

DuckDB
Lorsque DuckDB est apparu, il a créé une véritable onde de choc. Tout le monde en a parlé. Tout le monde s’est dit qu’il incarnait l’outil par excellence, le couteau suisse pour traiter toutes ses données depuis son poste de travail.
Pour ceux qui connaissent, vous pouvez sauter la définition 😉
DuckDB est une base de données analytique ultrarapide, conçue pour l’analyse directe de vos fichiers (CSV, Excel, Parquet) sans infrastructure complexe. S’installant en quelques secondes sur un ordinateur de type poste de travail, il traite des millions de lignes avec des performances exceptionnelles ; il est idéal pour les analyses métier quotidiennes.
Compatible avec le SQL standard et des outils populaires comme Python, R ou Excel, DuckDB offre une autonomie aux équipes data, les libérant de la dépendance envers les équipes IT. Son approche « zero-maintenance » élimine les coûts de serveurs et la complexité d’administration des bases de données traditionnelles.
Pour les décideurs, DuckDB représente une opportunité d’accélérer drastiquement les analyses tout en réduisant les coûts et la dépendance technique de leurs équipes.
Apache Iceberg™
Synaltic promeut Apache Iceberg™ depuis un moment maintenant… Si vous nous suivez, vous connaissez !
Apache Iceberg™ est une solution open-source qui transforme la gestion des données dans les lacs de données. En offrant des fonctionnalités avancées comme les transactions fiables (ACID) et une gestion simplifiée des schémas, Iceberg réduit significativement les risques d’erreurs et de corruption des données, garantissant ainsi une fiabilité accrue pour les analyses stratégiques.
Sa compatibilité étendue avec les principaux moteurs analytiques (Spark, Trino, Snowflake) élimine le verrouillage technologique et facilite l’intégration dans les infrastructures existantes. Pour les décideurs, l’adoption d’Iceberg représente un investissement stratégique pour moderniser l’architecture de données, transformer des lacs de données chaotiques en plateformes gouvernées et sécurisées, et débloquer de nouvelles capacités analytiques pour une prise de décision plus rapide et éclairée. Cela permet aux équipes d’analyser de larges volumes de données en temps réel sans compromettre la cohérence ou la performance, optimisant ainsi les opérations et la compétitivité de l’organisation.
Que font DuckDB et Apache Iceberg™ ensemble ?
Un moteur analytique incontournable
DuckDB s’impose rapidement telle l’outil que tout le monde utilise pour traiter les données sur sa machine personnelle. Il y a de fortes chances que ce moteur analytique puisse être de plus en plus embarqué dans nombre de grandes solutions du marché. Comme il est devenu un moteur incontournable, si demain, Tableau ou Microsoft annonçait qu’il remplace leur moteur maison par DuckDB ce ne serait même pas une surprise.
Ainsi, sur le poste de travail, il fait tout, ce canard : exploration de données, lit tellement de sources différentes (Chargement), transforme la données (ETL), pousse la donnée là où elle est nécessaire (reverse ETL, Data Activation)… Et tellement d’extensions pour l’enrichir.
Apache Iceberg™, son catalogue, le stockage pour la centralisation des données tel un hub
Dans une pareille architecture, avec son catalogue Apache Iceberg™ vient jouer un rôle central, ou de centralisation. Il offre l’interface unique où l’on vient pousser et récupérer les données. Cette vision de l’architecture est bien connue où l’on pousse des fichiers vers un serveur FTP, un serveur de partage. Sauf qu’ici, on ne pousse pas des fichiers mais bien des données dans des tables dont on partage les “contrats” (les spécifications). Cela renvoie à la notion de schéma.
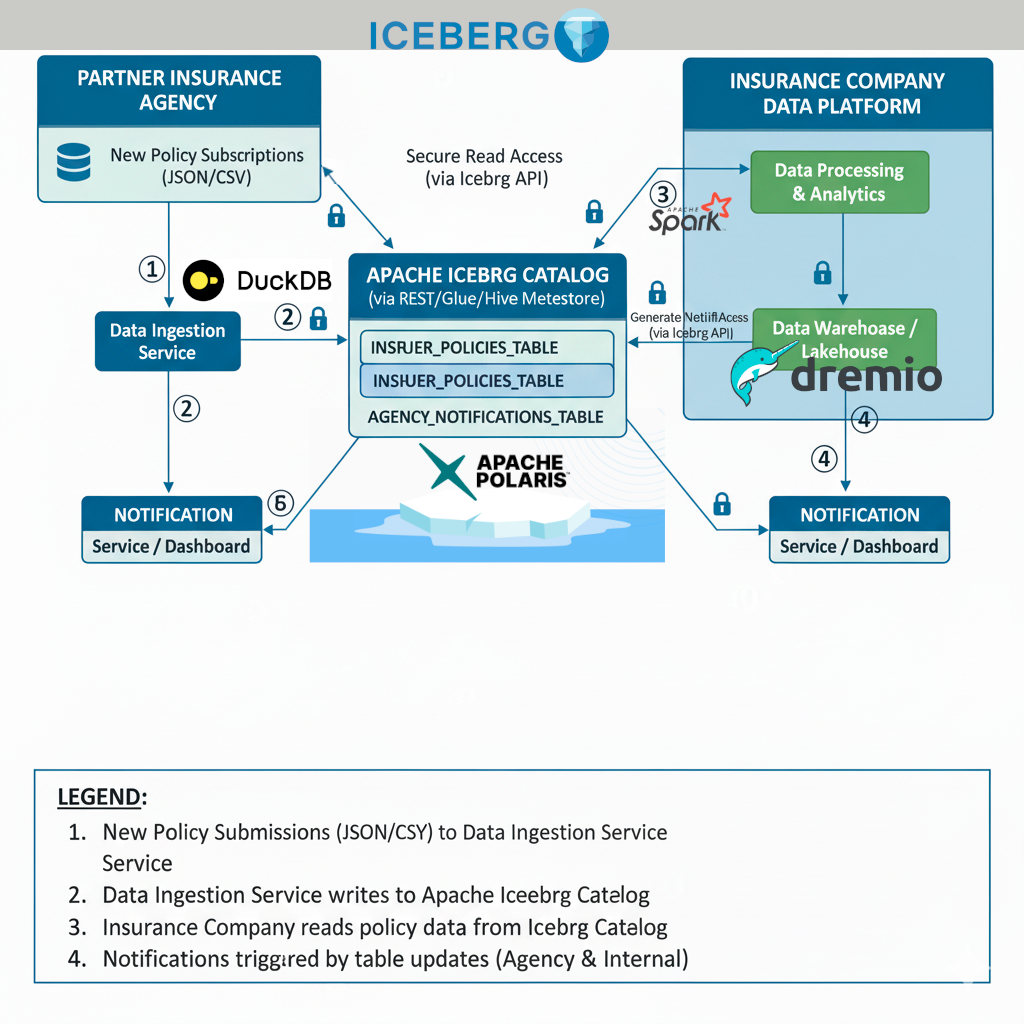
Et le maillage des données fut !
Nous arrivons au terme de notre démonstration. Un producteur de données par exemple une agence adhérente d’un réseau d’assurance vient remonter ses données du jour vers un catalogue central et sécurisé. Il pousse ses données avec son outil (client) DuckDB. La procédure est simple, rappeler les informations de connexion et partager les données sur la (les) tables qui sont autorisées. L’adhérent partage les données. L’assureur peut lire ces données par exemple avec Apache Spark et en retour partager des données à destination de l’adhérent.
Comme précisé, les données sont forcément de meilleure qualité. En effet, les traitements d’alimentation de données respectent un schéma. Ce n’est pas juste un fichier dans un répertoire ftp !
Maintenant, je vous laisse imaginer ce processus à l’échelle ! Tous les adhérents et agences respectent un “Data Contrat” dès lors qu’ils poussent la donnée vers les tables qui leur sont ouvertes. Par ailleurs, toute la richesse fonctionnelle d’Apache Iceberg vient faciliter la vie de cet assureur et des ses adhérents : la gestion des évolutions de schéma, le voyage dans le temps, la gestion des versions avec les branches et les étiquettes. Toutes ces fonctionnalités mises bout à bout vont apporter une plus grande confiance dans les données parce qu’elles permettent toutes de renforcer la qualité des données.
Plus question de faire du travail en double
Ici aussi il faut insister sur le fait que ces données qui auront ainsi transiter via ce hub, ne sont plus à recopier de nouvelles fois. En effet, elles sont déjà bien structurées, elles sont de qualité, elles sont sécurisées. Alors on ne les copie plus plusieurs fois ! Par contre, on en partage la référence, leur lien avec qui en a besoin et à qui on donne les autorisations nécessaires.
Données intermédiaires
Précédemment, les manipulations de données s’opéraient à même la base de données. Les ETLs sont arrivés, nombre de traitements qui se faisaient dans la base de données ne s’y font plus, au profit d’un stockage des données intermédiaires sous forme de fichiers sur les disques. Du point de vue de l’analyse… Et comme, il n’y avait pas d’outils pour aisément analyser ces fichiers, souvent en CSV… L’interrogation avancée de toute cette richesse n’était plus possible.
Apache Iceberg, s’inscrit dans une architecture complètement découplée. Les métadonnées, les données, le stockage, le calcul, tout est décorrélé ! On a cette chance que plusieurs moteurs d’interrogation peuvent au besoin interroger et traiter les données.
Valorisation des données intermédiaires
Pour chaque étape des traitements, la donnée peut être versionnée, notamment grâce aux branches et tags d’Apache Iceberg™. Si jusque-là l’objectif consiste à lire des fichiers et les intégrer jusqu’aux bases de données opérationnelles pour en retour livrer un fichiers de données enrichies ; aujourd’hui, la donnée intermédiaire, jamais assez considérée, peut au contraire l’être pleinement !
Grâce à Iceberg, il est maintenant possible de valoriser ces données intermédiaires. Les analyses produites sur la donnée intermédiaire sont importantes parce qu’elles fournissent un niveau d’analyse plus granulaire. Il est possible d’aboutir à une “explicabilité” à une maille plus fine. On peut comprendre un phénomène avec plus de détails.
Illustration technique
Afin d’étayer le propose nous vous détaillons un scénario où est réalisé successivement
- Agence ou Adhérent de l’assurance
- Le lancement de DuckDB
- l’ajout de l’extension Apache Iceberg™ à DuckDB
- La connexion au catalog Apache Iceberg™
- La création et l’alimentation d’une table Apache Iceberg™
- Assureur
- La connexion via Apache Spark au même catalogue Apache Iceberg™
- L’interrogation des données via park
- La mise à jour de la table initiée va DuckDB mais alimenté par Spark
Depuis la version 1.4 DuckDB supporte officiellement l’écriture dans Apache Iceberg™.
Ajout de l’extension Apache Iceberg à DuckDB
Tout d’abord on vérifie la disponibilité d’Apache Iceberg™ en tant qu’extension au sein de DuckDB.
SELECT extension_name, installed, description
FROM duckdb_extensions();
┌──────────────────┬───────────┬────────────────────────────────────────────────────────────────────────────────────┐
│ extension_name │ installed │ description │
│ varchar │ boolean │ varchar │
├──────────────────┼───────────┼────────────────────────────────────────────────────────────────────────────────────┤
│ autocomplete │ true │ Adds support for autocomplete in the shell │
│ avro │ true │ │
│ aws │ false │ Provides features that depend on the AWS SDK │
│ azure │ false │ Adds a filesystem abstraction for Azure blob storage to DuckDB │
│ core_functions │ true │ Core function library │
│ delta │ false │ Adds support for Delta Lake │
│ ducklake │ false │ Adds support for DuckLake, SQL as a Lakehouse Format │
…││ fts │ false │ Adds support for Full-Text Search Indexes │
│ httpfs │ true │ Adds support for reading and writing files over a HTTP(S) connection │
│ iceberg │ true │ Adds support for Apache Iceberg │
│ icu │ true │ Adds support for time zones and collations using the ICU library │
│ inet │ false │ Adds support for IP-related data types and functions │
│ jemalloc │ true │ Overwrites system allocator with JEMalloc │
│ json │ true │ Adds support for JSON operations │
│ motherduck │ false │ Enables motherduck integration with the system │
….├──────────────────┴───────────┴────────────────────────────────────────────────────────────────────────────────────┤
│ 27 rows 3 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘Connexion au catalog Apache Iceberg depuis DuckDB
Tout d’abord on renseigne la connexion pour le stockage objet (ici un bucket S3 (compatible))
CREATE OR REPLACE SECRET (
TYPE s3,
KEY_ID 'minio_root',
SECRET 'm1n1opwd',
REGION 'us-east-1',
ENDPOINT 'http://localhost:9000',
URL_STYLE 'path'
);
┌─────────┐
│ Success │
│ boolean │
├─────────┤
│ true │
└─────────┘Ensuite, il s’agit d’inscrire la connexion à proprement parlé vers Apache Iceberg™. Ici vers un catalogue Apache Polaris™.
CREATE OR REPLACE SECRET polaris_secret (
TYPE ICEBERG,
CLIENT_ID 'root',
CLIENT_SECRET 's3cr3t',
OAUTH2_SERVER_URI 'http://localhost:8181/api/catalog/v1/oauth/tokens',
OAUTH2_SCOPE 'PRINCIPAL_ROLE:ALL'
);
┌─────────┐
│ Success │
│ boolean │
├─────────┤
│ true │
└─────────┘Fort des secret, ainsi créé, il est possible d’établir la connexion vers Iceberg (pardon c’est un abus de langage : vers le catalog Apache Iceberg™, Apache Polaris™)
ATTACH 'quickstart_catalog' as quickstart_catalog (
TYPE ICEBERG,
ENDPOINT 'http://localhost:8181/api/catalog',
SECRET polaris_secret
);La connexion réalisée, on peut exploiter une schéme en particulier.
use quickstart_catalog.db;Parmi les tables autorisées, observons que nous pouvons bien sûr lire depuis des tables du catalogue Apache Polaris™.
On vérifie quelles sont les tables déjà à disposition.
show tables;
┌─────────────────┐
│ name │
│ varchar │
├─────────────────┤
│ dvf_2020_spark │
└─────────────────┘Combien d’éléments existent au niveau de la table dvf_2020_spark ?
select count(*) from quickstart_catalog.db.dvf_2020_spark;
┌────────────────┐
│ count_star() │
│ int64 │
├────────────────┤
│ 3514698 │
│ (3.51 million) │
└────────────────┘Création et l’alimentation d’une table Apache Iceberg™ depuis DuckDB
Avec DuckDB, il est possible de lire un fichier parquet (bien sûr ce pourrait être un fichier CSV, JSON, voire HDF5).
select *
from read_parquet('/home/ccharly/apache-iceberg-spatial/getting-started/mylocaldata/dvf-2020.parquet')
limit 10;
┌─────────────┬───────────────┬────────────────────┬─────────────────┬─────────────────┬────────────────┬───┬──────────────────────┬──────────────────────┬─────────────────┬───────────┬───────────┐
│ id_mutation │ date_mutation │ numero_disposition │ nature_mutation │ valeur_fonciere │ adresse_numero │ ... │ code_nature_cultur... │ nature_culture_spe... │ surface_terrain │ longitude │ latitude │
│ varchar │ date │ varchar │ varchar │ double │ double │ │ varchar │ varchar │ double │ double │ double │
├─────────────┼───────────────┼────────────────────┼─────────────────┼─────────────────┼────────────────┼───┼──────────────────────┼──────────────────────┼─────────────────┼───────────┼───────────┤
│ 2020-1 │ 2020-01-07 │ 000001 │ Vente │ 8000.0 │ NULL │ ... │ NULL │ NULL │ 1061.0 │ 5.323522 │ 46.171899 │
│ 2020-2 │ 2020-01-02 │ 000001 │ Vente │ 2175.0 │ NULL │ ... │ NULL │ NULL │ 85.0 │ 4.893447 │ 46.251861 │
│ 2020-2 │ 2020-01-02 │ 000001 │ Vente │ 2175.0 │ NULL │ ... │ NULL │ NULL │ 1115.0 │ 4.900028 │ 46.235305 │
│ 2020-2 │ 2020-01-02 │ 000001 │ Vente │ 2175.0 │ NULL │ ... │ NULL │ NULL │ 1940.0 │ 4.88223 │ 46.246538 │
│ 2020-2 │ 2020-01-02 │ 000001 │ Vente │ 2175.0 │ NULL │ ... │ NULL │ NULL │ 1148.0 │ 4.894481 │ 46.251841 │
│ 2020-2 │ 2020-01-02 │ 000001 │ Vente │ 2175.0 │ NULL │ ... │ NULL │ NULL │ 2960.0 │ 4.894812 │ 46.251944 │
│ 2020-3 │ 2020-01-07 │ 000001 │ Vente │ 75000.0 │ NULL │ ... │ NULL │ NULL │ 610.0 │ 5.226197 │ 46.184538 │
│ 2020-4 │ 2020-01-07 │ 000001 │ Vente │ 123.0 │ NULL │ ... │ NULL │ NULL │ 55.0 │ 5.344427 │ 46.263955 │
│ 2020-4 │ 2020-01-07 │ 000001 │ Vente │ 123.0 │ NULL │ ... │ NULL │ NULL │ 68.0 │ 5.343917 │ 46.263809 │
│ 2020-5 │ 2020-01-09 │ 000001 │ Vente │ 72000.0 │ NULL │ ... │ NULL │ NULL │ 328.0 │ 5.35055 │ 46.380885 │
├─────────────┴───────────────┴────────────────────┴─────────────────┴─────────────────┴────────────────┴───┴──────────────────────┴──────────────────────┴─────────────────┴───────────┴───────────┤
│ 10 rows 40 columns (11 shown) │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘On peut créer la table dans Apache Polaris™ (catalog Apache Iceberg™) depuis DuckDB.
CREATE TABLE quickstart_catalog.db.dvf_2020_duckdb (
id_mutation STRING,
date_mutation DATE,
numero_disposition STRING,
nature_mutation STRING,
valeur_fonciere DOUBLE,
adresse_numero DOUBLE,
adresse_suffixe STRING,
nature_culture STRING,
surface_terrain DOUBLE,
longitude DOUBLE,
latitude DOUBLE);Finalement, depuis DuckDB on alimente la table Apache Iceberg™.
INSERT INTO quickstart_catalog.db.dvf_2020_duckdb
SELECT
id_mutation,
date_mutation,
numero_disposition,
nature_mutation,
valeur_fonciere,
adresse_numero,
adresse_suffixe,
nature_culture,
surface_terrain,
longitude,
latitude
FROM read_parquet('/home/ccharly/apache-iceberg-spatial/getting-started/mylocaldata/dvf-2020.parquet');
100% ▕████████████████████████████████████████████████████████████▏On vérifie les tables accessibles : celle qui pré-existait et celle créée
show tables;
┌─────────────────┐
│ name │
│ varchar │
├─────────────────┤
│ dvf_2020_duckdb │
│ dvf_2020_spark │
└─────────────────┘Vérifions leur contenu :
- dvf_2020_spark
select count(*) from dvf_2020_spark;
┌────────────────┐
│ count_star() │
│ int64 │
├────────────────┤
│ 3514698 │
│ (3.51 million) │
└────────────────┘- dvf_2020_duckdb
select count(*) from dvf_2020_duckdb;
┌────────────────┐
│ count_star() │
│ int64 │
├────────────────┤
│ 3514698 │
│ (8.16 million) │
└────────────────┘connexion via Apache Spark™ au même catalogue Apache Iceberg™
Si toutes les premières étapes ont été effectuées du point de vue d’une agence de l’assureur ou d’un adhérent, changeons de casquette et passons du point de vue de l’informatique de l’assureur.
Ici, le client pour atteindre le catalogue Apache Iceberg est Apache Spark. La connexion se réalise par exemple comme ça.
bin/spark-sql \
--packages "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.1,org.apache.iceberg:iceberg-aws-bundle:1.9.1,org.apache.iceberg:iceberg-gcp-bundle:1.9.1,org.apache.iceberg:iceberg-azure-bundle:1.9.1" \
--conf "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" \
--conf "spark.sql.catalog.polaris=org.apache.iceberg.spark.SparkCatalog" \
--conf "spark.sql.catalog.polaris.type=rest" \
--conf "spark.sql.catalog.polaris.warehouse=quickstart_catalog" \
--conf "spark.sql.catalog.polaris.uri=http://localhost:8181/api/catalog" \
--conf "spark.sql.catalog.polaris.credential=root:s3cr3t" \
--conf "spark.sql.catalog.polaris.scope=PRINCIPAL_ROLE:ALL" \
--conf "spark.sql.catalog.polaris.s3.endpoint=http://localhost:9000" \
--conf "spark.sql.catalog.polaris.s3.path-style-access=true" \
--conf "spark.sql.catalog.polaris.token-refresh-enabled=false" \
--conf "spark.sql.catalog.polaris.header.X-Iceberg-Access-Delegation=vended-credentials" \
--conf "spark.sql.defaultCatalog=polaris" \
--conf "spark.sql.catalogImplementation=in-memory" \
--conf "spark.hadoop.fs.s3a.access.key=minio_root" \
--conf "spark.hadoop.fs.s3a.secret.key=m1n1opwd" \
--conf "spark.driver.extraJavaOptions=-Divy.cache.dir=/tmp -Divy.home=/tmp"Comme précédemment, on se connecte au schéma (pour être très démonstratif, ici, on montre comment est-ce que l’on crée un schéma).
spark-sql ()> CREATE NAMESPACE IF NOT EXISTS polaris.db ;
Time taken: 1.104 secondsOn utilise alors le schéma.
spark-sql ()> use polaris.db;
Time taken: 0.041 secondsPour rappel, depuis DuckDB la table dvf_2020_spark avait été lue. Ici revenons sur sa création et son alimentation :
- création de la table Apache Iceberg™ depuis Apache Spark™
spark-sql (db)> CREATE TABLE polaris.db.dvf_2020_spark (
> id_mutation STRING,
> date_mutation DATE,
> numero_disposition STRING,
> nature_mutation STRING,
> valeur_fonciere DOUBLE,
> adresse_numero DOUBLE,
> adresse_suffixe STRING,
> nature_culture STRING,
> surface_terrain DOUBLE,
> longitude DOUBLE,
> latitude DOUBLE)
> USING ICEBERG
> TBLPROPERTIES (
> 'format-version' = '3',
> 'write.delete.mode' = 'merge-on-read'
> );
Time taken: 1.181 seconds- alimentation d’une table Apache Iceberg™ depuis Spark
spark-sql (db)> INSERT INTO dvf_2020_spark
> SELECT
> id_mutation,
> date_mutation,
> numero_disposition,
> nature_mutation,
> valeur_fonciere,
> adresse_numero,
> adresse_suffixe,
> nature_culture,
> surface_terrain,
> longitude,
> latitude
> FROM parquet.`/home/ccharly/apache-iceberg-spatial/getting-started/mylocaldata/dvf-2020.parquet`;
Time taken: 7.385 secondsspark-sql (db)> select count(*) from dvf_2020_spark;
3514698
Time taken: 0.346 seconds, Fetched 1 row(s)Maintenant, revenons à la où l’on en était. L’agence avec DuckDB a alimenté la table dvf_2020_duckdb. D’abord, vérifiions le contenu et le nombre d’enregistrements qui s’y trouvent.
spark-sql (db)> select count(*) from dvf_2020_duckdb;
3514698
Time taken: 0.27 seconds, Fetched 1 row(s)Nous simulons le fait que des opérations d’enrichissement ont lieu du côté de l’Informatique de l’assureur. Ici nous montrons que Apache Spark™ sait lui aussi renseigner en données la table créer l’agence (avec DuckDB). Nous ré-alimentons dvf_2020_duckdb.
spark-sql (db)> INSERT INTO dvf_2020_duckdb
> SELECT
> id_mutation,
> date_mutation,
> numero_disposition,
> nature_mutation,
> valeur_fonciere,
> adresse_numero,
> adresse_suffixe,
> nature_culture,
> surface_terrain,
> longitude,
> latitude
> FROM parquet.`/home/ccharly/apache-iceberg-spatial/getting-started/mylocaldata/dvf-2021.parquet`;
Time taken: 5.616 secondsVérifions notre total d’enregistrements dans dvf_2020_duckdb :
spark-sql (db)> select count(*) from dvf_2020_duckdb;
-- 3514698 dvf-2020.parquet
-- 4649209 dvf-2021.parquet
8163907
Time taken: 0.27 seconds, Fetched 1 row(s)Nous n’avons eu recours qu’aux commandes Insert. Bien sûr vous avez accès aux différentes opérations de manipulation et de mutation de données (DML) : Update, Delete, Merge…
Conclusion : Apache Iceberg™, le catalyseur de la confiance et de la productivité data
Ce document a démontré comment l’alliance de DuckDB et Apache Iceberg transforme la gestion et l’analyse des données. Au-delà des performances techniques, c’est l’apport fondamental d’Apache Iceberg™ qui se révèle être un véritable levier pour les organisations. En instaurant des « Data Contrats » et en garantissant une meilleure qualité de la donnée grâce à sa gestion des schémas, à ses capacités de voyage dans le temps et de versioning, Iceberg renforce considérablement la confiance dans les actifs informationnels.
Cette interopérabilité sans couture, facilitée par des outils comme DuckDB et Spark, permet non seulement de réduire les coûts de stockage en évitant les duplications inutiles, mais aussi d’accélérer drastiquement les projets data. Les équipes gagnent en productivité, libérées des tâches répétitives de nettoyage et de réconciliation des données. Plus important encore, une donnée de meilleure qualité, gouvernée et sécurisée, est une donnée intrinsèquement plus pertinente et prête à l’emploi pour les applications d’intelligence artificielle. Apache Iceberg™ ne se contente pas d’organiser le lac de données, il le transforme en un hub de confiance, où chaque donnée intermédiaire est valorisée, et où l’explicabilité et la granularité des analyses posent les bases d’une innovation accélérée. En définitive, adopter Apache Iceberg™, c’est choisir l’efficacité opérationnelle, la résilience technique et la certitude d’une donnée fiable, au service d’une prise de décision éclairée et d’un avenir propice à l’IA.
