

Exemple d’utilisation de dbt core avec Dremio software #1
Introduction
Data Build Tool (ou dbt) est un outil open source qui facilite la transformation de vos données au sein de votre Data Warehouse ou de votre Data Lakehouse comme Dremio, à travers le processus ELT (Extract Load Transform). L’outil utilise le langage sql pour la transformation des données avec la possibilité d’intégrer du code jinja dans les requêtes ou d’utiliser des macros pour par exemple réutiliser du code ou créer des fonctions. Vous pouvez utiliser git pour faciliter la collaboration et le versionning de votre projet dbt.
Utiliser dbt avec Dremio peut être très utile pour vous aider à organiser et mettre à jour de manière cohérente votre couche sémantique. De plus vous pouvez par exemple, passer très facilement d’un environnement de développement à un environnement de production, contrôler vos données et identifier les problèmes rapidement à l’aide des tests, ou même générer automatiquement une documentation retraçant toutes les transformations qui ont eu lieu. En revanche, la création de wiki ou de tag dans Dremio ne sont pas supportés pour le moment par dbt.
Dans cet article nous allons voir comment initialiser un projet dbt avec Dremio, comment créer une vue ou une table à partir d’un modèle dans dbt et gérer leur configuration ainsi que celle du projet.
Sommaire
Prérequis
-
- Pour Dremio : vous pouvez utiliser Dremio cloud comme Dremio Software (version 22.0 ou supérieures). De plus, il faut disposer d’un utilisateur ayant les droits nécessaires pour effectuer des actions avec dbt (en fonction de ce que vous souhaitez réaliser avec dbt).
- Pour dbt : assurez-vous que Python 3.8.x ou une version ultérieure est installée, ainsi que git.
- Avoir une connaissance basique du langage sql (ainsi que les CTE).
- Compétences basiques dans l’utilisation de la ligne de commande.
Dans la suite, VisualStudio code sera utilisé pour éditer les fichiers du projet. Vous pouvez utiliser un autre IDE ou l’éditeur de fichier de votre choix. Pour VisualStudio code plusieurs plugins existent que vous pouvez installer pour améliorer l’expérience utilisateur dans vos projet dbt comme dbt-power-user.
Dans cet article nous travaillerons sur un environnement linux (ubuntu) avec Dremio software monté avec docker et connecté à une base de données postgres (où le jeux de données est disponible ici).
Initialisation du projet
Installation
On va commencer par se créer un répertoire de travail “dbt_project” pour localiser nos projets dbt. Puis on va créer un environnement python virtuel et y installer dbt-dremio.
mkdir dbt_project/
cd dbt_project/
python3 -m venv dbt-envDans la commande “python3 -m venv dbt-env”, vous pouvez choisir un autre emplacement que dbt-env pour la création de l’environnement virtuel. Ici un répertoire dbt-env sera créé dans le répertoire dbt_project.
Ensuite nous allons activer l’environnement et installer dbt-dremio :
source dbt-env/bin/activate # active l'environnement pour Mac ou Linux
dbt-env\Scripts\activate # active l'environnement pour Windows
pip install dbt-dremio # (vous pouvez installer d’autre connecteur comme dbt-postgres …, lors de l’initialisation d’un projet il suffira de choisir quel type de projet vous souhaitez réaliser, ici Dremio)
dbt --version # pour vérifier l'installationAttention : dans la suite, lorsque vous voudrez exécuter des commandes dbt, il faudra bien vérifier que l’environnement python est bien activé sinon les commandes ne fonctionneront pas. La présence de (dbt-env) indique que l’environnement est activé.

Création du projet
Maintenant que l’installation est terminée, il suffit de créer le projet avec la commande dbt init et de répondre aux questions avec vos informations de connexion.
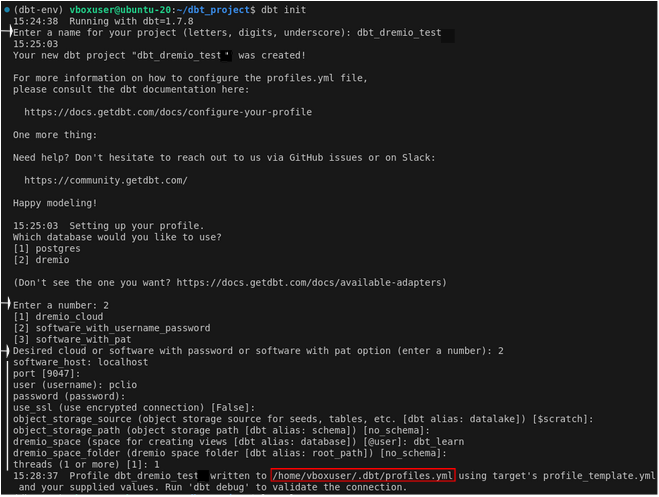
Précisions concernant les informations à renseigner
Quelques précisions concernant l’object_storage_source, l’object_storage_path, le dremio_space et le dremio_space_folder :-
- object_storage_source : il faut ici définir l’espace par défaut dans lequel les tables seront créées. Il faut que ce soit un espace de stockage capable de stocker au format iceberg. Si rien n’est spécifié, les tables seront stockées dans la source $scratch.
-
- object_storage_path : il faut ici définir le répertoire dans la source (object_storage_source) dans lequel on souhaite stocker les tables. Si rien n’est spécifié, les tables seront stockées à la racine de la source précisée précédemment. Si vous voulez préciser le chemin d’un sous répertoire il faut séparer les répertoire par un point. Par exemple :
repertoire1.sous_repertoire1.sous_sous_repertoire2.
- object_storage_path : il faut ici définir le répertoire dans la source (object_storage_source) dans lequel on souhaite stocker les tables. Si rien n’est spécifié, les tables seront stockées à la racine de la source précisée précédemment. Si vous voulez préciser le chemin d’un sous répertoire il faut séparer les répertoire par un point. Par exemple :
-
- dremio_space : il faut ici définir l’espace par défaut dans lequel les vues seront créées. Il faut donner le nom du space. Si rien n’est spécifié, les vues seront stockées dans l’espace dremio personnel de l’utilisateur.
-
- dremio_space_folder : il faut ici définir le répertoire dans le space dans lequel on souhaite enregistrer les vues. Si rien n’est spécifié, les tables seront stockées à la racine du space.
Le projet est maintenant initialisé. Lors de l’initialisation du projet un fichier profiles.yml est créé (s’il s’agit de votre 1er projet) ou modifié, dans un répertoire .dbt/, au sein de votre répertoire utilisateur (comme l’indique la dernière ligne de log de la commande dbt init). Ce fichier contient tous les profils de connexion des projets dbt. Vous pouvez y ajouter d’autres profils ainsi que d’autres environnements comme nous le verrons dans la suite de l’article.
Test de connexion et arborescence du projet
Pour vérifier la connexion avec Dremio on peut exécuter la commande dbt debug (attention, il faut se placer dans le répertoire du projet). Si une erreur survint, il faudra vérifier que les paramètres de connexion sont les bons dans le fichier profiles.yml.
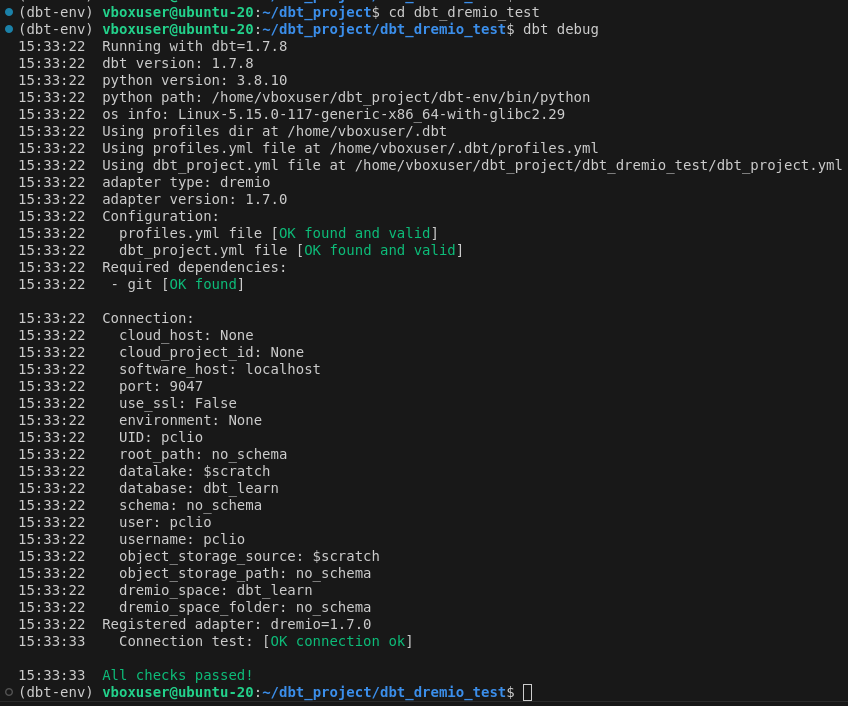
Lors de l’initialisation du projet l’arborescence suivante est créée. Un exemple est donné définissant 2 modèles (fichiers .sql) ainsi qu’un fichier de configurations (fichier .yml) pour ces modèles, sous le répertoire models/example.
.
├── analyses
├── macros
├── models
│ └── example
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
├── seeds
├── snapshots
├── tests
├── dbt_project.yml
└── README.mdNous nous intéresserons dans la suite, uniquement au répertoire models et au fichier dbt_project.yml du projet dbt.
Création d’une table ou d’une vue dans Dremio
Création de 2 modèles
Que l’on veuille créer une table ou une vue, il s’agit de construire un modèle dans dbt, un fichier .sql dans le répertoire models/ (ou .py mais les modèles écrit en python ne sont supporté que pour certains data warehouse) et de choisir ensuite comment on souhaite le matérialiser, en table ou en vue. Il existe d’autres types de matérialisation possible que l’on n’illustrera pas dans cet article (incremental, ephemeral, reflection, snapshot). Dans ce fichier sql il suffit d’écrire une requête sql comme vous le feriez dans Dremio en privilégiant leur écriture avec des CTE pour une meilleure visibilité. Et avant la requête dans un bloc config, il faudra choisir la matérialisation pour le modèle.
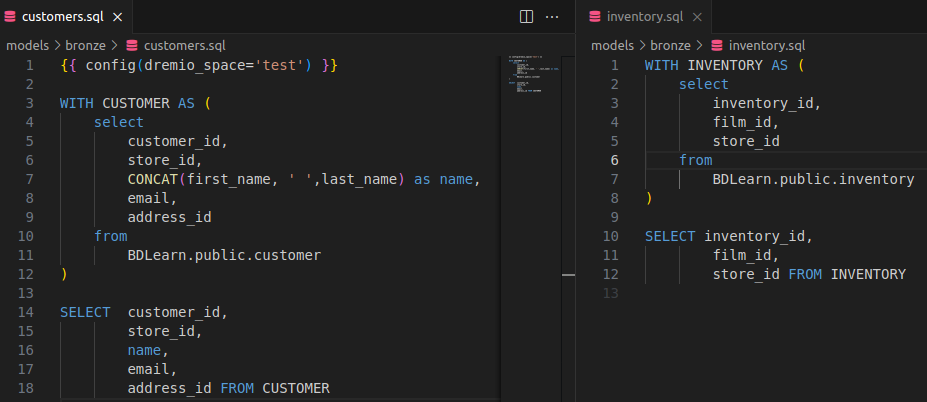
Créons notre première vue et notre première table dans Dremio. Sous le répertoire models, créons un répertoire bronze et ajoutons-y 2 fichiers .sql comme suit. Le nom des fichiers sql sera le nom de la table ou de la vue dans Dremio (il est possible de changer le nom en ajoutant un alias dans la configuration comme nous le verrons plus tard dans l’article).
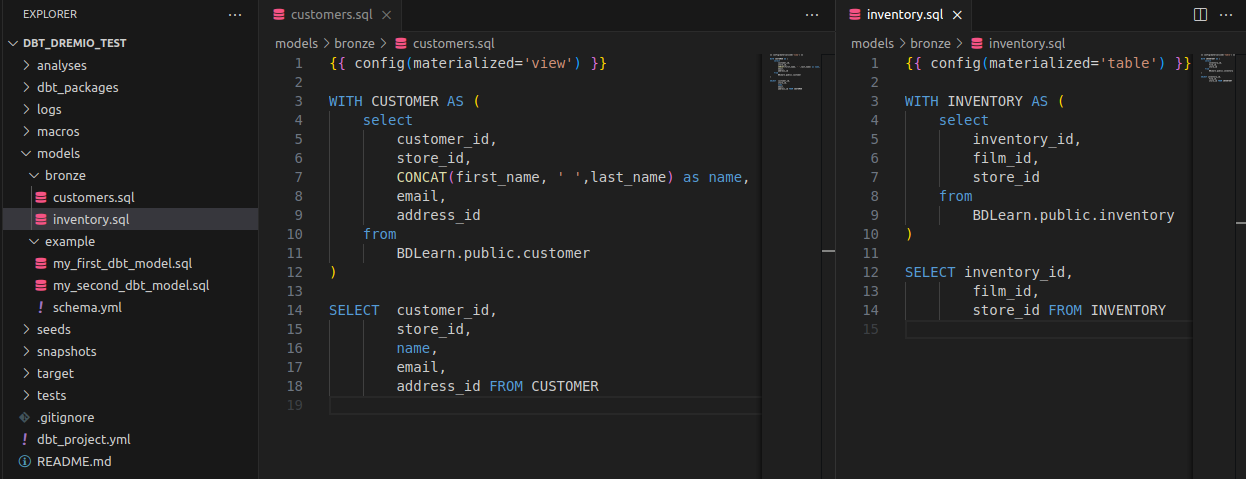
Ajoutons les maintenant dans Dremio avec la commande suivante : dbt run.
La commande dbt run va exécuter tous les modèles du projet. Mais dans l’exemple ici nous voulons exécuter uniquement les deux modèles que nous venons d’écrire. Pour cela on va exécuter la commande suivante : dbt run --select customers inventory (ou dbt run --select models/bronze).
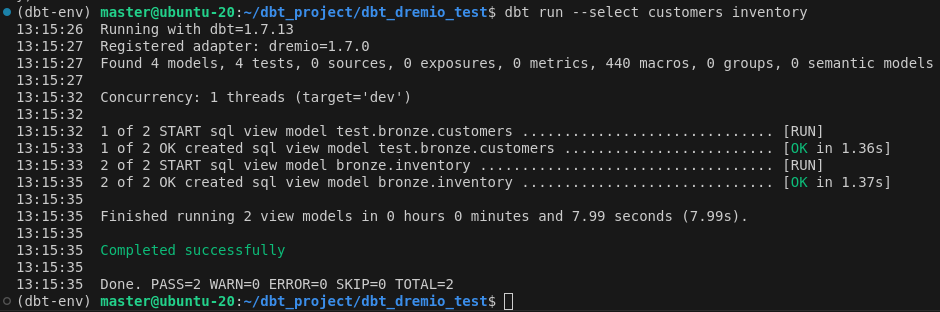
Dans Dremio, on a bien une vue dans le space dbt_learn pour le modèle customers (à la racine car nous n’avions pas précisé de répertoire lors de l’initialisation du projet). 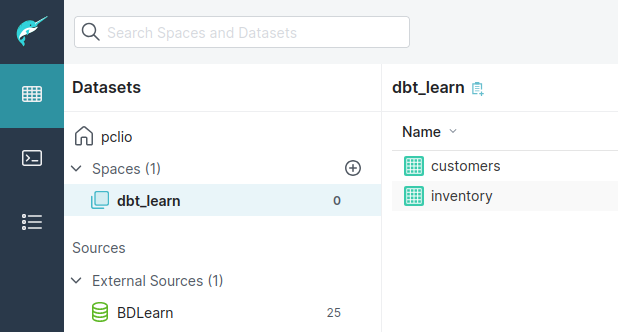

La requête envoyée à Dremio pour le modèle customers
Et on a bien une table dans $scratch pour le modèle inventory.
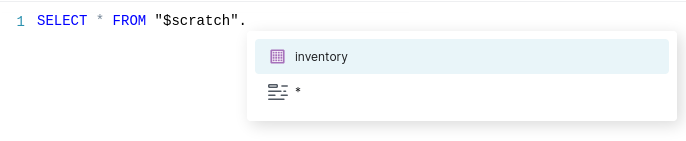

La requête envoyée à Dremio pour le modèle inventory
La stratégie twin_strategy
On peut observer que le modèle inventory a aussi été matérialisé en vue bien qu’on ait choisi “table” comme matérialisation, c’est parce qu’il existe un comportement par défaut lors de la création d’une vue ou d’une table dans Dremio. Les tables dans Dremio peuvent être créées uniquement dans un “object storage” et les vues dans Dremio ne peuvent être créées que dans un “space”. En conséquence, l’adaptateur utilise une stratégie twin_strategy pour déterminer comment gérer la création d’une vue portant le même nom qu’une table existante et vice versa.
-
- Lors de la création d’une table, une vue est aussi créée comme le reflet de la table (dans le space.répertoire configuré pour le modèle).

La requête envoyée à Dremio en plus de celle précédemment illustrée pour le modèle inventory
-
- Lors de la création d’une vue, un drop table avec le nom de la vue est effectué (dans l’object_storage_source.object_storage_path spécifié dans la configuration du modèle)

La requête envoyée à Dremio en plus de celle précédemment illustrée pour le modèle customers
Pour contrôler ce comportement, si vous souhaitez que lorsqu’une table est créée, seul la table est créée et que lorsque la vue est créée il n’y a pas de suppression de table vous pouvez choisir la valeur allow pour la configuration twin_strategy. Voir la documentation pour les différentes stratégies.
La vue et la table ont été créées à l’endroit défini lors de l’initialisation du projet (dans le fichier profiles.yml) mais il est possible de configurer pour chaque modèle ou groupe de modèles là où on veut qu’elles se trouvent dans Dremio. Regardons de plus près les fichiers dbt_project.yml et profiles.yml.
Présentation des fichiers dbt_project.yml et profiles.yml
Le fichier profiles.yml
Dans le fichier profiles.yml, on trouve les différents profils créés lors de l’initialisation d’un projet dbt (les paramètres d’un profil peuvent varier d’un datawarehouse à un autre). Il contient les informations de connexion fournies lors de la commande dbt init. Le profil utilisé dans un projet dbt est spécifié dans le fichier dbt_project.yml. Dans un profil les informations de connexion sont par défaut spécifiées pour un environnement nommé dev (en bleu) et par défaut toutes les commandes s’exécuteront dans l’environnement spécifié dans target, ici dev (en vert).
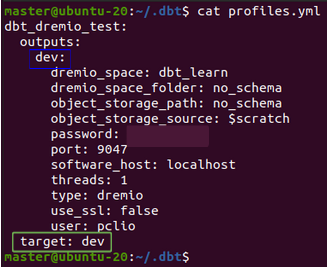

Il est possible d’éditer le fichier pour rajouter d’autre environnement (en violet). Pour exécuter les requêtes dans un autre environnement il suffira d’ajouter --target nom_env dans la commande. Pour utiliser un autre profil (en jaune), il est possible de modifier le profil à utiliser dans le fichier dbt_project.yml ou de préciser le profil souhaité en ligne de commande avec --profile nom_profil.
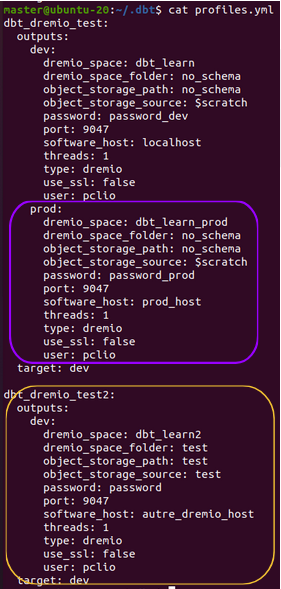
Exemple de commande :
dbt run --target prod
dbt run --profile dbt_dremio_test2 --target dev
Le fichier dbt_project.yml
Le fichier dbt_project.yml sert à définir les configurations générales du projet. Par exemple :
-
- le nom du projet (en bleu).
-
- le profil de connexion à utiliser (en vert).
-
- l’emplacement des différents répertoire du projet (en violet).
-
- la configuration des modèles à un niveau macro (en jaune). Par défaut lorsqu’une table sera créée, elle sera stockée dans le dossier de l’espace de stockage spécifié lors de l’initialisation du projet (dans le fichier profiles.yml). De même, les vues seront enregistrées dans le dossier du space spécifié dans le fichiers profiles.yml. Mais il est possible de spécifier un autre emplacement pour la créations des tables ou des vues (tout comme on a choisi le type de matérialisation pour le modèle). Nous verrons cela dans la prochaine partie.
-
- la configuration d’autres éléments présents dans les autres répertoires du projet, à l’image du répertoire models (qui ne seront pas vu ici).
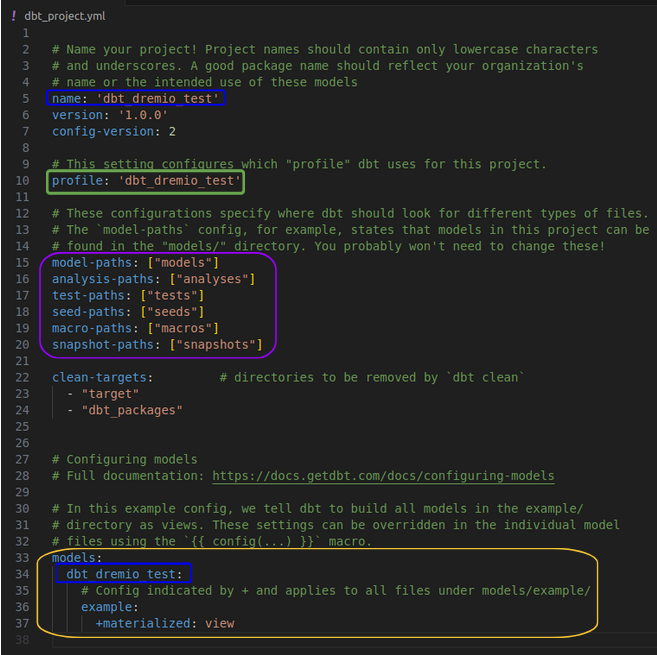
Configuration des modèles
Il est possible de définir des configurations pour les modèles à 3 endroits différents :
-
- dans le fichier dbt_project.yml
-
- dans un fichier yml à créer dans le dossier models/ (à l’initialisation du projet le fichier schema.yml sous models/example, est donnée comme exemple)
-
- dans la définition du modèle directement (dans le fichier .sql, comme nous l’avons fait précédemment pour le choix de la matérialisation)
Se référer à la documentation pour voir les différentes configurations possibles, on en illustrera quelques-unes ci-après.
Dans le fichier dbt_project.yml
Il suffit de remplir la section model à la fin du fichier yml. Dans l’exemple données au démarrage du projet, une configuration a été écrite pour que par défaut (s’il n’y a pas d’autre configuration qui viendrait écraser celle-ci) tous les modèles se trouvant dans le répertoire models/example soient matérialisés en vue. Par défaut, si aucune matérialisation n’est choisie, le modèle sera matérialisé en vue.
Il est possible de rajouter d’autres configurations. Par exemple de choisir l’emplacement dans Dremio où seront enregistrées les vues ou les tables (dans un autre emplacement que celui défini à l’initialisation du projet). Il faut utiliser les configurations suivantes :
-
- object_storage_source: <nom de l’espace de stockage>
- object_storage_path: <nom du répertoire dans l’espace de stockage>
- database ou dremio_space: <nom du space>
- schema ou dremio_space_folder: <nom du répertoire dans le space>
Dans l’exemple ci-dessous, on définit que tous les modèles sous le répertoire models/bronze seront matérialisés en vue. De plus, les modèles matérialisés en vue seront enregistrés dans un répertoire bronze dans le space dbt_learn dans Dremio, et les modèles matérialisés en table seront stockés dans l’object storage $scratch, dans le répertoire test.
On peut aussi définir la stratégie allow de twin-strategy (dont on a parlé plus haut dans l’article) pour tous les modèles du projet en l’ajoutant juste après “models:”.
Si on ajoute la même configuration à un niveau inférieur, ça écrasera la configuration définie à un niveau supérieur (attention, cela dépend de la configuration, mais c’est vrai pour celles vues dans cet article, se référer à la documentation pour plus de détail). Par exemple, si on ajoute “twin_strategy: clone” sous example, tous les modèles suivront la stratégie allow sauf ceux sous le répertoire models/example.
...
models:
+twin_stategy: allow
dbt_dremio_test:
example:
+materialized: view
bronze:
+materialized: view
+object_storage_source: $scratch
+object_storage_path: test
+database: dbt_learn
+schema: bronzeLes + devant les configurations servent à distinguer une configuration d’un répertoire, ils servent à lever une ambiguïté qui pourrait exister si par exemple le nom d’une configuration est le même que celui d’un répertoire dans le répertoire models. Sa présence n’est pas obligatoire s’il n’y a pas d’ambiguïté.
Dans un fichier yml dans le dossier models
Dans le dossier model/ du projet, il faut créer un fichier yml dans lequel on définira une configuration spécifique pour chaque modèle (on peut créer plusieurs fichiers yml, par exemple un par sous répertoire ou pour un groupe de modèles). Ces configurations écraseront celles qui auraient pu être définies dans le fichier dbt_project.yml (attention, cela dépend de la configuration, mais c’est vrai pour celles vues dans cet article, se référer à la documentation pour plus de détail).
Dans ce fichier on peut documenter les modèles et définir des tests mais nous ne le verrons pas dans cet article (le fichier schema.yml en est un exemple). Tout comme dans le fichier dbt_project.yml, on peut ajouter les mêmes configurations (twin_strategy, materialized, dremio_space, …). On peut également ajouter un alias au modèle pour définir le nom qui sera enregistré dans Dremio à la place de celui du nom du fichier sql.
Par exemple, dans le dossier models/bronze on peut créer un fichier bronze_configuration.yml avec le contenue suivant :
version: 2
models:
- name: customers
config:
alias: bronze_customers
dremio_space: test
dremio_space_folder: bronze
- name: inventory
config:
alias: bronze_inventory
dremio_space: test
dremio_space_folder: bronze
Dans la définition du modèle (bloc config)
Dans le fichier sql avant la requête il suffit d’ajouter un bloc config avec les configurations souhaitées pour le modèle (comme nous l’avons fait précédemment), séparées par une virgule : {{ config(config1=’valeur’, config2=’valeur’, …) }}
Ces configurations écraseront celles qui auraient pu être définies dans le fichier dbt_project.yml ou dans un autre fichier yml (attention, cela dépend de la configuration, mais c’est vrai pour celles vues dans cet article, se référer à la documentation pour plus de détail).
Exemple :
{{ config(materialized='table', twin_strategy='allow', dremio_space='test') }}
WITH CUSTOMER AS (
SELECT ...
)
SELECT ...Pour changer la destination dans Dremio pour les vues, il n’y a pas besoin que le space ou que les sous dossiers soient créés au préalable, s’ils n’existent pas ils seront alors créés dans Dremio (sauf dans le cas de la stratégie clone, avec la configuration materialized=’table’, s’ils n’existent pas, après la création de la table, une erreur sera levé lors de la création de la vue). De même lors de la création d’une table les répertoires (object_storage_path) au sein de l’object_storage_source n’ont pas besoin d’exister, en revanche l’object_storage_source doit exister dans Dremio.
Exemple de la création d’une vue dans Dremio en changeant les configurations par défaut
Définissons dans le fichier dbt_project.yml les configurations suivantes pour les modèles sous le répertoire models/bronze :
...
models:
dbt_dremio_test:
bronze:
+materialized: view
+dremio_space_folder: bronze
Définissons un autre space pour la sauvegarde de la vue customers, en ajoutant le bloc config suivant dans le fichier customers.sql : {{ config(dremio_space='test') }}
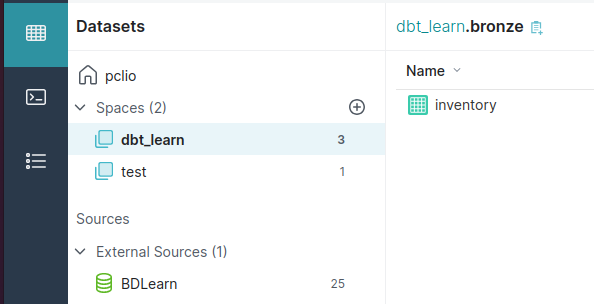
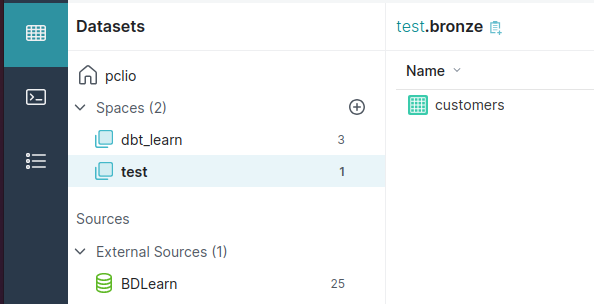
Avec ces configurations on doit trouver dans Dremio une vue inventory dans dbt_learn.bronze et une vue customers dans test.bronze. De plus, on observera que les répertoire se créeront sans que nous ayons besoin de le faire manuellement ainsi que le space test.
Ajoutons un fichier de configuration bronze_config.yml sous le répertoire models/bronze comme suit, pour changer le nom de nos vue dans Dremio.
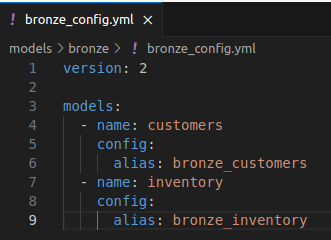
Lors de l’exécution on observe bien que le nom des vues est bien celui de l’alias défini dans le fichier de configuration. Et elles sont bien présentes dans Dremio (à noter que de nouvelles vues sont créées, les vues précédemment créées ne sont pas remplacées car elles ont un nom différent).
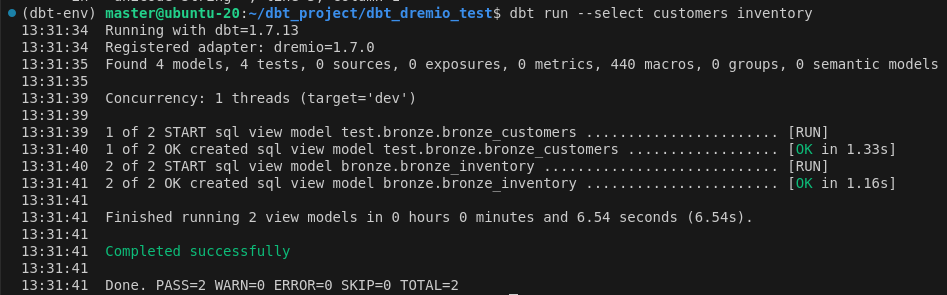
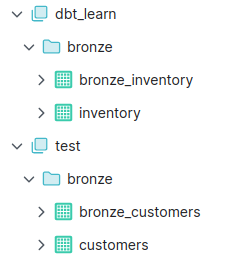
![]()
Conclusion
Dans cet article nous avons vu comment démarrer un projet dbt avec Dremio. Comment créer un modèle dans le but d’en faire une vue ou une table avec le choix de leur emplacement et différents moyens de les configurer. Nous avons également vu la fonction des fichiers dbt_project.yml et profiles.yml, et comment exécuter nos modèles d’un environnement à un autre.
Nous vous invitons maintenant à lire Dremio et les couches sémantiques avec dbt où on s’intéresse à d’autres fonctionnalités (la dépendance entre les modèles, les tests, les macros, …) et plus particulièrement à la construction de couches sémantiques dans Dremio.
Ressource pour aller plus loin :
