

Concepts Apache Airflow® – Planification et variables du DAG, un article rédigé par Charly Clairmont, CTO, Synaltic
Concepts Apache Airflow® – Planification et variables du DAG
Voilà quelques temps déjà que nous employons Apache Airflow® chez Synaltic. Nous n’avions jamais pris le temps de vous en parler. C’est pourquoi, ici, nous allons vous présenter Airflow. Nous allons apporter à la fois une vue d’ensemble et un point de vue détaillé des concepts et principes avancés. Le but étant d’écrire des plans d’exécution et de traiter efficacement vos données qui alimentent vos data warehouses, vos environnements de Master Data Management (MDM) et autre Customer Data Platform (DMP, CDP).
Vous ne connaissez peut-être pas Airflow, c’est l’un des orchestrateurs de pipelines de traitements de données en open source les plus employés. Il est donc simple à mettre en œuvre.
Nous allons donc commencer par quelques concepts fondamentaux.
1- Planification et déclencheurs
Airflow est livré avec un planificateur très mature et stable qui est responsable de l’analyse des DAG (vos plans d’exécution) à intervalles réguliers et de la mise à jour des modifications éventuelles apportées à la base de données. Le planificateur continue d’interroger les tâches prêtes à être exécutées (si les dépendances sont satisfaites et la planification possible) et les met en file d’attente pour l’exécuteur. Il y a plusieurs choses à garder à l’esprit lors de la planification d’un DAG.
a- Date d’exécution
La date d’exécution “execution_date“ est la date et l’heure logiques auxquelles le DAG Runs (instanciation d’un plan d’exécution) et ses instances de tâche s’exécutent. Cela agit également comme un identifiant unique pour chaque DAG Run.
b- Date de début
Lors de la création d’un DAG, il est possible de fournir une date de début à partir de laquelle le DAG doit s’exécuter.

La date de début vient donc indiquer la date à laquelle l’exécution démarre. Toutefois, l’instant à laquelle démarrera vraiment le job est la date de début à laquelle s’ajoute l’intervalle.
Dans l’exemple ci-dessus, la date de début est le 1er janvier 2022. Donc cela laisse à penser que la première exécution aura lieu à 00h00 le même jour. Mais ce n’est pas le cas avec Airflow, la première instance sera exécutée à un intervalle planifié ; après la date de début, c’est-à-dire à 01h00 le 1er janvier 2022. Il s’agit d’un problème courant rencontré par les utilisateurs d’Airflow qui essaient de comprendre pourquoi leur DAG ne fonctionne pas.
Il est également recommandé d’utiliser des dates-heures statiques au lieu de dates dynamiques comme time.now() car les dates dynamiques peuvent provoquer des incohérences. Lorsqu’il s’agit de savoir si la date de début à laquelle on ajoute un intervalle de planification est conforme à la nouvelle date d’exécution : la réévaluation de la date de début (si celle-ci est dynamique) perturbe le calcul de l’instant où le lancement de la tâche doit réellement s’opérer.
c- Règles de déclenchement
Airflow fournit plusieurs règles de déclenchement qui peuvent être spécifiées dans la tâche. En fonction de la règle, le planificateur décide d’exécuter ou non la tâche.
Voici une liste de toutes les règles de déclenchement disponibles et leur signification :
- all_success : (par défaut) tous les parents doivent avoir réussi.
- all_failed : tous les parents sont dans un état d’échec ou en amont_failed.
- all_done : tous les parents ont terminé leur exécution.
- one_failed : se déclenche dès qu’au moins un parent a échoué, il n’attend pas que tous les parents aient fini.
- one_success : se déclenche dès qu’au moins un parent réussit, il n’attend pas que tous les parents aient fini.
- none_failed : tous les parents n’ont pas échoué (failed ou amont_failed) c’est-à-dire que tous les parents ont réussi ou ont été ignorés.
- none_failed_or_skiped : tous les parents n’ont pas échoué (failed ou amont_failed) et au moins un parent a réussi.
- none_skiped : aucun parent n’est dans un état ignoré, c’est-à-dire que tous les parents sont dans l’état success, failed, ou amont_failed.
- dummy : les dépendances sont juste pour le show, se déclenchent à volonté.
d- depend_on_past
depend_on_past est un argument qui peut être transmis au DAG. Il garantit que toutes les tâches attendent la fin de leur exécution précédente avant de s’exécuter à nouveau. Bien que cela puisse parfois être utile pour garantir qu’une seule instance d’une tâche s’exécute à la fois ; cela peut parfois conduire à manquer des SLA et à des échecs en raison d’une exécution échouée qui bloque les autres. Ainsi, cette fonctionnalité doit être utilisée avec prudence.
2- Variables et connexions
Les variables dans Airflow sont un moyen générique de stocker et de récupérer du contenu ou des paramètres en tant que simple tableau de clés-valeur dans Airflow. Les variables peuvent être répertoriées, créées, mises à jour et supprimées à partir de l’interface utilisateur (Admin -> Variables), du code ou de la CLI. De plus, les fichiers de paramètres JSON peuvent être téléchargés en masse via l’interface utilisateur.
Le code DAG et les constantes ou variables associées doivent principalement être stockés dans le gestionnaire de source (Git) pour un examen approprié des modifications. Mais parfois, il peut être utile d’avoir des variables ou des configurations dynamiques qui peuvent être modifiées à partir de l’interface utilisateur au moment de l’exécution.
Voici quelques exemples de variables dans Airflow :
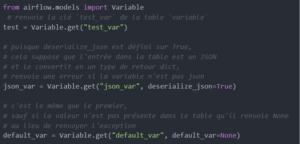
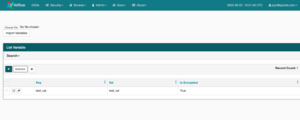
Variables sur le serveur Web Airflow
Les connexions sont un moyen de stocker les informations nécessaires pour se connecter à des systèmes externes. Ces informations sont donc conservées dans la base de données des métadonnées d’Airflow et peuvent être gérées dans l’interface utilisateur (Menu -> Admin -> Connexions). Un identifiant de connexion (conn_id) y est défini, et les informations nom d’hôte / login / mot de passe / schéma y sont attachées. Les pipelines de flux d’air récupèrent les informations sur les connexions gérées de manière centralisée en spécifiant le conn_id approprié. Les champs sensibles comme les mots de passe peuvent être chiffrés dans la table des connexions de la base de données.
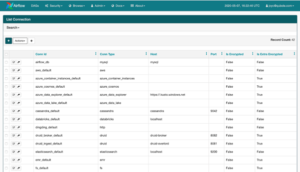
Liste de connexion sur le serveur Web
3- Pools et files d’attente
Les pools dans Airflow sont un moyen de restreindre l’exécution simultanée de plusieurs tâches concurrentes dont les ressources sont limitées. Pour ainsi éviter que le système ne soit submergé. Les pools sont utilisés pour limiter le nombre d’exécutions parallèles d’un ensemble de DAG ou de tâches. Il s’agit également d’un moyen de gérer la priorité de différentes tâches en s’assurant qu’un certain nombre de slots d’exécution sont toujours disponibles pour certains types de tâches. On peut créer ou gérer la liste des pools à partir de la section Admin du serveur Web Airflow et le nom de ce pool peut être fourni en tant que paramètre lors de la création de tâches.
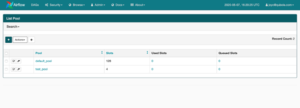
Liste des pools sur le serveur Web Airflow
Voici un exemple de la façon dont les pools peuvent être spécifiés au niveau de la tâche ; pour indiquer quelle tâche doit s’exécuter sur quel pool.

Comme mentionné précédemment, les pools d’Airflow peuvent également être utilisés pour gérer la priorité des tâches. Ceci peut être réalisé à l’aide du paramètre priority_weight. Il définit la priorité d’une tâche au sein d’une file d’attente ou d’un pool comme dans ce cas. Sa valeur par défaut est 1 mais peut être augmentée à n’importe quel nombre ; plus la valeur est élevée, plus la priorité est élevée. Lors du choix de la prochaine tâche à exécuter, le poids prioritaire d’une tâche avec les poids de toutes les tâches en aval est utilisé pour les trier au sein de la file d’attente. Si une tâche est importante et doit être hiérarchisée, sa priorité peut être augmentée jusqu’à un nombre supérieur au priority_weight des autres.
Les tâches d’un pool sont planifiées comme d’habitude pendant que tous les créneaux se remplissent. Une fois la limite du pool atteinte, toutes les tâches exécutables passent à l’état de file d’attente. Toutefois elles ne sont pas récupérées par l’exécuteur car aucun emplacement n’est disponible dans le pool. Une fois que les slots commencent à se libérer, les tâches en file d’attente sont triées sur la base de priority_weight et celle avec la priorité la plus élevée est sélectionnée pour exécution.
La file d’attente
Les instances des Dags sont enregistrés dans un gestionnaire de fil d’attente. Dans l’architecture d’Airflow, il s’agit de Celeri (coupé à Redis ou RabbitMQ). Les tâches à exécuter le sont au travers de worker : des machines où sont lancés les tâches. Lors du démarrage d’un worker à l’aide de la commande airflow worker, une liste de files d’attente peut être fournie. Les tâches peuvent être envoyées à différentes files d’attente ou alors elles peuvent exploiter un mécanisme d’étiquetage ; pour s’assurer qu’un type de tâches est bien exécuté par un type de machine. (ici l’étiquette c’est le pool)
4- SLA
Le respect du niveau de service (SLA) représente le délai d’exécution d’une tâche ou d’un DAG et peut être défini au niveau d’une tâche en tant que durée maximale. Si une ou plusieurs instances n’ont pas réussi à ce moment-là, alors, un e-mail d’alerte est envoyé. Il détaille la liste des tâches qui ont manqué leur SLA. L’événement est également enregistré dans la base de données et mis à disposition dans l’interface utilisateur Web sous Browse->SLA Misses où les événements peuvent être analysés et documentés. Des mécanismes de notifications via des messageries instantanées peuvent être employés également.
Les SLA dans Airflow peuvent être configurés pour chaque tâche via le paramètre sla. En cas de violation du SLA pour cette tâche spécifique, Airflow envoie par défaut une alerte par e-mail aux adresses mails spécifiées dans le paramètre email_list de la tâche.
En cas de violation du SLA, il existe une option pour effectuer des opérations personnalisables en passant un python appelable au paramètre sla_miss_callback de cette tâche.
5- Gabarit Jinja
Airflow tire parti de la puissance de Jinja Templating ; c’est un outil puissant à utiliser en combinaison avec des macros. Les modèles Jinja permettent de fournir du contenu dynamique ; à l’aide de code python à des objets autrement statiques comme des chaînes. Étant donné que les macros d’Airflow sont évaluées pendant l’exécution de la tâche, il est possible de fournir des paramètres qui peuvent changer pendant l’exécution. Par exemple, passer le résultat d’un opérateur à un autre qui le suit.
En outre, des paramètres comme par exemple les dates d’exécution peuvent être transmis aux champs. Tous les opérateurs définissent certains des champs pouvant être modélisés, et seuls ces champs peuvent prendre des macros en entrée.

Dans l’exemple ci-dessus, nous exécutons une commande bash qui imprime la date d’exécution actuelle et qui utilise une méthode intégrée ds_add pour ajouter 2 jours à cette date.
Voici une liste de tous les macros et méthodes disponibles par défaut dans Airflow. Avec toutes ces connaissances sur les différents concepts d’Airflow, vous êtes maintenant équipés pour commencer à écrire votre premier pipeline Airflow ou DAG. Dans notre prochain blog, nous allons rédiger un DAG avec tous ces concepts avancés ; le programmer et suivre sa progression pendant quelques jours.
Toute la #SynalTeam sera heureuse de vous partager ses connaissances dans le cadre de vos projets. Venez nous parler de l’utilisation que vous avez avec Airflow ; l’un des meilleurs planificateur de tâches et ce en open source !
Pour apprendre à utiliser Airflow, vous pouvez suivre tout simplement une formation Apache Airflow.
