notre cas d’usage : un groupe avec des filiales décentralisées
Contexte
Notre organisation est structurée en filiales autonomes, chacune gérant sa propre base PostgreSQL pour ses applications métiers. Cette décentralisation offre de l’agilité locale mais complique le partage de données à l’échelle du groupe.
Objectifs :
- Moderniser l’infrastructure data sans refonte complète
- Permettre le partage de jeux de données entre filiales
- Maintenir l’autonomie des filiales sur leurs données
- Réduire les coûts de stockage analytique
Solution retenue : pg_lake en local + Apache Polaris en central
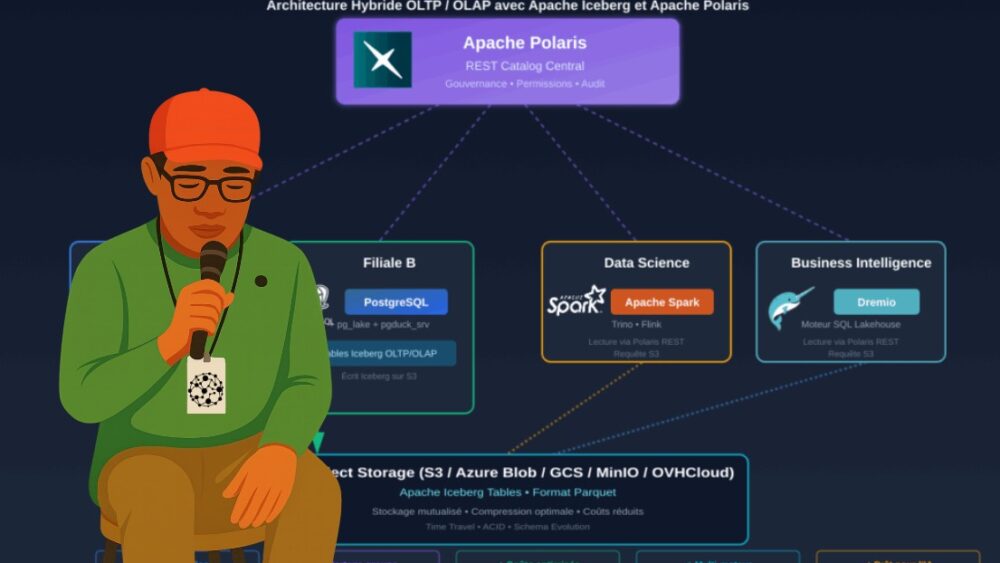
Architecture cible
┌─────────────────────────────────────────────────────────────┐
│ Apache Polaris (Central) │
│ REST Catalog pour tout le groupe │
│ Namespace: pg_lake (partagé entre filiales) │
└─────────────────────┬──────────────┬────────────────────────┘
│ REST API │
┌─────────────┼──────────────┼──────────────────┐
│ │ │ │
┌───────▼───────┐ ┌───▼──────────┐ ┌─▼──────────────┐ ┌─▼──────────────┐
│ Filiale A │ │ Filiale B │ │ Data Science │ │ BI │
│ │ │ │ │ (Spark) │ │ (Dremio) │
│ PostgreSQL │ │ PostgreSQL │ │ │ │ │
│ + pg_lake │ │ + pg_lake │ │ Lecture via │ │ Lecture via │
│ + pgduck_srv │ │ + pgduck_srv │ │ Polaris │ │ Polaris │
│ │ │ │ │ │ │ │
│ Écrit Iceberg │ │ Écrit Iceberg│ │ Requête S3 │ │ Requête S3 │
│ sur S3 │ │ sur S3 │ │ │ │ │
└───────────────┘ └──────────────┘ └────────────────┘ └────────────────┘
│ │ │ │
└────────┬───────┴─────────────────┴───────────────────┘
▼
┌─────────────┐
│ Object Store│
│ (S3) │
│ testbucket │
└─────────────┘Bénéfices de cette architecture
- Décentralisation préservée : chaque filiale garde son PostgreSQL autonome
- Partage centralisé : Polaris offre un catalogue unifié des datasets groupe
- Coût optimisé : stockage S3 mutualisé, format Parquet compressé
- Interopérabilité : Dremio, Spark, Trino, Flink peuvent tous lire via Polaris
- Gouvernance : Polaris gère les permissions et l’audit centralisé
Guide pratique : de PostgreSQL à Iceberg via Polaris
Étape 1 : Installation de pg_lake
# Cloner le repository
git clone https://github.com/snowflake-labs/pg_lake.git
cd pg_lake
# Compilation et installation
make
sudo make installActivation dans PostgreSQL :
CREATE EXTENSION pg_lake_iceberg CASCADE;
CREATE EXTENSION pg_lake_table CASCADE;
CREATE EXTENSION pgduck_server CASCADE;Étape 2 : Configuration du storage prefix
pg_lake utilise un GUC pour définir le préfixe de stockage par défaut :
-- Dans postgresql.conf ou via ALTER SYSTEM
ALTER SYSTEM SET pg_lake_iceberg.default_location_prefix = 's3://testbucket/pg_lake';
SELECT pg_reload_conf();Ce paramètre est crucial pour l’intégration avec Polaris : toutes les tables Iceberg créées par pg_lake utiliseront ce préfixe.
Étape 3 : Création d’une table Iceberg – Exemple DVD Rental
Prenons la table classique actor de la base DVD Rental :
-- Table PostgreSQL classique (existante)
SELECT * FROM actor LIMIT 3;
/*
actor_id | first_name | last_name | last_update
----------+------------+-----------+------------------------
1 | Penelope | Guiness | 2013-05-26 14:47:57.62
2 | Nick | Wahlberg | 2013-05-26 14:47:57.62
3 | Ed | Chase | 2013-05-26 14:47:57.62
*/
-- Créer une table Iceberg et copier les données
CREATE TABLE ice_dvdrental_actor (
actor_id INTEGER,
first_name VARCHAR(45),
last_name VARCHAR(45),
last_update TIMESTAMP
) USING iceberg;
-- Insérer les données
INSERT INTO ice_dvdrental_actor
SELECT * FROM actor;
-- Vérifier
SELECT COUNT(*) FROM ice_dvdrental_actor;
200 rowspg_lake crée automatiquement :
- Un dossier s3://testbucket/pg_lake/dvdrental/public/ice_dvdrental_actor/
- pg_lake : namespace
- dvdrental : base de données
- public : schéma
- ice_dvdrental_actor : tables
- Des fichiers Parquet dans /data/
- Des fichiers de métadonnées Iceberg dans /metadata/

Étape 4 : Configuration d’Apache Polaris
Déploiement de Polaris en mode standalone :
docker run -d \
--name polaris \
-p 8181:8181 \
-e AWS_ACCESS_KEY_ID=minioadmin \
-e AWS_SECRET_ACCESS_KEY=minioadmin \
-e AWS_REGION=us-east-1 \
apache/polaris:latestCréation d’un catalogue et namespace dédié à pg_lake :
# Via Polaris CLI
polaris principals create myuser
polaris catalogs create pg_lake_catalog \
--type INTERNAL \
--default-base-location s3://testbucket/pg_lake \
--storage-type S3 \
--allowed-location s3://testbucket/pg_lake
# Créer un namespace pour pg_lake
polaris namespaces create --catalog pg_lake_catalog pg_lake \
--location s3://testbucket/pg_lake \
--property owner=pg_lakePoint critique : pg_lake et Polaris doivent partager le même bucket S3 et préfixe. C’est pourquoi :
- pg_lake_iceberg.default_location_prefix = ‘s3://testbucket/pg_lake’
- Namespace Polaris : location = ‘s3://testbucket/pg_lake’
Étape 5 : Enregistrement automatique des tables dans Polaris
Dans notre organisation, nous avons établi une convention de nommage :
- Toutes les tables Iceberg de pg_lake commencent par ice_
- Le nom après ice_ suit le pattern : {database}_{table_name}
Script Python pour l’enregistrement automatique :
#!/usr/bin/env python3
"""
Synchronisation automatique des tables Iceberg pg_lake vers Apache Polaris
"""
import boto3
import requests
from pyspark.sql import SparkSession
class PgLakePolarisSync:
def __init__(self, s3_bucket, s3_prefix, polaris_url, catalog_name):
self.s3_client = boto3.client('s3')
self.s3_bucket = s3_bucket
self.s3_prefix = s3_prefix
self.polaris_url = polaris_url
self.catalog_name = catalog_name
# Configuration Spark avec Polaris
self.spark = SparkSession.builder \
.appName("PgLake-Polaris-Sync") \
.config("spark.jars.packages",
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.5.0,"
"org.apache.iceberg:iceberg-aws-bundle:1.5.0") \
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config(f"spark.sql.catalog.{catalog_name}",
"org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.catalog-impl",
"org.apache.iceberg.rest.RESTCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.uri",
f"{polaris_url}/api/catalog") \
.config(f"spark.sql.catalog.{catalog_name}.rest.auth.type",
"oauth2") \
.config(f"spark.sql.catalog.{catalog_name}.oauth2-server-uri",
f"{polaris_url}/api/catalog/v1/oauth/tokens") \
.config(f"spark.sql.catalog.{catalog_name}.credential",
"client_id:client_secret") \
.config(f"spark.sql.catalog.{catalog_name}.scope",
"PRINCIPAL_ROLE:ALL") \
.config(f"spark.sql.catalog.{catalog_name}.s3.access-key-id",
"minioadmin") \
.config(f"spark.sql.catalog.{catalog_name}.s3.secret-access-key",
"minioadmin") \
.config(f"spark.sql.catalog.{catalog_name}.s3.endpoint",
"http://localhost:9000") \
.config(f"spark.sql.catalog.{catalog_name}.s3.path-style-access",
"true") \
.config(f"spark.sql.catalog.{catalog_name}.io-impl",
"org.apache.iceberg.aws.s3.S3FileIO") \
.getOrCreate()
def discover_pg_lake_tables(self):
"""Découvre toutes les tables Iceberg créées par pg_lake"""
tables = []
paginator = self.s3_client.get_paginator('list_objects_v2')
for page in paginator.paginate(Bucket=self.s3_bucket,
Prefix=f"{self.s3_prefix}/",
Delimiter='/'):
for prefix in page.get('CommonPrefixes', []):
table_path = prefix['Prefix'].rstrip('/')
table_name = table_path.split('/')[-1]
# Recherche du fichier metadata le plus récent
metadata_files = []
for obj in self.s3_client.list_objects_v2(
Bucket=self.s3_bucket,
Prefix=f"{table_path}/metadata/"
)['Contents']:
if obj['Key'].endswith('.metadata.json'):
metadata_files.append(obj['Key'])
if metadata_files:
# Trier par version (le plus récent en dernier)
latest_metadata = sorted(metadata_files)[-1]
metadata_location = f"s3://{self.s3_bucket}/{latest_metadata}"
tables.append({
'name': table_name,
'metadata_location': metadata_location
})
return tables
def register_table_in_polaris(self, table_name, metadata_location):
"""Enregistre une table dans Polaris via Spark"""
try:
# Vérifier si la table existe déjà
existing_tables = self.spark.sql(
f"SHOW TABLES IN {self.catalog_name}.pg_lake"
).collect()
table_exists = any(row.tableName == table_name for row in existing_tables)
if table_exists:
print(f"⚠️ Table {table_name} existe déjà, mise à jour...")
# Option 1: DROP puis recréer
self.spark.sql(
f"DROP TABLE {self.catalog_name}.pg_lake.{table_name}"
)
# Enregistrer la table
self.spark.sql(f"""
CALL {self.catalog_name}.system.register_table(
table => 'pg_lake.{table_name}',
metadata_file => '{metadata_location}'
)
""")
print(f"✅ Table {table_name} enregistrée avec succès")
return True
except Exception as e:
print(f"❌ Erreur lors de l'enregistrement de {table_name}: {str(e)}")
return False
def sync_all_tables(self):
"""Synchronise toutes les tables pg_lake vers Polaris"""
tables = self.discover_pg_lake_tables()
print(f"📊 {len(tables)} tables Iceberg découvertes")
success_count = 0
for table in tables:
if self.register_table_in_polaris(
table['name'],
table['metadata_location']
):
success_count += 1
print(f"\n✨ Synchronisation terminée: {success_count}/{len(tables)} tables")
# Utilisation
if __name__ == "__main__":
sync = PgLakePolarisSync(
s3_bucket="testbucket",
s3_prefix="pg_lake",
polaris_url="http://localhost:8181",
catalog_name="polaris"
)
sync.sync_all_tables()Exécution :
python3 pg_lake_polaris_sync.pyRésultat attendu :
📊 5 tables Iceberg découvertes
✅ Table ice_dvdrental_actor enregistrée avec succès
✅ Table ice_dvdrental_film enregistrée avec succès
✅ Table ice_dvdrental_customer enregistrée avec succès
✅ Table ice_dvdrental_rental enregistrée avec succès
✅ Table ice_dvdrental_payment enregistrée avec succès
✨ Synchronisation terminée: 5/5 tablesÉtape 6 : Interroger les données depuis Spark
Une fois les tables enregistrées dans Polaris, n’importe quel service avec les autorisations appropriées peut les requêter :
from pyspark.sql import SparkSession
# Configuration Spark avec catalogue Polaris
spark = SparkSession.builder \
.appName("DataScience-Analysis") \
.config("spark.sql.catalog.polaris", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.polaris.catalog-impl", "org.apache.iceberg.rest.RESTCatalog") \
.config("spark.sql.catalog.polaris.uri", "http://polaris:8181/api/catalog") \
.getOrCreate()
# Requête SQL standard
df = spark.sql("""
SELECT
first_name,
last_name,
COUNT(*) as film_count
FROM polaris.pg_lake.ice_dvdrental_actor
GROUP BY first_name, last_name
ORDER BY film_count DESC
LIMIT 10
""")
df.show()Le service Data Science peut ainsi accéder aux données créées par pg_lake dans les filiales, sans connexion directe aux bases PostgreSQL de production. Toute la gouvernance (authentification, autorisation, audit) passe par Polaris.
Étape 7 : Interroger les données depuis Dremio pour alimenter les tableaux de bord
Utilisons Dremio Open Source la version 25.2 ! Il faut tout d’abord activer les sources de type Apache Iceberg REST Catalog.
Allez au niveau des « Settings » > « Support » > « Support keys » et valider l’option plugins.restcatalog.enabled.

Configurer la source
Depuis le panneau de gauche ajouter une source de données. Ici on peut maintenant choisir Rest Iceberg Catalog.

Depuis l’onglet « General » remplissez les champs :
- Name :
polaris(Bien sûr vous pourvez indiquez l’appellation fonctionnelle ou métier qui convient le mieux) - Endpoint URI :
http://polaris:8181/api/catalog
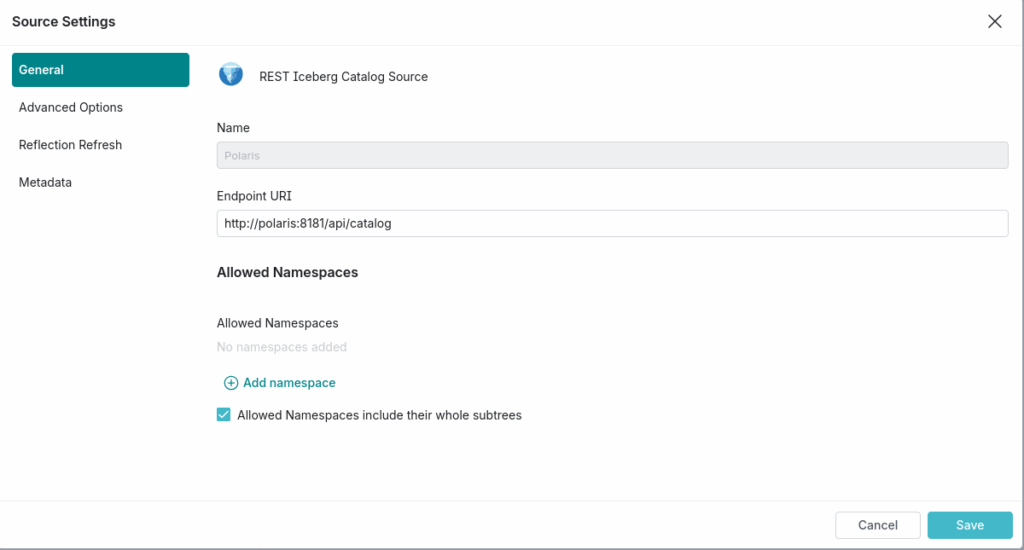
Dans l’onglet « Advanced Settings » ajouter des propriétés
- Catalog Properties :
warehouse:polaris_oss_catalog(ou le nom de ton catalogue Polaris)scope:PRINCIPAL_ROLE:ALL
- Catalog Credentials :
- credential : <<utiliateur polaris>>:<<mot de passe polaris>>

Vous pouvez finalement interroger votre catalogue Apache Polaris et exploiter toutes les fonctionnalités de Dremio pour offrir un accès unique à toutes vos données pour tous vos tableaux de bord.

Remarque : Il est vrai que Dremio pourrait être connecté à l’ensemble des bases de données PostgreSQL des filiales. Toutefois, ici, Apache Polaris est privilégé pour assurer une gouvernance à l’échelle du Groupe quand Dremio joue, par exemple, un rôle pour « accélérer » les requêtes utilisateurs et tenir la charge des nombreux utilisateurs qui interrogent les données depuis leurs tableaux de bord.
Ce que nous retenons et perspectives
Points de vigilance identifiés
- Compatibilité REST Catalog : Actuellement, pg_lake bloque les écritures vers les catalogues REST (voir pg_lake_table/src/fdw/option.c:842). Vous devez créer les tables en mode local puis les enregistrer dans Polaris. Nous espérons que les versions futures permettront l’écriture directe via REST catalog.
- Synchronisation des métadonnées : Les mises à jour de tables Iceberg nécessitent de re-synchroniser le catalogue Polaris. Notre script gère le pattern « drop and register » mais une API de mise à jour serait préférable.
- Configuration S3 : Les credentials et endpoints S3 doivent être cohérents entre pg_lake, Polaris et les consumers (Spark, Trino). Attention particulièrement au mode path-style-access avec MinIO.
Ce que nous anticipons
L’écriture directe vers catalogues REST : La présence de REST_CATALOG_READ_WRITE dans le code source de pg_lake suggère que cette fonctionnalité est en développement. Son arrivée simplifiera grandement l’architecture. La manipulation de table qui respectent la spécification V3.
La transformation du développement applicatif (HTAP) : L’émergence de solutions comme pg_lake, pg_duckdb et BemiDB annonce un changement de paradigme. Demain, les développeurs concevront des applications avec l’analytique intégrée dès le départ, sans architecture ETL séparée. Les agents IA, qui nécessitent un accès rapide à des volumes massifs de données contextuelles, accéléreront cette tendance.
Insistons sur le fait d’avoir besoin de moins en moins d’ETL : Pensez à des scénarios où des organisations partenaires partagent des catalogues Apache Iceberg directement depuis leurs bases de données opérationnelles. Elles pourraient ainsi échanger des données entre elles via une simple commande SQL, pilotée par exemple avec PG_Incremental. En parallèle, la lecture de ces tables pourrait également s’effectuer directement depuis la base de données opérationnelle. Iceberg apporte une historisation complète et sans effort de tous les échanges, le tout étant auditable grâce aux snapshots et au « time travel ». Combien de flux ETL pourraient être éliminés grâce à cette approche ? Il est bien sûr nécessaire de renforcer les bases de données opérationnelles pour supporter ces charges. Vous avez également la possibilité de faire supporter PG_LAKE et PG_Duckserver par une réplication de votre base de données opérationnelle.
La modernisation des infocentres : Combien d’organisations maintiennent encore des « data warehouse » ou les « fameux InfoCentres » qui sont en réalité de simples réplications PostgreSQL ? Avec pg_lake, ces réplicas peuvent enfin devenir de véritables bases OLAP :
- Stockage en format colonnaire Parquet (10x moins cher)
- Requêtes analytiques accélérées par DuckDB
- Interopérabilité avec l’écosystème data moderne (Spark, Trino, dbt, Dremio)
L’interopérabilité par design : Apache Iceberg est désormais supporté par AWS (Athena), Google (BigQuery), Azure (Synapse), Databricks, Snowflake et des dizaines d’autres plateformes. En adoptant pg_lake, vous ne vous enfermez pas dans une technologie : vos données restent accessibles depuis n’importe quel outil compatible Iceberg.
Conclusion
pg_lake représente bien plus qu’une simple extension PostgreSQL. C’est une vision : celle d’un monde où la frontière entre bases transactionnelles et entrepôts analytiques s’estompe, où les développeurs n’ont plus à choisir entre performance OLTP et capacités OLAP, où PostgreSQL devient le hub central d’une architecture data moderne.
Pour notre organisation multi-filiales, pg_lake combiné à Apache Polaris offre le meilleur des deux mondes :
- Autonomie locale : chaque filiale garde la main sur son PostgreSQL
- Partage groupe : un catalogue unifié pour la gouvernance et l’interopérabilité
- Coûts maîtrisés : stockage S3 mutualisé, format compressé
- Préparation à l’IA : infrastructure prête pour les agents et le RAG
Si votre organisation utilise PostgreSQL et commence à se sentir à l’étroit face aux besoins analytiques croissants, pg_lake mérite votre attention. Ce n’est pas de l’expérimentation : c’est du logiciel production-ready, utilisé en production, soutenu par Snowflake, et résolument open-source.
Ressources :
- GitHub : snowflake-labs/pg_lake
- Documentation : docs.pg_lake.io
- Apache Polaris : polaris.io
- Apache Iceberg : iceberg.apache.org
Remerciements : Un grand merci à Marco Slot et l’équipe Snowflake pour avoir rendu pg_lake open-source. Cette décision contribue à faire évoluer tout l’écosystème PostgreSQL.
Pour aller plus loin : Synaltic peut vous aider à découvrir et prendre en main Apache Iceberg afin qu’il s’intègre à votre plateforme de données et répondre aux enjeux qui sont les vôtres.
