

Parce que je voulais comprendre qui est finalement Trino et en particulier pour un usage d’applications analytiques orientées utilisateur où l’expérience interactive est critique.
Je pense que mon premier Whoar avec Presto remonte au moment où je configure une source de type Apache Kafka ! Et là je requête les données en mouvement… Mais ça s’arrête là. Je comprends que le moteur est vraiment intéressant pour réaliser des processus ETL mais il ne répond pas à mon cas d’usage de type analyses interactives pour le décisionnel. Et je vais croiser la route de Dremio…
Mai 2017 – Presto ou comment simplifier l’accès et les traitements des données hétérogènes : https://www.synaltic.fr/blog/test-prestodb-rd-synaltic
Introduction : L’héritage détermine l’usage
Trino (initialement Presto, créé par Facebook en 2012) a été conçu pour remplacer Hive et accélérer les requêtes ETL massives sur HDFS, en se concentrant sur la fédération de données et les requêtes complexes sur de grands volumes. Son architecture distribuée et « share-nothing », qui sépare le calcul du stockage, le rend scalable pour l’ETL. Cependant, cette conception, combinée à sa nature « stateless » et sa dépendance aux métadonnées externes, introduit une latence significative, rendant difficile l’atteinte de latences sub-seconde pour les tableaux de bord BI interactifs.
Les forces de Trino
Trino se distingue comme un cadre ETL/ELT (Extract, Transform, Load / Extract, Load, Transform) extrêmement puissant et sans état, conçu pour orchestrer des transformations de données complexes à l’échelle. Sa force réside dans sa capacité à agir comme un moteur de fédération de données inégalé, permettant d’interroger simultanément et de manière transparente une multitude de sources hétérogènes – qu’il s’agisse de bases de données relationnelles comme MySQL et PostgreSQL, de systèmes NoSQL comme Cassandra et MongoDB, ou de lacs de données basés sur HDFS, S3, Iceberg et Delta Lake – le tout via une interface SQL ANSI standard.
Cette adhésion au SQL, le langage universel de la donnée, est un atout majeur. Elle permet aux ingénieurs et analystes de données de tirer parti de leurs compétences existantes pour manipuler, transformer et intégrer des données sans avoir à apprendre de nouveaux langages ou outils propriétaires pour chaque source. Trino prend en charge les opérations DML (Data Manipulation Language) telles que INSERT, UPDATE, DELETE, et MERGE sur les connecteurs compatibles, simplifiant considérablement les tâches de modification de données qui étaient auparavant complexes dans les environnements distribués.
Is Trino the PostgreSQL of Analytics? : https://sanjmo.medium.com/is-trino-the-postgresql-of-analytics-cb263b0fa98e
L’Architecture des Métadonnées de Trino : État Actuel et Goulots d’Étranglement
Le défi des métadonnées en RAM : Volatilité, scalabilité limitée et coût mémoire
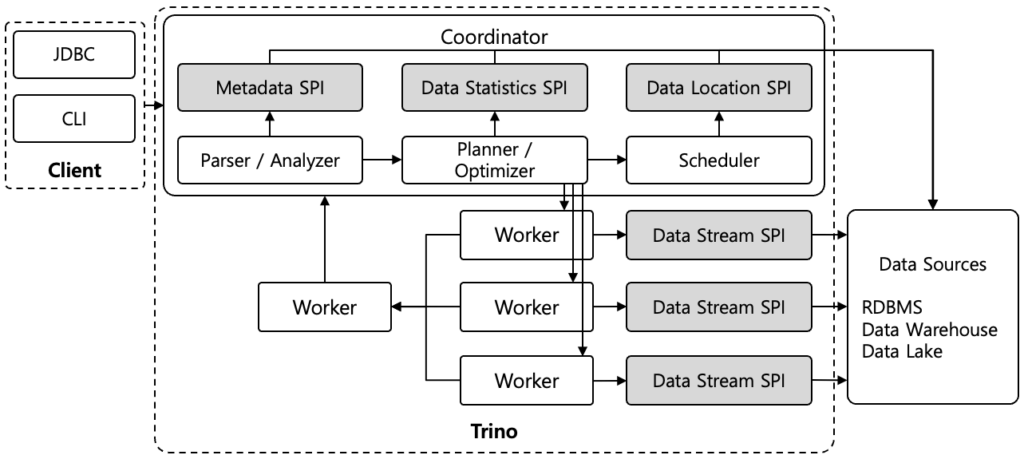
Actuellement, Trino stocke ses informations clés (comme la structure des bases de données et des tables) principalement dans la mémoire vive (RAM) de son composant principal, le coordinateur.
Cela pose plusieurs inconvénients :
- Un point de défaillance unique : Si le coordinateur s’arrête ou redémarre, toutes les informations sont perdues et doivent être rechargées. Trino est alors temporairement lent au démarrage (on parle de « cold starts« ).
- Une capacité limitée : La quantité de données que Trino peut gérer est limitée par la quantité de RAM disponible sur le coordinateur.
- Un coût élevé pour la mémoire : Stocker toutes ces informations en RAM est coûteux en ressources informatiques.
- Des lenteurs pour les utilisateurs : Pour les outils d’analyse de données (BI) qui consultent souvent la structure des données, l’absence de système de cache partagé et permanent entraîne des délais d’attente importants.
En somme, le système actuel est fragile et empêche Trino de se développer et de fonctionner de manière optimale, surtout pour les applications qui nécessitent un accès rapide aux informations de la base de données.
L’absence de persistance locale et de synchronisation des métadonnées
Trino ne dispose pas de stockage persistant pour les métadonnées, s’appuyant sur des systèmes externes (Hive Metastore, AWS Glue) et les récupérant à la demande via des connecteurs. Cette architecture « stateless » et « share-nothing » évite à Trino d’être un point de défaillance unique pour les données, mais déplace cette charge vers les metastores externes. La récupération « à la demande » peut entraîner des délais si les métadonnées ne sont pas dans le cache du coordinateur. Trino est un moteur de requête au-dessus d’un lakehouse, dépendant d’autres composants pour ses métadonnées, ce qui nécessite une optimisation architecturale globale. Par exemple, les formats table Apache Iceberg, Delta Lake, Hudi sont incités à porter les statistiques… Mais l’on comprend aussi qu’il n’y aurait aucun intérêt que chaque moteur calcul et recalcul les statistiques. Surtout si chacun des moteurs renvoient ses propres résultats. C’est justement le cas aujourd’hui pour ce qui est de Trino et de Hive qui exploite le même metastore.
Les différentes distributions commerciales de Trino ou Presto corrigent ces limites.
La reconstruction systématique des plans d’exécution et l’impact sur la latence
Trino reconstruit son plan d’exécution à chaque requête, sans cache existant pour les plans ou les résultats, ce qui entraîne une latence importante due au calcul redondant, surtout pour les requêtes BI répétitives. Chaque requête implique un surcoût de planification (parsing, analyse sémantique, optimisation (Cost Based Optimizer), distribution) estimé entre 20 et 50 ms chez Uber. Cette absence de cache empêche Trino d’atteindre des temps de réponse sub-seconde, même pour les données «chaudes», car le plan est toujours «froid». Cela démontre que Trino est optimisé pour les requêtes ad-hoc et exploratoires, et non pour les requêtes répétitives et interactives typiques de la BI, nécessitant alors des solutions externes ou acceptant des latences plus élevées.
Trino excelle dans les cas d’usage pour lesquels il a été conçu. À l’origine, Facebook a développé Presto (les origines de Trino) pour surmonter les lenteurs de MapReduce. Ils ont créé un moteur SQL sans état, s’appuyant sur le metastore de Hive, un choix architectural que Trino Open Source a conservé. Trino est idéal pour les traitements ETL.
Les Améliorations Récentes (2024-2025) : Progrès et Persistance des Défis
Les versions récentes de Trino (2024-2025) ont apporté des améliorations significatives, mais les limitations fondamentales précédemment décrites persistent.
Avancées significatives dans le caching
Mars 2024 a vu l’introduction du cache de système de fichiers Alluxio, améliorant les performances des catalogues Delta Lake, Hive, Iceberg, et bientôt Hudi. Dune a constaté une accélération de 20% des requêtes TPC, une augmentation de 30% de la vitesse de la phase d’analyse pour les tables Iceberg, et une réduction de 70% des requêtes S3 GET. En mai 2024, le support du cache de métadonnées Glue a été ajouté. En août 2024, les performances de planification des requêtes Iceberg ont été améliorées grâce à la mise en cache des fichiers de métadonnées sur le coordinateur (désactivable via iceberg.metadata-cache.enabled à false dans la version 454). Ce cache est basé sur l’immutabilité des fichiers de métadonnées Iceberg, éliminant le besoin de rafraîchissement constant.
Alluxio Webinar | 10x Faster Trino Queries on Your Data Platform : https://fr.slideshare.net/slideshow/alluxio-webinar-10x-faster-trino-queries-on-your-data-platform-6ba9/270003782
Corrections de bugs et optimisations ciblées
Des corrections de bugs critiques ont été apportées, notamment la résolution des temps de planification rares et longs lorsque le cache du metastore Hive est activé dans la version 458 (septembre 2024). La procédure flush_metadata_cache a été améliorée pour inclure le vidage du cache de statut de fichier. Le cache Delta Lake a également été optimisé en décembre 2024, avec une réduction de l’utilisation de la mémoire du coordinateur pour le cache de métadonnées des tables Delta et l’activation de la configuration delta.metadata.cache-max-retained-size pour contrôler l’utilisation de la mémoire. De plus, l’utilisation du cache de système de fichiers sur le coordinateur Trino est désormais possible lorsque node-scheduler.include-coordinator est activé (version 449).
Les limitations fondamentales qui persistent
Malgré ces avancées, les problèmes fondamentaux des métadonnées de Trino persistent. Les métadonnées sont en mémoire volatile sur le coordinateur, sans stockage persistant ni cache de plans. Les délais de createMetastoreClient() (167 ms) et la récupération des métadonnées de colonnes (30 s pour 500 tables Iceberg) ne sont pas résolus. Bien que les caches améliorent les performances (système de fichiers : 20-30%, Iceberg, Glue), les « cold starts » restent problématiques car les caches sont volatils. Le coordinateur demeure un point de défaillance unique, impactant les requêtes multi-sources.
Proposal to Optimize Trino Hive Metastore Query Latency by Caching createMetastoreClient() #21671 : https://github.com/trinodb/trino/issues/21671
Metadata not cached when using Iceberg REST catalog with S3Tables – ConnectorMetadata.getTableHandle takes ~200ms on every query #26205 : https://github.com/trinodb/trino/issues/26205
Les distributions commerciales résolvent ses limites pas la version open source
Les éditeurs commerciaux de Trino et Presto ont résolu plusieurs limitations architecturales, notamment le stockage persistant des métadonnées et les caches. Cependant, ces solutions restent propriétaires.
Starburst Enterprise propose un service de cache centralisé (nécessitant une base de données externe) et des caches de métadonnées améliorés, incluant des vues matérialisées automatiques (Starburst Cached Views) pour des performances élevées. Starburst Warp Speed, est considéré comme limité, n’accélérant que les sources lakehouse et étant moins efficace pour les agrégations. Sa complexité de configuration et son manque de résilience aux pannes de nœuds, ainsi que les vues matérialisées de Starburst, sont également critiqués.
Ahana (IBM) a développé RaptorX, un cache multi-niveaux (basé sur RubiX) qui réduit les lectures des lacs de données, améliorant les performances et réduisant les latences.
Meta PrestoDB utilise RaptorX avec Alluxio pour le cache local des fichiers, et un cache de métadonnées hiérarchique sur les coordinateurs et workers. Velox, une bibliothèque C++ vectorisée, est intégrée pour optimiser l’exécution CPU. Un ordonnancement intelligent du cache maximise le taux de succès.
En comparaison, malgré un développement rapide et une très importante communauté, Trino Open Source fait face à des défis pour l’optimisation des performances, le cache et la haute disponibilité. Bien que les versions récentes aient réduit l’impact des limitations de métadonnées, les solutions commerciales conservent un avantage architectural significatif pour les déploiements d’entreprise critiques.
Performance : Trino face aux attentes des utilisateurs BI
L’impact critique sur les temps de réponse des requêtes interactives
La gestion des métadonnées de Trino impactent significativement les temps de réponse. L’interrogation des métadonnées à chaque requête… Le problème s’aggrave avec le nombre de tables. Une requête sur 500 tables et 3 500 colonnes dans le catalogue Iceberg prend 30 secondes, les requêtes étant séquentielles. Ces latences ralentissent la planification des requêtes, la résolution des métadonnées étant le facteur limitant. La communauté reste très active et corrige ces problèmes. Toutefois, les origines de Trino jouent et ce type d’erreurs revient.
Les requêtes interactives et les tableaux de bord BI sont les plus affectés. Chez Shopify, les data scientists visaient une latence P95 inférieure à 5 secondes. Pour des requêtes de 1-2 secondes, les métadonnées représentent 25 à 50% du temps. Le cache froid et les requêtes multiples exacerbent le problème, pouvant entraîner des délais d’attente utilisateur. Une requête joignant 10 tables sans cache prenParce que je voulais comprendre qui est finalement Trino et en particulier pour un usage d’applications analytiques orientées utilisateur où l’expérience interactive est critique.d 1,67 seconde juste pour les métadonnées.
Improve performance when listing columns in Iceberg #23909 : https://github.com/trinodb/trino/pull/23909
Optimizing Data Storage and Querying with Trino, MinIO, and Apache Iceberg : https://www.upsolver.com/blog/trino-minio-iceberg
Trino Open Source n’est pas conçu pour la BI interactive sub-seconde
Malgré ses atouts, Trino n’est pas idéal pour la BI interactive ultra-rapide en raison de son framework Java et de la latence du stockage cloud. Cette lenteur peut faire fuir les utilisateurs et engendrer des coûts cachés. Pour des performances sub-secondes, des précalculs complexes ou l’utilisation de solutions concurrentes comme StarRocks ou Druid sont souvent nécessaires. En somme, Trino est excellent pour l’exploration de données et l’ETL, mais nécessite un système OLAP complémentaire pour la BI interactive.
Trino Open Source n’a pas vocation à être “présenté” à un utilisateur final
Trino Open Source reste un moteur SQL. Rien ne semble aisé pour la prise en main ! Il n’y a même pas de fichiers de configuration par défaut ! Ajouter un connecteur à Trino c’est aussi simple que d’ajouter un fichier. C’est vraiment bien pour les déploiements automatisés. Néanmoins, il n’y a pas une interface propre à Trino à présenter aux utilisateurs. La plupart des bases de données modernes y compris en open source offrent une interface de requêtage. Oui, nombre de clients sont listés sur le site de Trino.
L’Écosystème Concurrentiel et les Choix Stratégiques
Pourquoi Trino reste plébiscité malgré ses limitations

L’écosystème Trino est robuste : projet open source dynamique (plus de 30 versions, 40 000+ commits), adopté par de grandes entreprises (Netflix, Lyft, Salesforce, LinkedIn) et intégré à des plateformes comme Amazon EMR et Athena, Qubole.
Son architecture « stateless » simplifie les opérations et garantit transparence et prévisibilité.
Trino a un nombre de connecteurs importants y compris en écritures, couplé à sa stabilité et sa performance il est un excellent cadre pour l’ETL.
Un nombre d’intégration tellement important…
Les entreprises et l’open source : Le paradoxe des optimisations non partagées
Il est surprenant que Trino open source, malgré son adoption massive par des entreprises comme Uber, Stripe ou Salesforce, conserve des limitations. Ces entreprises ont développé des solutions internes pour y pallier : Uber a expérimenté le caching de plans et a optimisé le cache de données avec Alluxio ; Salesforce s’est concentré sur les optimisations JVM ; Stripe utilise PostgreSQL pour les métadonnées et des outils CLI pour contourner les problèmes d’accès.
Ces optimisations ne sont pas partagées pour plusieurs raisons : avantage concurrentiel, complexité d’intégration, solutions ad-hoc, fragmentation de l’écosystème entre PrestoDB et Trino, et commercialisation par des éditeurs. Bien que des contributions partielles existent, l’écosystème open source reste fragmenté, les grandes entreprises et éditeurs gardant leurs avancées propriétaires, laissant la communauté en retard.
Et ici, on peut aussi identifier les limites de la mutualisation : les éditions commerciales n’ont pas vocation à voir apparaître des fonctionnalités dans la version open source qui leurs fassent concurrence. Et c’est finalement de cette manière que des projets y compris open source corrigent, optimisent ces solutions existantes. Ces dernières deviennent des systèmes hérités…
Conclusion : Choisir Trino en Toute Connaissance de Cause
Trino est un puissant moteur de requête distribué, excellent pour la fédération de données hétérogènes et l’analyse de téraoctets de données, avec un écosystème mature. Cependant, ses limitations structurelles en gestion des métadonnées (stockage en RAM, absence de persistance) impactent la latence, rendant les temps de réponse sub-seconde difficiles pour les utilisateurs BI. Bien que des améliorations aient été apportées, les problèmes fondamentaux persistent dans la version open source, contrairement aux solutions commerciales qui les ont palliées.
On peut aussi reconnaître que dans la bataille de la souveraineté Trino apporte de sérieux arguments parce son déploiement sur site est possible.
Pour les tâches d’ETL, Trino fait face à une concurrence sérieuse, notamment d’Apache Spark et Apache Flink, dont les couches SQL s’améliorent rapidement. DuckDB représente également un concurrent potentiel.
Afin d’atteindre les performances souhaitées, il est essentiel d’optimiser Trino et de l’associer à d’autres plateformes. Par exemple, l’intégration d’Alluxio permet de rapprocher les données grâce à un mécanisme de mise en cache, bien que cela complexifie l’architecture.
Le choix d’adopter Trino doit donc se faire en toute connaissance de cause, en alignant ses capacités intrinsèques avec les besoins spécifiques de l’organisation :
Utiliser Trino quand :
- La fédération de données est une exigence clé, permettant des requêtes complexes sur des sources multiples et hétérogènes.
- Les besoins se concentrent sur l’ETL/ELT et les transformations batch à grande échelle.
- L’analytique exploratoire par des data scientists est un cas d’usage primaire, où les requêtes ad-hoc et l’accès à de vastes ensembles de données sont prioritaires.
- Il s’agit d’une migration depuis Hive ou d’une modernisation d’infrastructures Hadoop legacy.
Éviter Trino seul pour :
- Les dashboards temps réel nécessitent des temps de réponse inférieurs à la seconde.
- Les applications user-facing où une expérience interactive critique est attendue.
- Les systèmes d’alerting/monitoring où la latence est critique pour les décisions opérationnelles.
- Les cas de petites données (<100 Go) où des solutions OLTP plus simples seraient plus efficaces.
Bien sûr depuis 2017 nous mettons en avant Dremio. Vous le téléchargez et il fonctionne et vous pouvez l’utiliser pour fédérer vos données ! Et vous aurez réalisé vos premières requêtes avant de vous poser des questions relatives à sa configuration. Oui c’est aussi simple que ça. Et ce même avec la version open source. Nous laissons à Dremio les benchmarks comparatifs. Ce que nous voulons vous transmettre ici c’est que les versions open source de ces deux projets sont très distinctes ! L’un est très orienté ETL, l’autre est très orienté analyses interactives et s’inscrit dans une expérience utilisateur bien plus fluide. Même dans sa version open source Dremio est une plateforme quand Trino Open Source n’est qu’un moteur SQL dont le premier use case est l’ETL.
