

Pourquoi c’est une victoire pour la souveraineté des données ?
Il y a des jalons techniques qui passent inaperçus, et puis il y en a d’autres qui méritent qu’on s’arrête. La graduation d’Apache Polaris™ en Top-Level Project (TLP) à la Apache Software Foundation est de ceux-là. Pas parce que c’est une formalité administrative, mais parce que ce que Polaris représente touche à quelque chose de fondamental : la capacité des organisations à garder la maîtrise de leurs données, de leur architecture, et de leur avenir technologique.
Retraçons ensemble le chemin parcouru, et surtout, expliquons pourquoi ça compte vraiment.
D’où vient Apache Polaris™ ?
L’histoire commence en août 2024. Dremio et Snowflake, deux concurrents directs sur le marché du lakehouse, font quelque chose d’inhabituel : ils s’assoient ensemble et donnent leur code à la Apache Software Foundation. Ce code, c’est Polaris, un catalogue pour Apache Iceberg™. Pourquoi faire ça ? Parce que les deux entreprises ont compris quelque chose que le marché tardait à admettre : la couche catalogue ne doit pas être un avantage compétitif propriétaire. Elle doit être un bien commun.
La philosophie est claire depuis le premier jour. Polaris implémente la spec REST Catalog d’Apache Iceberg™, une spécification ouverte qui définit comment les moteurs de requêtes communiquent avec un catalogue de métadonnées. L’idée : n’importe quel moteur (Spark, Flink, Trino, Dremio, DuckDB…) peut se connecter à n’importe quel catalogue compatible. La couche de métadonnées devient interopérable par conception.
La première version publique, la 0.9.0, sort en mars 2025. Elle est encore limitée, essentiellement cloud AWS, périmètre fonctionnel restreint, mais le projet existe, le code est dans l’incubateur Apache, et la communauté commence à se former.
Dix-huit mois de travail collectif
Ce qui s’est passé ensuite est remarquable par sa vitesse. En dix-huit mois d’incubation, le projet a livré six versions. Plus de 2 800 pull requests fusionnées. Une centaine de contributeurs. Un repo GitHub à 1 800 étoiles et 357 forks.
Mais les chiffres bruts ne disent pas tout. Ce qui compte, c’est qui a contribué. Le PMC d’Apache Polaris réunit aujourd’hui des ingénieurs de Dremio, Snowflake, Google, Microsoft, Confluent et LanceDB. Les committers incluent Bloomberg et Starburst. Sur les 13 membres du PMC, six ont été élus pendant l’incubation, ce qui signifie que la communauté a produit sa propre gouvernance plutôt que d’hériter de celle des fondateurs.
C’est précisément ce que la Apache Software Foundation exige pour la graduation : démontrer que le projet peut vivre indépendamment de ses créateurs. Le vote de graduation a obtenu 27 votes favorables et zéro objection. JB Onofré, Directeur de la Fondation Apache et principal champion du projet, a accompagné ce processus de bout en bout.
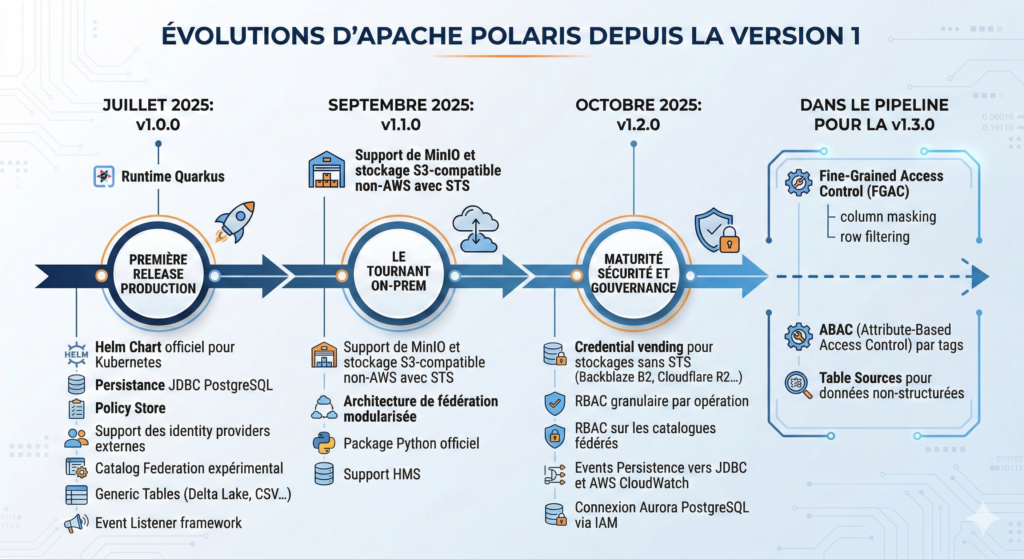
Sur le plan fonctionnel, la trajectoire des versions raconte l’ambition du projet :
Juillet 2025 / v1.0.0 : première release production. Runtime Quarkus, Helm Chart officiel pour Kubernetes, persistance JDBC PostgreSQL, Policy Store, support des identity providers externes, Catalog Federation expérimental, Generic Tables (Delta Lake, CSV…), Event Listener framework.
Septembre 2025 / v1.1.0 : le tournant on-prem. Support de MinIO et du stockage S3-compatible non-AWS avec STS. Architecture de fédération modularisée. Package Python officiel. Support HMS.
Octobre 2025 / v1.2.0 : maturité sécurité et gouvernance. Credential vending pour les stockages sans STS (Backblaze B2, Cloudflare R2…). RBAC granulaire par opération. RBAC sur les catalogues fédérés. Events Persistence vers JDBC et AWS CloudWatch. Connexion Aurora PostgreSQL via IAM.
Et dans le pipeline pour la v1.3.0 : le Fine-Grained Access Control avec column masking et row filtering, l’ABAC (Attribute-Based Access Control) par tags, et les Table Sources pour les données non-structurées.
Pourquoi Polaris est une réponse au vendor lock-in
Pour comprendre l’enjeu, il faut imaginer ce que signifie ne pas avoir de catalogue open source.
Sans catalogue partagé, les métadonnées Iceberg se retrouvent éparpillées : dans le Hive Metastore, dans AWS Glue, dans des stores propriétaires spécifiques à chaque moteur. Chaque copie dérive indépendamment. Les permissions se désynchronisent. Une modification de schéma dans Spark n’est pas visible dans Dremio, dans Apache Flink. Ce n’est pas un cas limite, c’est l’état habituel de la plupart des architectures multi-moteurs aujourd’hui.
La réponse classique de l’industrie à ce problème a longtemps été : acheter un catalogue propriétaire. Choisir Databricks Unity Catalog, ou le catalogue de Snowflake, ou celui d’un autre vendor. Le problème, c’est qu’en faisant ce choix, on ne résout pas le lock-in, on en change juste de forme. On passe du chaos à la dépendance.
Apache Polaris™ pose une question différente : et si la couche catalogue était aussi ouverte qu’Apache Iceberg lui-même ? Et si le catalogue était juste du code, déployable n’importe où, gouverné par personne en particulier ?
Le modèle est intentionnellement étroit dans son scope. Polaris gère les métadonnées Iceberg. Les moteurs gèrent le compute. Les données restent dans votre object storage. Il n’y a rien de propriétaire dans la pile. Vous pouvez déployer Polaris sur votre laptop, sur un cluster Kubernetes on-prem, ou dans le cloud. Vous pouvez changer de moteur de requête demain sans toucher à votre catalogue. Vous pouvez migrer des tables d’un storage à l’autre à travers le même catalogue.
C’est une architecture où la flexibilité est structurelle, pas optionnelle.
La souveraineté des données, concrètement
La souveraineté des données est souvent un mot-valise. Polaris lui donne une traduction technique précise.
Contrôle de l’accès jusqu’au bit. Le mécanisme de credential vending de Polaris est élégant dans sa conception : lorsqu’un moteur de requête demande à accéder à des données, Polaris génère un token temporaire (via STS) qui lui donne accès au storage pour la durée de l’opération. À expiration du token, l’accès est révoqué. Ni le moteur de requête, ni les métadonnées Iceberg elles-mêmes ne portent de credentials permanents. La clé ne sort jamais de Polaris.
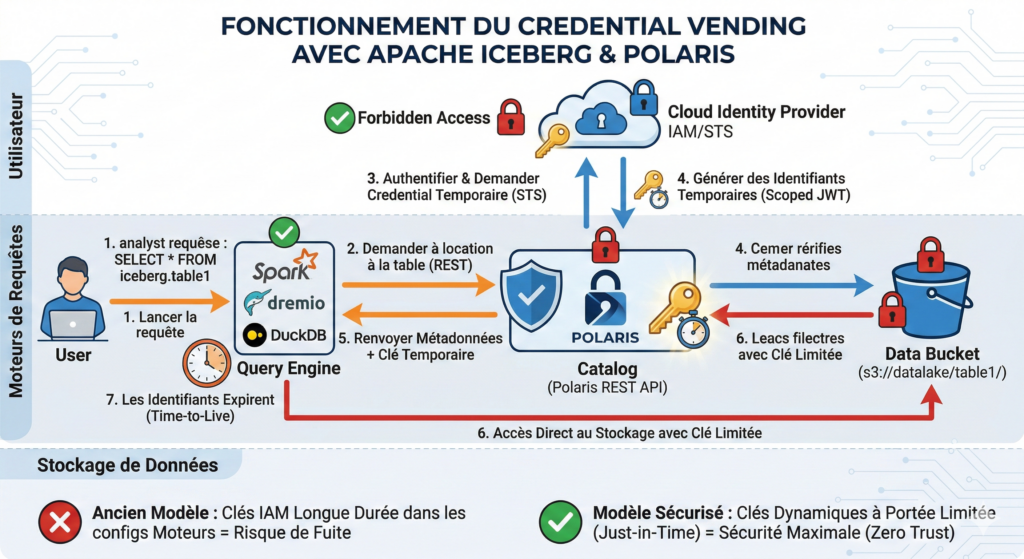
Cette architecture a une conséquence importante : l’accès aux données est centralisé dans Polaris, et Polaris seul. Pas dans le moteur. Pas dans le storage. Dans le catalogue. Ce qui signifie que vous pouvez donner accès à Spark sans donner accès à S3 directement. Vous pouvez révoquer l’accès d’une application sans toucher à la configuration du storage. Vous pouvez auditer précisément qui a accédé à quoi et quand.
Neutralité du stockage. Depuis la v1.1.0, Polaris supporte MinIO, Ozone, et tout stockage compatible S3 on-prem. Depuis la v1.2.0, le credential vending fonctionne même pour les stockages sans STS. Cela signifie qu’une organisation peut déployer une architecture lakehouse souveraine, sur son propre infrastructure, sans aucune dépendance cloud. Les données ne quittent jamais le datacenter si vous ne le souhaitez pas.
Gouvernance découplée de l’infrastructure. Le modèle RBAC de Polaris sépare proprement les rôles au niveau Polaris (les Principal Roles, transverses à tous les catalogues) des rôles au niveau catalogue (les Catalog Roles). On ajoute un nouveau catalogue ? Les utilisateurs existants n’ont pas besoin d’être reconfigurés, on fait juste le mapping. On change de moteur de requête ? Les permissions dans le catalogue ne bougent pas. La gouvernance est dans Polaris, pas dans Spark, pas dans Trino, pas dans le cloud provider.
Ce que change la graduation Apache
Un projet open source n’est pas jugé sur son code. Il est jugé sur sa communauté.
La graduation à la Apache Software Foundation est le signal le plus clair qui existe dans l’écosystème open source pour dire : ce projet peut vivre de manière autonome. L’ASF supervise désormais directement Apache Polaris. La roadmap est gouvernée par la communauté, pas par Dremio, pas par Snowflake. Si Dremio changeait demain de stratégie, Polaris continuerait d’exister et d’évoluer. C’est la garantie structurelle que vos investissements dans Polaris ne seront pas stranded.
Pour les architectes qui construisent des plateformes de données, c’est le feu vert pour standardiser sur Polaris comme couche catalogue. Pour les directions informatiques qui évaluent le risque fournisseur, c’est l’argument de poids : la continuité du projet est garantie par une fondation indépendante, pas par les priorités commerciales d’un éditeur.
La leçon du cycle Hadoop
L’écosystème data a déjà vécu ce genre de moment. Il y a dix ans, Hadoop était le socle universel. Tout le monde construisait dessus. Et puis le marché a pivoté, les vendors ont évolué, et les organisations qui avaient tout misé sur les implémentations propriétaires de l’écosystème Hadoop se sont retrouvées coincées.
La leçon n’était pas « éviter l’open source ». Elle était « choisir les projets dont la gouvernance communautaire est réelle ». Apache Kafka™ a survécu au pivot de Confluent. Apache Spark™ continue d’évoluer indépendamment de Databricks. Ces projets ont une gouvernance diversifiée et des communautés qui ne dépendent d’aucun acteur unique.
Apache Polaris™ s’inscrit dans cette lignée. La graduation n’est pas une formalité, c’est la preuve que le projet a passé le test de maturité communautaire qu’Hadoop, dans ses composants propriétaires, n’avait pas réussi.
Pour conclure
Apache Polaris™ est, techniquement, un catalogue de métadonnées Iceberg. Mais ce qu’il représente est plus large : la conviction que la couche d’interopérabilité d’un écosystème de données doit être un bien commun, pas un avantage concurrentiel.
En dix-huit mois, le projet est passé d’une donation de code à un projet Apache de premier niveau, avec une centaine de contributeurs, six releases, et le support de Google, Microsoft, Confluent, Bloomberg et bien d’autres. Il peut tourner on-prem, sur votre cloud, ou dans votre datacenter. Il peut gérer des tables Iceberg, Delta, et bientôt bien d’autres formats. Il centralise le contrôle d’accès jusqu’au credential, sans que le moteur de requête ait jamais besoin de toucher à votre storage directement.
Ce n’est pas juste un outil. C’est une architecture de souveraineté.
Synaltic accompagne vous accompagne dans la construction de votre plateforme de données, il y a de grande chance qu’Apache Polaris™ en face partie. Essayons d’aller un peu plus loin. Prenons rendez-vous.

Sections commentaires non disponible.