
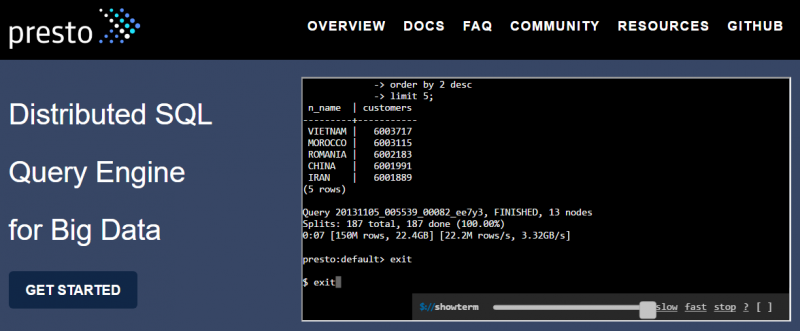
Notre team R&D est allée à la découverte de Presto, un moteur de requête SQL distribué open source, créé par Facebook. Charly Clairmont vous présente ses caractéristiques et vous offre un aperçu de ses capacités.
De nombreuses grandes compagnies de l’Internet développent des solutions qu’elles poussent souvent en open source. Facebook, qui est l’auteur de Hive, la première couche SQL pour Hadoop, a également créé Presto pour offrir une nouvelle expérience d’accès et d’interrogation à l’ensemble de ses données.
Une architecture conçue pour offrir les meilleures performances
Presto est donc une des couches SQL pour Hadoop.
Il est bien entendu qu’aujourd’hui, Hive connaît des performances qui en fait un outil tant pour exécuter des requêtes SQL en mode batch que pour satisfaire les utilisateurs avec une interactivité franche, grâce aux nouvelles fonctionnalités offertes par le LLAP.
Presto, contrairement à certains autres moteurs SQL pour Hadoop, s’appuie sur du SQL ANSI. Il a été architecturé dès ses débuts pour offrir les meilleures performances pour l’exécution de requêtes interactives dont les données sont autant issues d’Hadoop (HDFS, HIVE, Hbase) que d’autres sources telles les bases de données (relationnelles ou non), vos systèmes de fichiers, voire vos systèmes de file d’attente !
Presto tire parti d’une architecture orientée mémoire (RAM). Ceci lui permet, entre autre, de manipuler de grandes masses de données ou encore d’accepter de grands nombres de requêtes concurrentes.
Fédération de données
En plus des nombreuses fonctionnalités telle que la performance, la distributivité des calculs, Presto s’apprécie surtout pour ses capacités à fédérer vos données ! Attention, ici, nous nous plaçons du point de vue analytique (pour de la fédération de données, ou virtualisation de base de données regardez du côté de Teiid de Jboss). De nombreux connecteurs articulent ce point de vue unique sur l’ensemble de vos données. Voilà la liste des connecteurs qui continue de s’allonger à chaque nouvelle version :
- Accumulo
- Black Hole
- Cassandra
- Hive
- Memory
- JMX
- Kafka
- Local File
- MongoDB
- MySQL
- PostgreSQL
- Redis
- Microsoft SQL Server
L’utilisation d’un connecteur se révèle assez simple. Par exemple, pour accéder à vos bases de données MySQL, il suffit de créer un fichier comportant les informations suivantes :
connector.name=mysql connection-url=jdbc:mysql://<<SERVEUR>>:<<PORT>> connection-user=<<UTILISATEUR>> connection-password=<<MOT DE PASSE>>
Nous utilisons l’outil Yanagishima comme environnement de développement contre Presto. C’est un client web. Nous pouvons tout autant exploiter des clients lourds.
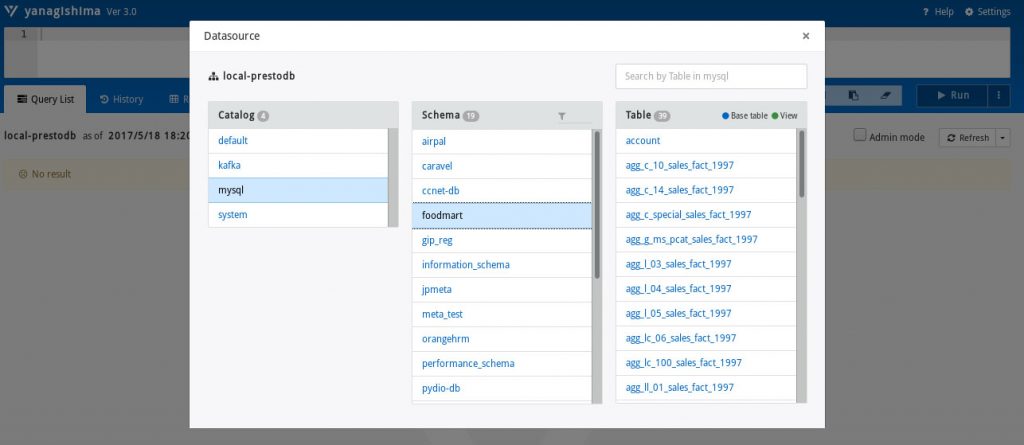
Par extension il est simple de comprendre qu’il en est de même pour l’ensemble des connecteurs pour Presto : ici c’est un serveur MySQL, mais c’est le même principe pour plusieurs serveurs MySQL, idem pour PostgreSQL, SqlServer, ou Cassendra, MongoDB !
Presto & Kafka
Un des connecteurs qui présente une forte valeur ajoutée c’est Apache Kafka ! Apache Kafka est une solution distribuée pour de la messagerie d’entreprise. Apache Kafka sait ingérer et distribuer un très grand nombre de messages et ce même sur une période très courte.
Coupler Apache Kafka et Presto est une solution simple qui permet d’avoir une donnée en quasi temps réel ! Vous pouvez suivre toutes les tendances de votre activité ! Par exemple, si vous avez un réseau de distribution, vous pouvez concentrer vos commandes via Apache Kafka dès la validation de la transaction ! Elles deviennent immédiatement disponibles via Presto à l’ensemble de vos solutions de suivi opérationnel ou décisionnel !
Tout d’abord nous restons dans la philosophie classique de l’informatique décisionnelle : nous ne requêtons pas directement le système opérationnel grâce à Presto mais choisissons une approche par découplage ! Apache Kafka nous permet de collecter les transactions ! Pour cela nous exploitons Apache Kafka Connect dont le rôle est de surveiller vos tables de base de données et en récupérer les enregistrements dès qu’elles y sont stockés.
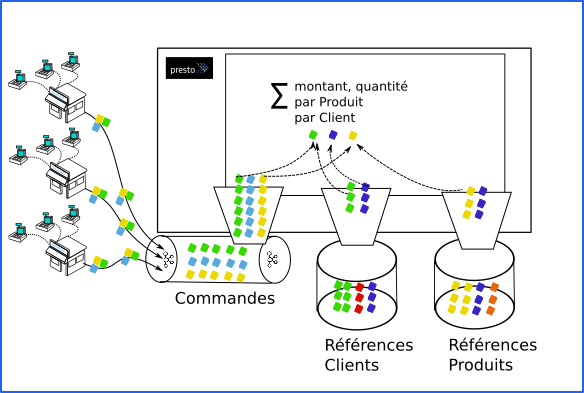
Confluent, le premier contributeur Apache Kafka, propose une plateforme où vous pouvez gérer l’ensemble de vos collectes et exports via la messagerie distribuée.
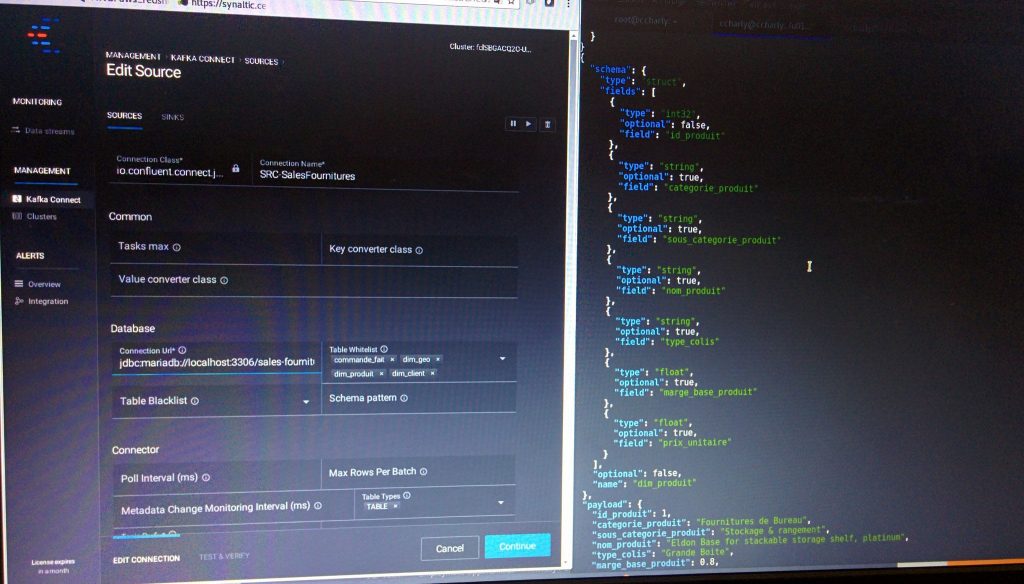
Apache Kafka gère des « topics » (pour vulgariser nous pourrions oser la comparaison avec une table d’une base de données).
Revenons à Presto. Le connecteur Kafka de Presto liste les différents topics à surveiller !
connector.name=kafka kafka.nodes=localhost:9092 kafka.table-names=tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,tpch.supplier,tpch.nation,tpch.region kafka.hide-internal-columns=false
kafka.table-names liste les tables de Presto qui s’appuient sur les topics.
La définition des tables se présente de cette manière :
{
"tableName": "orders",
"schemaName": "tpch",
"topicName": "tpch.orders",
"key": {
"dataFormat": "raw",
"fields": [
{
"name": "kafka_key",
"dataFormat": "LONG",
"type": "BIGINT",
"hidden": "false"
}
]
},
"message": {
"dataFormat": "json",
"fields": [
{
"name": "row_number",
"mapping": "rowNumber",
"type": "BIGINT"
},
{
"name": "order_key",
"mapping": "orderKey",
"type": "BIGINT"
},
{
"name": "customer_key",
"mapping": "customerKey",
"type": "BIGINT"
},
{
"name": "order_status",
"mapping": "orderStatus",
"type": "CHAR"
},
{
"name": "total_price",
"mapping": "totalPrice",
"type": "DOUBLE"
},
{
"name": "order_date",
"mapping": "orderDate",
"type": "DATE",
"dataFormat": "iso8601"
},
{
"name": "order_priority",
"mapping": "orderPriority",
"type": "VARCHAR"
},
{
"name": "order_clerk",
"mapping": "clerk",
"type": "VARCHAR"
},
{
"name": "ship_priority",
"mapping": "shipPriority",
"type": "INTEGER"
},
{
"name": "comment",
"mapping": "comment",
"type": "VARCHAR"
}
]
}
}topicName identifie le topic à scruter et en présenter les données à Presto.
dataFormat indique la manière dont la donnée est enregistrée dans le topic. Presto doit transformer la donnée afin quel soit facilement lisible et manipulable par ses utilisateurs.
Depuis Yanagishima nous pouvons facilement interroger Kafka !
Par exemple, suivre les commandes :
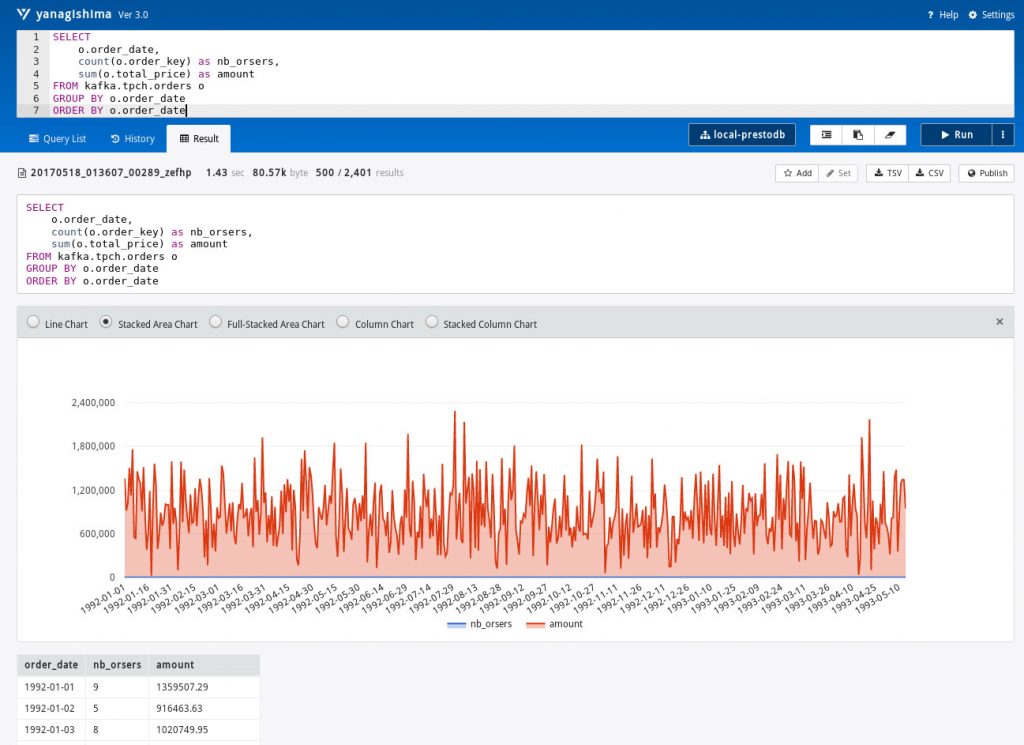
Bien entendu, l’intérêt premier consiste à exposer les résultats de ces traitements et autres analyses dans vos outils opérationnel existants !
Par exemple si nous voulions créer des états avec JasperReports, Birt, Tableau (ou autre…), nous disposons donc de connecteur JDBC ou ODBC ! Votre connaissance de SQL, ou de vos outils qui vous assistent à construire des requêtes SQL, prennent alors le relais. Vous pouvez donner un accès en quasi temps réel à ce qui se passe depuis vos différentes boutiques ou accéder à vos données machines… Et ce en quasi temps réel sans pour autant surcharger vos systèmes opérationnels.
Ici nous créons un rapport avec JasperReports Studio que nous publions dans un portail décisionnel tel que Knowage (anciennement SpagoBI).
Nous construisons la requête :
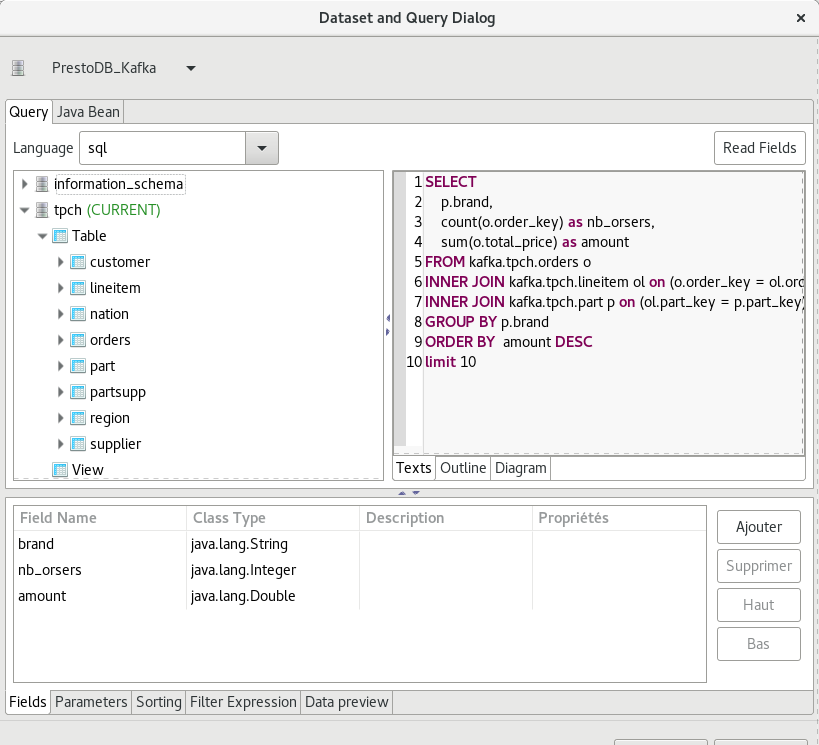
Nous construisons le rapport :
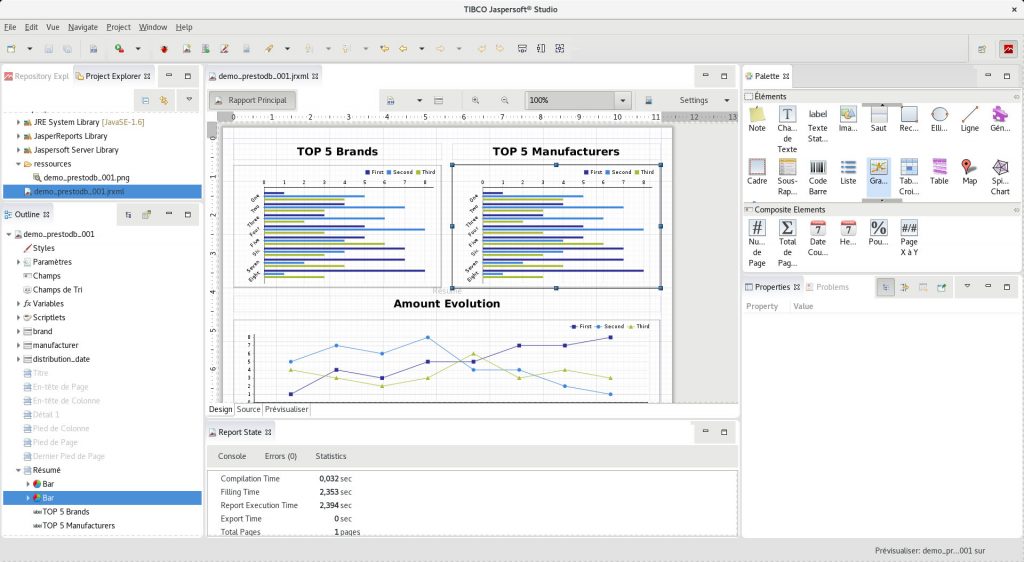
Nous le publions dans Knowage et permettons à un utilisateur final d’y accéder :
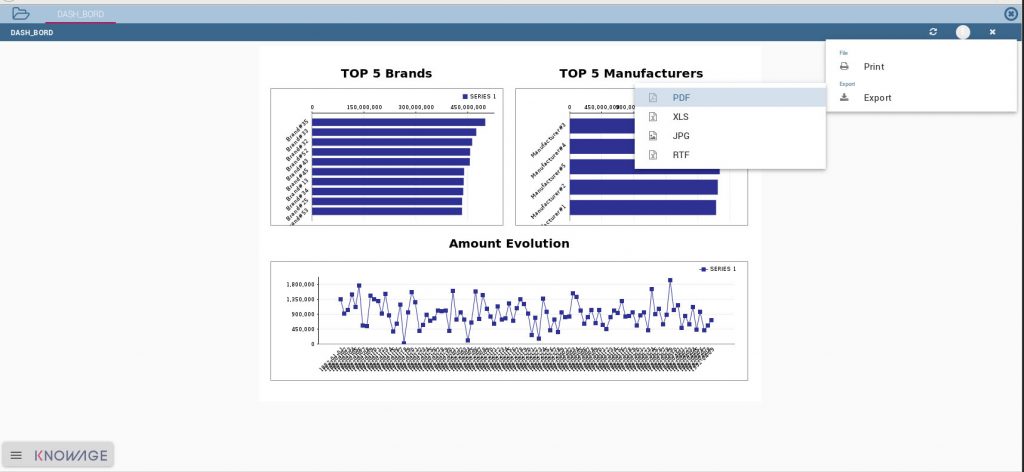
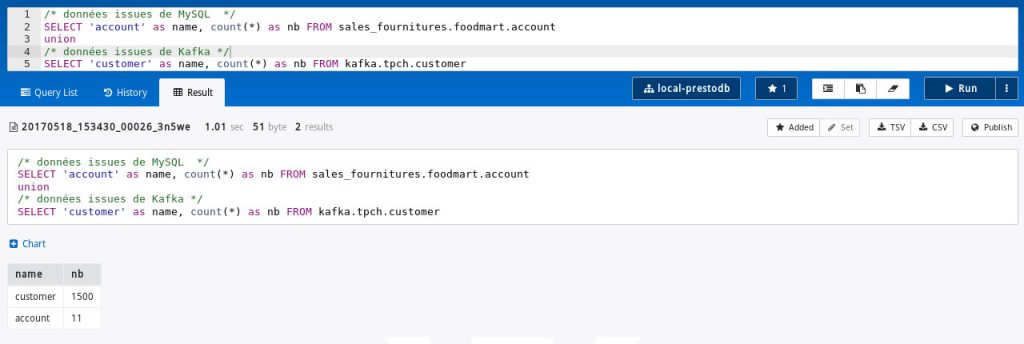
Enfin, et ce afin de bien insister sur la capacité de Presto à vous accompagner dans vos analyses « fédérées », nous avons réalisé une simple requête pour montrer à quel point vous pourriez procéder de la même façon avec vos différentes sources de données, mêmes celles ayant une forte vélocité. Comprenez que vous serez par exemple en mesure d’enrichir une donnée temps réel à forte fréquence par une jointure avec une données par exemple de type référentiel.
Tous les exemples que nous avons parcourus dans cet article peuvent vous paraître légers. Nous n’avons pas cherché à vous démontrer la robustesse, la performance de ces solutions, ou même leur caractère résiliant (tolérance à la panne). Nous avons au contraire voulu vous expliquer comment vous pourriez mettre en œuvre des solutions simples (où il est surtout question de paramétrage : pas de développement) pour constituer votre chaîne de valeur analytique, et en donner facilement accès au plus grand nombre. Nous avons employé des solutions de business intelligence open source, mais les solutions propriétaires offrent des capacités similaires avec Presto.

Sections commentaires non disponible.