

Dremio, une nouvelle page s’ouvre ;un article rédigé par Charly Clairmont, CTO, Synaltic
Dremio, une nouvelle page s’ouvre

Voilà plus de 2 ans que Dremio s’attache à expliquer l’importance d’Apache Iceberg, ce format de données Table. Aujourd’hui, le fournisseur de Data Lakehouse évolue avec un nouveau moteur de requête SQL et un métastore de données pour les lacs de données. Ils s’appuient sur le format de table Apache Iceberg.
La conférence Subsurface Winter 2022 qui se tient le 2 et 3 Mars, organisée par Dremio est riche en intervenants réunis autour des thématiques data lake, gouvernance des données, format de données ouvertes, architecture moderne pour la gestion de données.
Pour cette première journée, la conférence a été le lieu de l’annonce et du lancement du moteur de requête Sonar (GA) et du nouveau service de gestion des métadonnées Arctic (Preview) pour la plate-forme cloud data lakehouse.
Il est à rappeler que Dremio est en train d’offrir une vision complètement renouvelée de la gestion des données. Il a depuis peu démontré cette capacité à fusionner data warehouse et data lake. L’annonce de l’évolution de l’architecture va comme rendre la donnée “fluide”.
« Facile à démarrer »
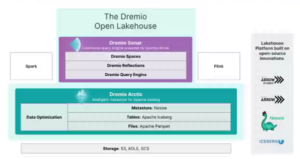
Dremio Sonar est un service gratuit conçu pour SQL qui offre toutes les performances et fonctionnalités d’un entrepôt de données sur le stockage d’objets Amazon S3. (les autres stockages distribués sont dans les cartons). Basé sur le moteur d’analyse en mémoire en colonne Apache Arrow, Dremio Sonar est 68 % plus rapide que son prédécesseur ; prend en charge les insertions, les mises à jour, les suppressions et les transactions ; ou « toutes les opérations que vous pouvez effectuer dans une requête d’entrepôt de données », a déclaré Tomer Shiran. En effet, cela permet aux utilisateurs d’exécuter des charges de travail de Business Intelligence directement sur le Lakehouse.
Comme Git pour les données : une donnée fluide !
Dremio Arctic est un autre service gratuit basé sur le format de table d’analyse open source Apache Iceberg et le catalogue de données Nessie ; qui offre une expérience de type Git pour le data lakehouse. Git est un système de contrôle de version distribué open source apprécié pour ses capacités d’instantané.
Tomer Shiran, dans son discours, a également présenté publiquement Dremio Arctic, qu’il a décrit comme un métastore intelligent pour Apache Iceberg.
Le métastore Dremio Arctic simplifie donc l’ingénierie et l’analyse des données. Il rend l’expérience de travail avec des workflows de données similaire à celle du code source en développement informatique. Cela inclut la création de branches pour l’ingestion de données ; la transformation et l’expérimentation de manière isolée ; la possibilité de reproduire des tableaux de bord historiques ou des modèles d’apprentissage automatique sans conserver de copies de données et une interface de type GitHub.
Tomer Shiran a expliqué qu’Arctic fonctionnera avec d’autres moteurs de requête de lac de données, notamment Apache Spark , Trino et Presto , et pas seulement Dremio Sonar.
L’objectif de Dremio est donc de créer un metastore moderne pour les déploiements de data lakehouse.
Construire le lac de données pour remplacer les entrepôts de données

Doug Henschen, un VP analyste de Constellation, a noté que Dremio était un innovateur dans le domaine des lacs de données cloud depuis l’introduction d’Apache Arrow en 2016. Il a plus récemment déclaré qu’il considérait la nouvelle fonctionnalité que Dremio a dévoilée aujourd’hui. Elle est destinée aux professionnels de la BI et de l’analyse.
Par exemple, il a noté que Dremio améliore sa plate-forme avec des fonctionnalités supplémentaires de mise à jour (sql update) ; de suppression de données (sql delete). Ces derniers remplissent la capacité de manipulation complète au niveau des enregistrements. C’est ce les professionnels des données attendent d’une plate-forme de type entrepôt de données.
Avec le Data Lakehouse, plutôt que d’apporter des données dans un moteur de requête ; les utilisateurs amènent les moteurs de requête aux données ; un concept introduit avec Hadoop. Ainsi, les données stockées dans le stockage d’objets cloud, comme Amazon S3, peuvent être interrogées par différentes technologies et les utilisateurs n’ont pas à déplacer et à copier les données dans un entrepôt de données pour les utiliser.
Toutes les informations que nous relayons au sujet de Dremio depuis quelques années maintenant n’ont pas vocation à promouvoir Dremio uniquement pour les grandes organisations. Toutes ces fonctionnalités d’accès aux données et ici désormais d’analyse de données pour tous sont bien accessibles depuis la petite PME jusqu’à la très grande organisation. C’est en effet la force de l’open source et ce qui fait aussi de Dremio une solution très versatile.
Pour apprendre à utiliser Dremio, vous pouvez suivre une formation Dremio avec nos experts certifiés !
– – – – – – – – – – – – – – –

Découvrez comment nous accompagnons Le Point dans le déploiement de son Data Hub ; plate-forme de centralisation de données comme point d’accès unique à la donnée. Nous travaillons avec les équipes de l’hebdomadaire ; de la conception des maquettes des tableaux jusqu’à leur déploiement et leur maintenance. La retranscription de toutes les étapes de ces 3 années de projets ; qui aura permis à Le Point de disposer de données agrégées et rapidement interrogeables.
