

ou comment le format de données Apache Iceberg transforme l’intégration et l’analyse de données.
Etes-vous aujourd’hui en mesure de prendre des décisions basées sur les faits, basées sur les données ? Avez-vous une infrastructure informatique qui dès lors qu’une donnée est produite dans votre système opérationnel, CRM, ERP, Solution de gestion qui soutient votre production… – D’autres parleraient même d’industrie 4.0. – Oui, êtes-vous équipé d’une plateforme de données capables de suivre votre activité au fil de l’eau ? Une telle infrastructure transporte et consolide vos données en quasi temps réel.
Apache Iceberg
Apache Iceberg devient au fil du temps un standard de fait pour stocker les données à vocation analytique. Né chez Netflix et Apple, Apache Iceberg a gagné marche après marche les industriels de l’analytique Snowflake, Google Cloud, AWS, Confluent. Même Databricks qui promeut un format concurrent, a indiqué l’adopter dans une couche d’abstraction qui se veut universelle.
Quelle valeur apporte Apache Iceberg ?
En matière de gestion de données il apparaît tellement évident pour chacun d’être en mesure de de modifier un schéma de table ! Néanmoins si les solutions informatiques de gestion de base de données sont prévues pour faire évoluer les structures de modèle de données, peu d’organisations mettent en œuvre ce type de processus ! D’autant plus que des auteurs comme Scott Ambler, dans Refactoring Databases décrit de manière très détaillée toutes les techniques qui rendent une base de données “agile”.
Cette capacité d’évolution y compris à l’échelle c’est tout cela que vous apporte Apache Iceberg.
Voici quelques grandes caractéristiques d’Apache Iceberg :
- Exactitude : Apache Iceberg gère les opérations d’écritures avec l’isolement nécessaires, et les mécanismes utiles qui garantissent les transactions ACID, comme dans une base de données traditionnelle. Même en cas d’échec d’écriture vos données restent intègres.
- Evolutivité : Apache Iceberg offre une flexibilisation dans la définition des structures de données telle que MongoDB ou Elasticsearch tout en s’appuyant sur la rigueur des modélisation des plus grands data warehouses. Apache Iceberg inscrit ces données dans un stockage distribué. Ici encore Apache Iceberg bénéficie de toute les évolutions qu’il y a eues au sein des architecture Big Data et celles des data lakes.
- Performances: En informatique, il est très coûteux d’ouvrir un fichier pour le lire. Bien sûr, ouvrir un fichier ne pose pas de problème. Toutefois, lorsque l’on passe à l’échelle et que le nombre de fichiers explose, il convient de faire en sorte de réduire ce nombre. Ici encore Apache Iceberg apporte des réponses face aux solutions déjà existantes…
- Ouverture : Bien sûr que Apache Iceberg est open source ! Ici, ce qu’il faut en comprendre c’est surtout que la mutualisation en facilite l’adoption en particulier parce que Apache Iceberg s’interface avec l’ensemble des cadres de développement, des solutions d’analyses… Grâce à Apache Iceberg pas d’enfermement par un fournisseur ! Dit autrement : “Pas de Vendor Locking”.
- Temps réel : compte-tenu de la performance d’une part, et de l’évolutivité d’autre part, Apache Iceberg s’inscrit parfaitement dans l’architecture quasi temps réel.
Et donc, nous y voilà : Iceberg s’est imposé et est devenu un standard. Pour Marc Sallières, Président à Synaltic, il n’y a aucun doute : Apache Iceberg apparaît désormais comme LE format “table” que vous devez considérer pour construire votre Open Data Lakehouse !

Pour aller plus loin, voici un exemple d’architecture.
De plus en plus d’architectes supportent ce type de cas d’usage. Ici, je vous propose d’explorer une architecture qui pousse les données vers le broker de données Kafka, l’amène jusqu’à Apache Iceberg pour en faciliter les analyses. Et enfin Dremio pour exploiter cette donnée.
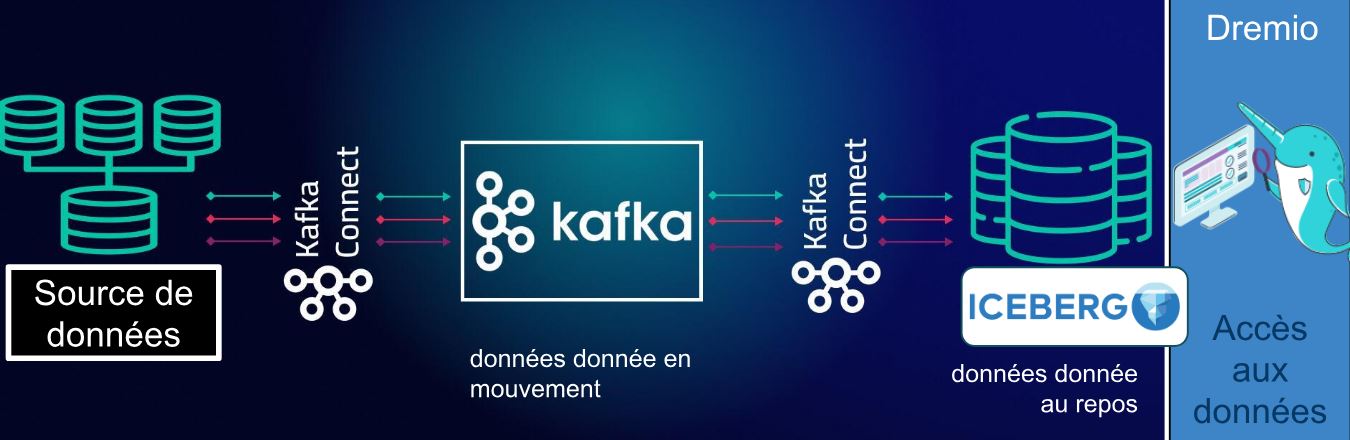
L’architecture qui est ici envisagée prend un vrai intérêt lorsque les données pas ne sont pas conservées au niveau de l’application qui les crée ! De même, des applications transactionnelles ne conservent pas toujours l’historique des changements. Ce type d’architecture prend alors tout son sens.
Pour aller plus loin : focus sur l’architecture.
Synlatic vous promet un guide complet qui contient toutes les bonnes pratiques pour vous aider dans le cadre de vos projets de gestion de données.
Maintenant que nous avons notre format de stockage, revenons sur notre architecture. Les processus de collecte ont amené la donnée jusqu’à Apache Kafka.
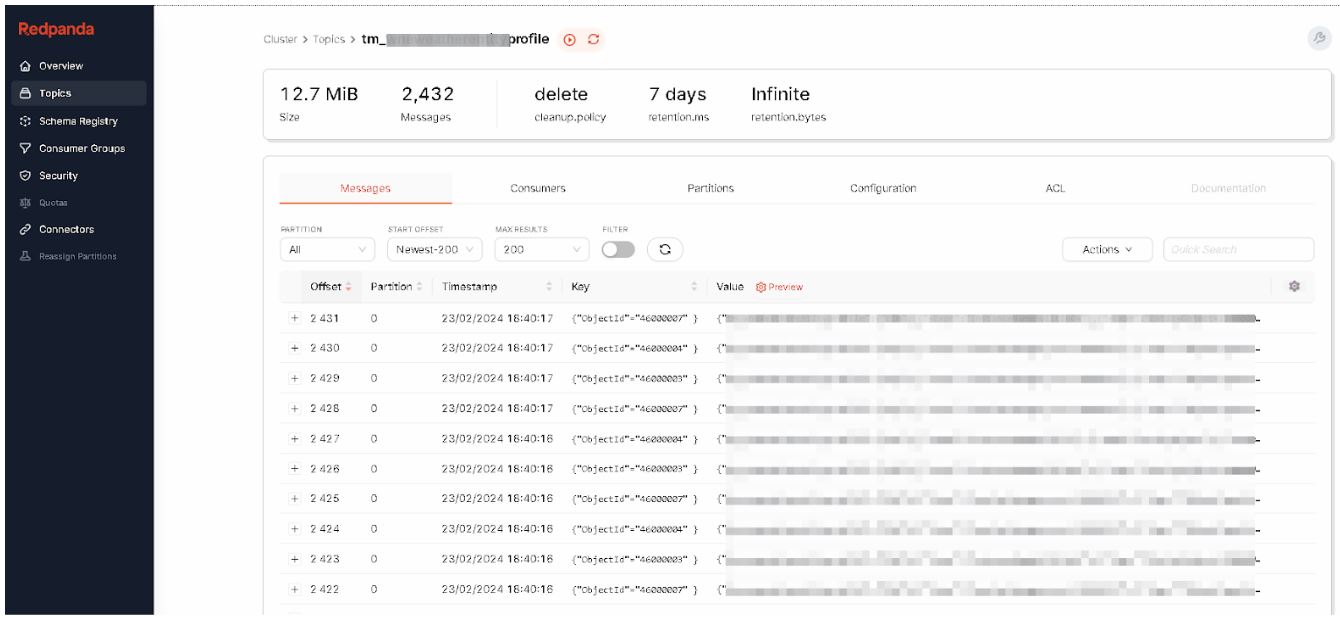 Poussons les alors vers Apache Iceberg. Nous employons le connecteur Apache Iceberg Sink de Tabular. Juste un fichier de configuration… Et hop… Vous pouvez analyser vos données.
Poussons les alors vers Apache Iceberg. Nous employons le connecteur Apache Iceberg Sink de Tabular. Juste un fichier de configuration… Et hop… Vous pouvez analyser vos données.

Et voilà, en mode low code. Les données sont maintenant dans votre stockage distribué, par exemple S3 (avec Minio).
Vous pouvez les interroger avec les outils ou framework de votre choix. Ici, nous apprécions la convivialité et les performances de Dremio. N’est-ce pas ? Nous accédons aux données depuis Dremio… Et Dremio s’inscrit en facilitateur par rapport à votre écosystème data.
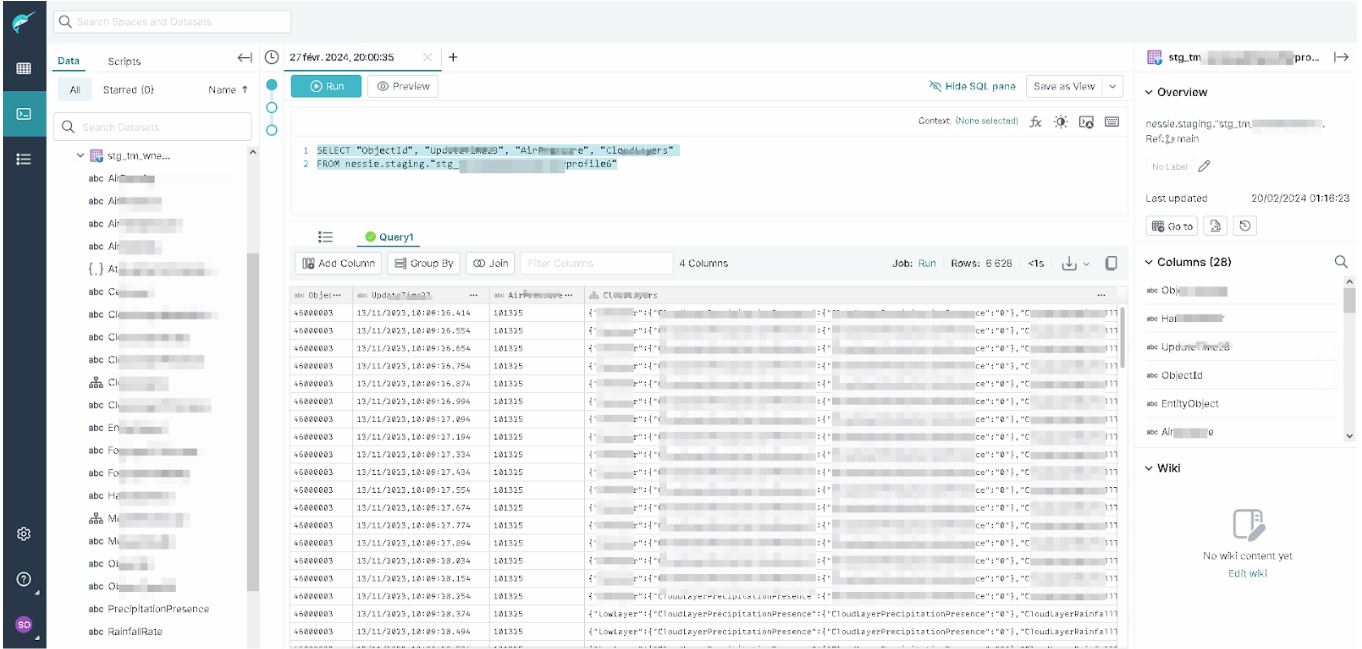
Sans doute que nous avons omis de vous dire que pour pousser la donnée vers Apache Iceberg… Nous avons créé au niveau de Dremio un schéma de données. Cette structure de données est très souple et sait accueillir des données assez hétérogènes.
Oui, le connecteur Kafka Connect Apache Iceberg Sink de Tabular peut automatiquement créer les schémas. Nous préférons les maîtriser.
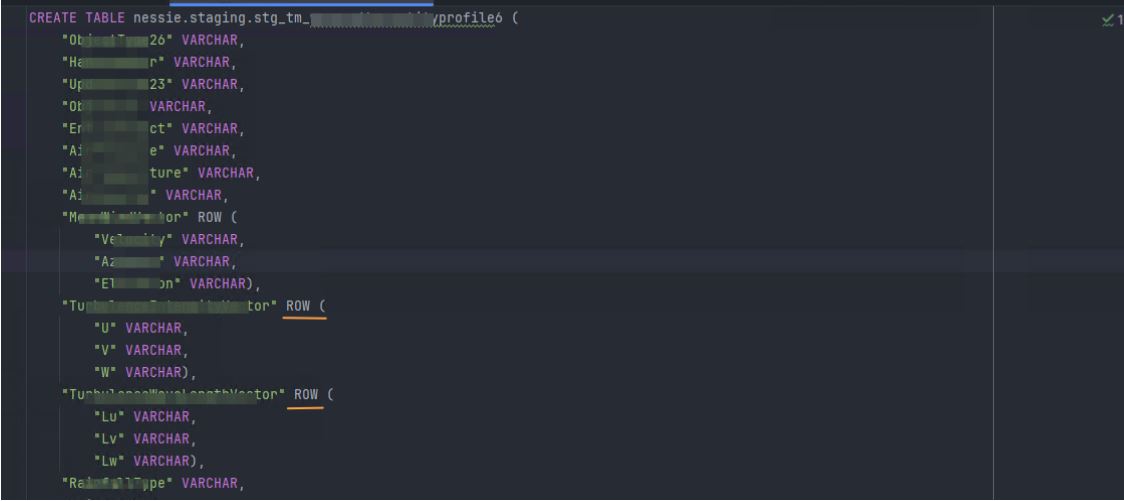 Comme vous pouvez l’observer nous avons des colonnes de type “ROW” qui structure un type complexe. Vous pouvez en déduire ici que vous allez être en mesure de stocker des données multiformes.
Comme vous pouvez l’observer nous avons des colonnes de type “ROW” qui structure un type complexe. Vous pouvez en déduire ici que vous allez être en mesure de stocker des données multiformes.
Pour revenir au connecteur Apache Iceberg Sink de Tabular.io en voilà les principales propriétés.
| Propriété | Description |
| connector.class | Le nom de classe complet du connecteur. |
| tasks.max | Le nombre maximum de tâches qui seront lancées. Toutes les partitions de la ou des sources Kafka seront réparties entre ces tâches. |
| topics | La ou les sources Kafka à partir desquels lire les données. |
| iceberg.tables | La ou les tables Iceberg dans lesquelles les données Kafka doivent être écrites. |
| iceberg.catalog | Le nom du catalogue auquel nous nous connecterons. |
| iceberg.catalog.type | Le type de catalogue avec lequel nous travaillerons (REST, Hive, Hadoop). |
| iceberg.catalog.uri | L’emplacement où nous pouvons atteindre ce catalogue. |
| iceberg.catalog.client.region | La région dans laquelle se trouve notre catalogue. |
| iceberg.catalog.s3.endpoint | Le point de terminaison de votre stockage S3 (ou équivalent). |
| iceberg.catalog.s3.path-style-access | Indique s’il faut utiliser l’accès de style chemin d’accès pour les compartiments S3. |
| iceberg.tables.auto-create-enabled | Indique s’il faut créer automatiquement les tables Iceberg lorsqu’un nouveau connecteur est lancé. |
| iceberg.tables.evolve-schema-enabled | Indique s’il faut faire évoluer le schéma de la table Iceberg si le schéma Kafka change. |
| key.converter | Une classe Java que Kafka Connect doit utiliser pour lire les clés des enregistrements Kafka. |
| iceberg.control.commit.interval-ms | À quelle fréquence le contrôleur doit valider les écritures de tous les workers, en millisecondes (par défaut : 300000). |
| value.converter | Une classe Java que Kafka Connect doit utiliser pour lire les valeurs des enregistrements Kafka. |
| value.converter.schemas.enable | Indique s’il faut utiliser un schéma associé aux enregistrements Kafka. |
Pour plus d’information sur ce connecteur, ça se passe ici : https://github.com/tabular-io/iceberg-kafka-connect

Le Lakehouse Dremio est conçu nativement pour Apache Iceberg et contribue grandement au projet Apache. Dremio est le premier Lakehouse a avoir mis à l’honneur Iceberg … ce nouveau format est en passe de devenir universel !
En résumé
Il y a 10 ans déjà que je présentais Apache Kafka à l’Open World Forum … je vous remet la vidéo ici !
Les nouvelles facilités à développer des traitements temps réel relance cette architecture et la rend accessible au plus grand nombre. En effet aujourd’hui, des solutions comme Dremio savent directement ce sourcer auprès des bases de données.
Néanmoins certaines sources créent une donnée, l’émettent sans la stocker ! Des solutions comme Debezium, Apache Kafka, Apache Kafka Connect et ici Kafka Connect Iceberg Sink deviennent essentielles pour faciliter la collecte et l’analyse quasi temps réel !
Cette notion de faible latence peut être contrôlée, avec le connecteur Kafka Connect Iceberg Sink grâce au paramètre iceberg.control.commit.interval-ms qui contrôle l’interval de temps avant qu’un snapshot Apache Iceberg ne soit validé. Et que les dernières données ne soient disponibles. Tous les trop petits fichiers qui pourraient être générés pourront par la suite être compactés pour obtenir toutes les performances des interrogations.

Update : ce qui change en juin 2024 :
