

Je voulais intituler cet article « Big Data aussi simple que LAMP ». J’ai vite trouvé que c’était réducteur.
Depuis que Synaltic s’intéresse au Big Data, j’ai toujours imaginé qu’il fallait que l’appropriation et plus généralement le fonctionnement de ces technologies soient de plus en plus simple.
C’est vrai après tout, même quand vous vous serez décidé à vous lancer dans cette nouvelle aventure, il vous faudra savoir par quel bout démarrer.
C’est justement ce type de questions que je n’ai eu de cesse de me poser ces derniers temps et plus particulièrement cet été, histoire d’écrire un peu parce que ça faisait bien longtemps.
Je ne veux pas revenir sur la nécessité d’initier son périple par une appropriation de l’écosystème du Big Data, de son marché : comprendre, connaître les briques et savoir bien évidemment à quoi elles servent.
Non, je veux plutôt donner quelques pistes pour vous aider à vous lancer concrètement dans votre projet Big Data. Évidemment vous ou quelqu’un dans votre organisation avez déjà téléchargé une sandbox ou utilisé un démonstrateur en ligne afin de tester, ou vous faire une idée de ce que sont les environnements Big Data.
Architecture Lambda
Il existe aujourd’hui de nombreuses architectures qui mêlent diverses solutions pour couvrir le maximum de besoins. Évidemment, il n’est pas question de toutes les prendre en main. Cependant, il existe une sorte d’architecture de référence aujourd’hui, on l’appelle la « lambda architecture« .
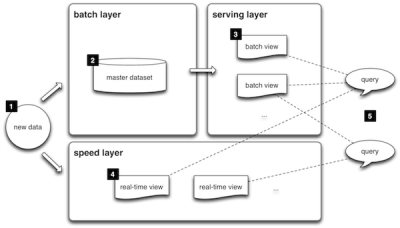
Cette architecture permet de répondre à un grand nombre de cas d’utilisations. Plus tard il vous appartiendra d’identifier les solutions les meilleures qui répondent clairement à votre problématique et qui s’inscrivent dans ce type d’architecture.
Pour initier notre aventure, la première question qu’il convient de se poser renvoie à la localisation des données. Ici, je fais vraiment référence au lieu physique ou géographique où sont situés les serveurs qui hébergent vos données sources. Une autre question arrive, elle aussi, très vite : Quelle est la taille de ces données ? Et mieux encore : Quelle sera la taille de ces données dans 1 mois, 3 mois, 1 an, 3 ans ? Vous vous demanderez aussi : ”A quelle fréquence dois-je les collecter ?” Au fond, comment souhaitez-vous être réactif vis à vis de vos problématiques pour les résoudre ?
J’imagine que vous voyez où je veux en venir…
Si vous êtes un e-commerçant(e) ; vos données sont déjà dans le cloud, votre cluster Big Data y sera également dans beaucoup de cas ! Si vous êtes au contraire une compagnie industrielle, financière, issue de la grande distribution ou autre avec des serveurs gérés en interne : à priori votre cluster Big Data sera plutôt hébergé chez vous.
C’est ici que je devrais arrêter de parler de Big Data , pour introduire ou rappeler la notion de Data Lake, ou Data Hub.
Une comparaison pourrait être faite avec les Data Warehouses qui avaient déjà pour but de concentrer l’ensemble des données des organisations. Toutefois, on a pris pour habitude de cloisonner l’information ! Il n’a jamais alors été possible d’avoir une vision holistique d’une activité. Nous pouvons par exemple citer les banques qui par la séparation de leurs activités n’ont pas une vue globale de leurs clients ! Un comble ! Les Data Lake ou Data Hub ont ainsi vocation à rassembler toutes vos données, afin de fournir une vision large de vos activités grâce aux données de votre système d’information, aux données des réseaux sociaux dont on parle beaucoup, mais aussi à toutes ces autres données : celles de vos partenaires, celles de vos machines, ou autres capteurs, celles que vous n’avez jamais osé collecter parce que cela vous semblait futile !
Nous reprenons donc, si vos données sont déjà dans le cloud, choisissez une infrastructure dans le cloud. Si elles sont déjà au sein de votre propre infrastructure, construisez-y votre propre cluster, voire plusieurs. Cela vous évitera d’échanger une importante volumétrie de chez vous vers un fournisseur du cloud ou dans le sens inverse.
Le Déploiement : Combien de machines ? Comment ?
Est-il alors si simple d’installer un certains nombres de machines ? Comment exploiter autant de machines ? Telles sont les nouvelles questions.
D’abord, il est apparu ces dernières années plusieurs solutions pour automatiser des déploiements à grande échelle : Puppet, Chef, Ansible… Vous pourrez les utiliser aussi bien chez un fournisseur de cloud que sur votre infrastructure propre.
Toutefois, privilégiez un outil comme The Foreman qui saura aussi bien vous aider dans l’installation de machines physique que virtuelles. Bien entendu The Foreman s’appuie sur les briques que je viens de citer.
Vous pourrez utiliser The Foreman avec les blueprints d’Ambari, solution de gestion de cluster Hadoop, pour déployer votre cluster. Je vous invite à parcourir l’article très bien fait de CodeCentric : Automatic Provisioning of a Hadoop Cluster on Bare Metal with The Foreman and Puppet.
Une autre approche et certainement la plus simple quand on commence juste Hadoop, (oui, il est surtout question d’Hadoop), consiste à s’appuyer sur les solutions dans le cloud. Vous mesurerez assez tôt quand il vous faut quitter une telle approche si elle ne vous convient pas.
Je vous fournis une petite liste de différents fournisseurs d’Hadoop dans le cloud :
L’inconvénient de ces plates-formes c’est qu’elles ne correspondent pas toujours aux dernières versions. C’est pourquoi vous pourrez procéder à une installation via des outils spécialisés et dédiés au déploiement d’Hadoop. Cloudbreak, passé sous le giron d’Hortonworks, ou encore Coopr de Cask!
L’un des points les plus intéressants de Cloudbreak c’est qu’il est en mesure de gérer plusieurs projets, et même plusieurs clusters dans un projet. Il devient très simple alors de distinguer vos environnements Hadoop ! D’autant plus que Cloudbreak s’appuie sur les blueprints d’Ambari ! Vous saurez alors configurer vos différents modèles de clusters : un cluster orienté traitement rapide et mémoire : Kafka + Spark + HBase + Zeppelin, un cluster orienté support de votre data warehouse : HDFS + Hive + Pig + Hue… Ou tout simplement distinguer le développement, de la recette, de la production.
Par ailleurs, Cloudbreak offre quelques outils supplémentaires pour vérifier que les services de base sont bien actifs : il intègre Consul qui offre le monitoring de services. Aujourd’hui Cloudbreak sait créer des clusters chez les grands fournisseurs de cloud :
- Amazon AWS,
- Microsoft Azure,
- Google Cloud Platform
- OpenStack
L’avantage d’OpenStack est qu’il est rapidement devenu un standard ; vous pourrez alors déployer votre cluster chez OVH ou Cloudwatt ou toute autre fournisseur qui propose une infrastructure basée sur OpenStack.
Cloudbreak a fait le choix de déployer son cluster via des containers Docker. On reste ainsi très proche des performances de la machine, virtuelle ou physique !
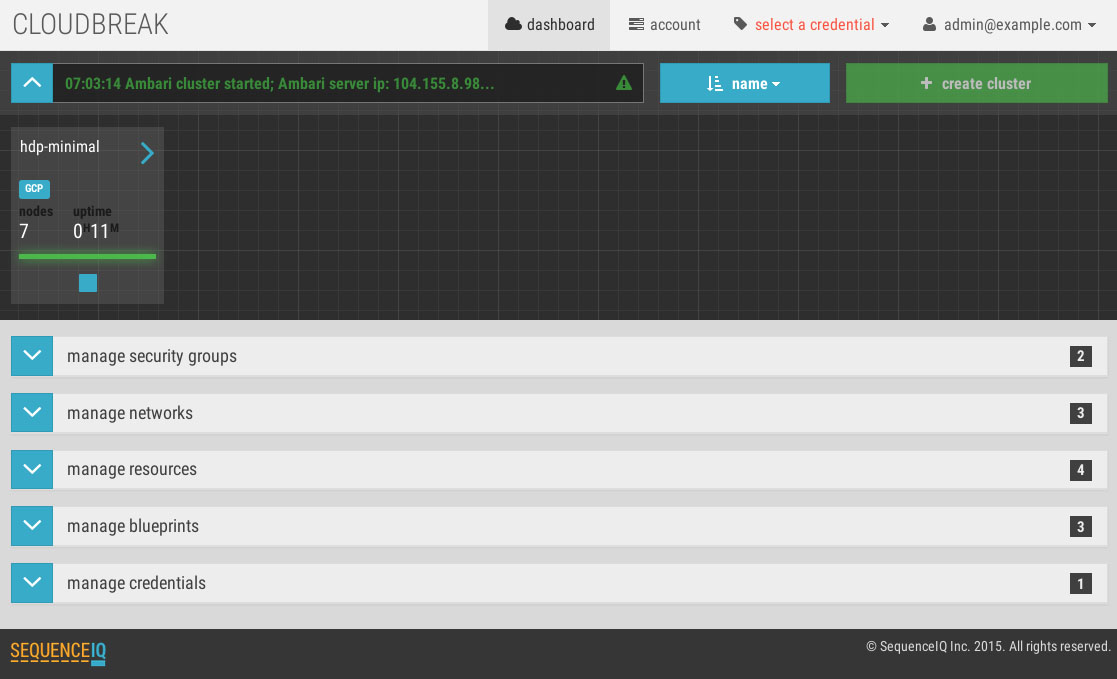
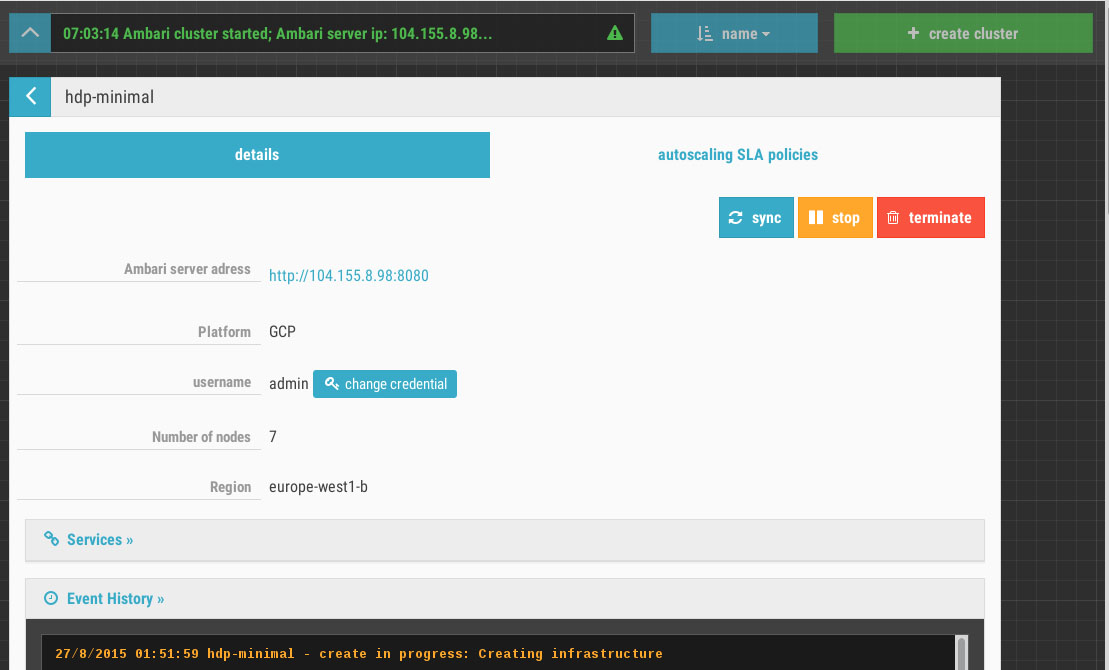
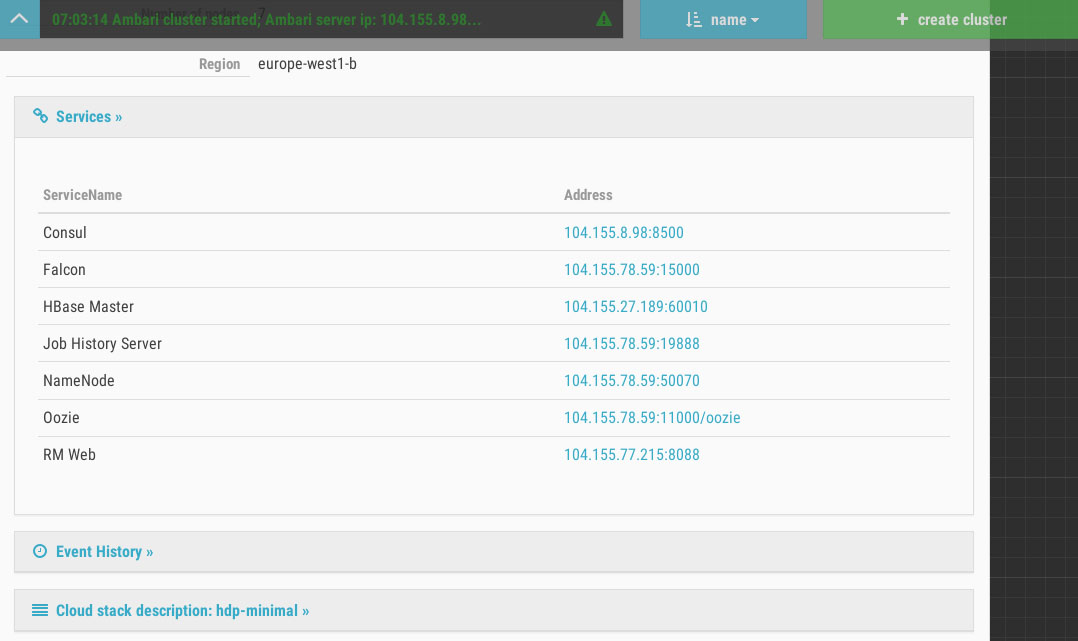
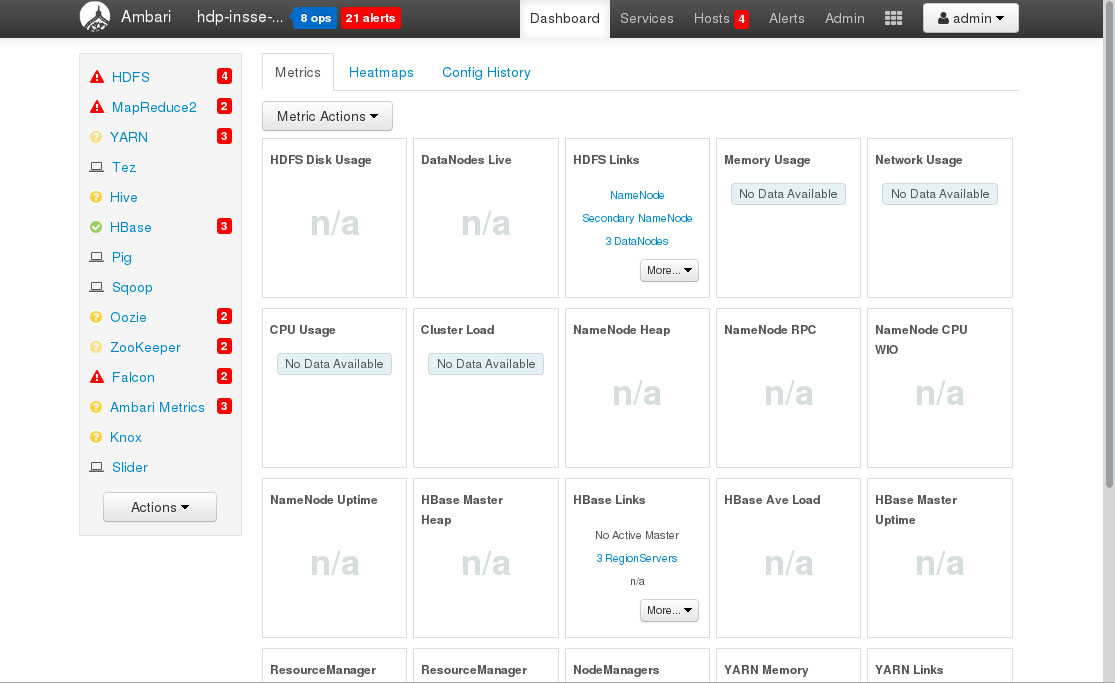
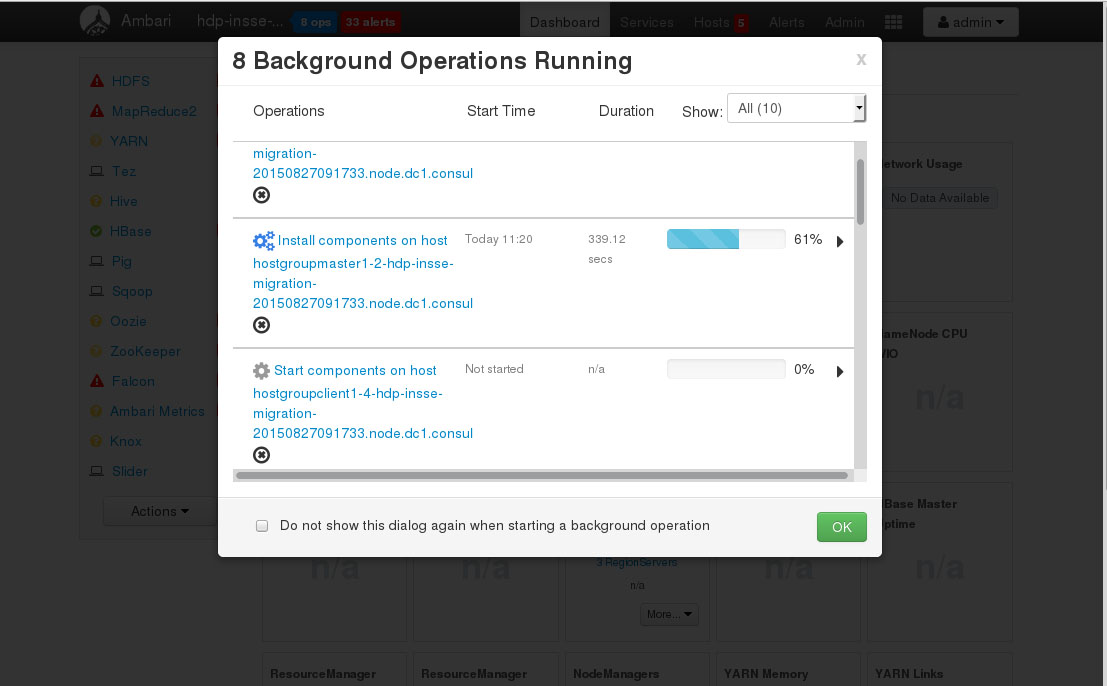
(Cliquez sur la première image pour faire défiler)
Finalement la plus belle fonctionnalité de Cloudbreak est certainement « l’autoscalling » ! En effet, le projet intègre une brique très intéressante, Periscope, qui capte des mesures aussi bien depuis YARN, le gestionnaire de ressources d’Hadoop, que les indicateurs système fournis par votre fournisseurs de cloud ! De cette manière, il est en mesure d’ajouter ou supprimer des nœuds selon la charge du cluster. Vous pouvez donc optimiser le coût de possession de votre cluster Hadoop.
Certains me feront le reproche que Cloudbreak fonctionne aujourd’hui principalement avec Hortonworks ! Oui ! C’est vrai. Il faut savoir que dans la feuille de route, Cloudbreak travaille avec la communauté Hadoop pour porter Apache Bigtop comme autre distribution.
Finalement, ce qu’il est intéressant de noter c’est que Hadoop bouge très vite. Il est vrai qu’il y a une vraie frénésie autour de Spark ! Certes, il apporte une grande simplification du développement mais à lui seul ne résout pas toutes les questions ! Aujourd’hui Hadoop n’est plus juste MapReduce et HDFS c’est tout un écosystème pour travailler en distribué et gagner en réactivité.
La simplification de l’utilisation d’Hadoop, et notamment de son installation, est au cœur de nombreux éditeurs ! Même Google a récemment mis sur le marché Dataproc !
Les innovations dans chaque recoin de l’écosystème sont nombreuses ! Et c’est pourquoi il est utile que des standards émergent ! Bravo donc à l’initiative Open Data Platform.
Photo credit: Birgit F via VisualHunt.com / CC BY-NC-ND

Sections commentaires non disponible.