Iceberg Summit 2025 : Apache Iceberg un socle commun pour la données
1. Introduction : Apache Iceberg à l’Avant-Garde des Architectures de Données Modernes
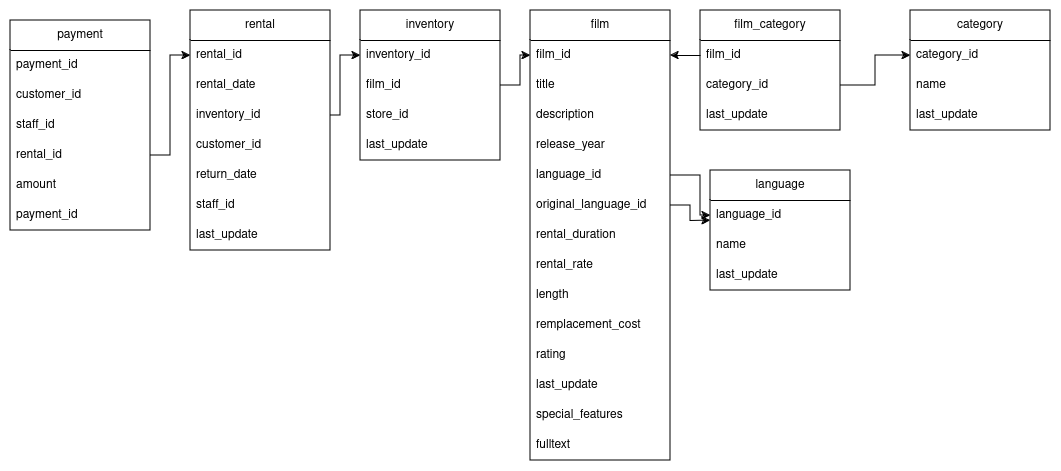
Apache Iceberg s’est rapidement imposé comme un format de table ouvert de haute performance, essentiel pour la gestion de jeux de données analytiques au sein des data lakes et des lakehouses modernes. Il répond désormais à une gamme large de cas d’usage. Sa proposition de valeur fondamentale réside dans sa capacité à apporter la fiabilité et la simplicité des tables SQL. Tant les moteurs Apache Spark, Trino, Apache Flink, Presto, Apache Hive, Apache Impala que les moteurs de grandes plateformes Snowflake, Dremio, Confluent, Databricks, Microsoft Fabric, Crunchy (PostgreSQL), Rising wave, Single Store, Qlik (Upsolver), Fivetran, Airbyte (- et bien d’autres -) savent interagir de manière sécurisée et concurrente avec les mêmes tables au travers de l’API REST pour les catalogue Apache Iceberg.
Dans ce contexte d’adoption croissante, l’Iceberg Summit 2025, tenu les 8 et 9 avril en format hybride (San Francisco et virtuel), sous l’égide de l’Apache Software Foundation (ASF) et du Project Management Committee (PMC) d’Iceberg, ce sommet a réuni la communauté mondiale – des contributeurs principaux aux utilisateurs expérimentés et aux « curieux d’Iceberg » – pour partager des connaissances pratiques, explorer des cas d’usage réels et, de manière cruciale, façonner l’avenir de l’infrastructure de données.
Cet article vise à synthétiser les perspectives clés émanant de l’Iceberg Summit 2025 concernant la feuille de route future d’Apache Iceberg, son évolution technique, les tendances de l’écosystème.
L’implication marquée de fournisseurs majeurs et souvent concurrents – AWS, Dremio, Microsoft, Snowflake, Databricks, Cloudera – ainsi que des annonces stratégiques, indiquent une évolution significative. Apache Iceberg semble transcender son rôle initial de format de table pour s’établir comme un standard incontournable au cœur des architectures lakehouse ouvertes.
Cette convergence intersectorielle, où les acteurs majeurs investissent activement dans l’intégration de leurs forces propriétaires tout en contribuant à l’évolution du standard ouvert, suggère qu’Apache Iceberg devient un point de ralliement pour l’écosystème.
2. Evolution d’Apache Iceberg : V3 disponible, en Route vers la V4
L’évolution continue d’Apache Iceberg a été un thème central de l’Iceberg Summit 2025, avec des discussions portant à la fois sur les avancées récentes de la version 3 et sur les anticipations concernant la future version 4.

La version 3 d’Iceberg a introduit des fonctionnalités significatives qui élargissent considérablement les cas d’usage du format. Parmi les plus notables discutées lors du sommet figurent les nouveaux types de données Variant et Geospatial.
Le type Variant, a en particulier, suscité beaucoup d’intérêt car il promet de simplifier considérablement la gestion et l’interrogation des données JSON et semi-structurées directement au sein des tables Iceberg. Ceci répond à un besoin fréquent dans les pipelines de données modernes qui traitent des sources de données hétérogènes.
L’ajout du type Geospatial ouvre également de nouvelles perspectives pour les applications d’analyse spatiale directement sur le data lakehouse.
Les discussions vont déjà bon train autour d’Iceberg V4 ! En effet, cela concerne une modification architecturale clé : une disposition des métadonnées plus adaptative. Cette évolution vise à optimiser la structure interne de gestion des métadonnées d’Apache Iceberg. L’objectif est de remédier à certains goulots d’étranglement de performance observés avec la structure actuelle, notamment en améliorant significativement la vitesse de lecture pour les petites tables ou pour certains motifs de requêtes spécifiques qui sont moins performants aujourd’hui.
Ces développements, qu’il s’agisse des nouvelles fonctionnalités de la V3 ou de la planification de la V4, sont motivés par des objectifs plus larges. Il s’agit de rendre Apache Iceberg toujours plus accessible à un plus grand nombre de types de traitements. Les fondamentaux sont là (transactions ACID, voyage dans le temps, évolution de schéma) maintenant il s’agit par exemple d’être plus performant vis à vis des “petites tables”.
L’adoption plus large du format, l’extension de la communauté sont autant de facteurs qui poussent à prendre en compte ce type de traitements en particuliers.
3. Apache Iceberg : une Interopérabilité assumée
Comme expliqué en introduction l’une des forces d’Apache Iceberg est sont interopérabilité. Celle-ci est un moteur clé de son adoption, car elle offre aux organisations la flexibilité de choisir les meilleurs outils de calcul pour leurs besoins spécifiques, sans être enfermées dans un écosystème propriétaire au niveau du traitement.
Les fournisseurs de plateformes de données majeurs ont non seulement adopté Iceberg, mais ils investissent également massivement pour améliorer son intégration et ses performances au sein de leurs offres. Snowflake, par exemple, a fait des annonces significatives lors du sommet, indiquant qu’il étendait ses capacités principales – moteur de calcul performant, partage de données sécurisé, gouvernance, continuité d’activité et reprise après sinistre – pour fonctionner de manière transparente avec les tables Apache Iceberg. Leur objectif déclaré est de permettre aux clients de manipuler leurs données ouvertes stockées dans Iceberg exactement comme ils le feraient avec les tables natives de Snowflake, éliminant ainsi les compromis historiques entre ouverture et performance/fonctionnalités.
Des engagements similaires de haut niveau en faveur d’Iceberg ont été exprimés par d’autres acteurs clés comme AWS, Microsoft et Dremio, Google Big Query, Crunchy DB…
Au-delà de l’intégration au niveau des moteurs de calcul, une tendance claire émerge concernant la gestion des métadonnées Iceberg : l’adoption croissante des catalogues basés sur l’API REST comme le standard émergent.
Alors que des solutions historiques comme Hive Metastore ou des services cloud spécifiques comme AWS Glue Catalog sont encore utilisées, des organisations pionnières telles qu’Airbnb et Bloomberg ont développé leurs propres implémentations de catalogues compatibles REST, souvent adossées à des bases de données relationnelles comme PostgreSQL. Cette évolution vers des interfaces REST est motivée par la nécessité de débloquer un meilleur support multi-moteurs, de centraliser le contrôle d’accès et de permettre une gouvernance pilotée par les métadonnées de manière plus cohérente à travers l’écosystème.
Dans ce contexte, le projet Apache Polaris gagne en visibilité. Polaris vise à définir un standard ouvert et à fournir une implémentation de référence pour un service de catalogue Iceberg basé sur REST.
L’ascension des catalogues REST, et potentiellement d’un standard comme Polaris, apparaît comme un élément crucial pour réaliser pleinement la promesse d’ouverture d’Iceberg. Ainsi l’API standardisée devient l’élément essentiel pour mettre en œuvre une gouvernance cohérente et transversale (contrôle d’accès fin, masquage de colonnes) : les règles d’accès et de sécurité sont définies une et une seule fois.
4. PyIceberg : Intégration Python pour la Data Science et l’IA
PyIceberg constitue une pierre angulaire quant à l’adoption d’Apache Iceberg par les data scientist.
Les caractéristiques intrinsèques d’Iceberg – fiabilité transactionnelle (ACID), évolutivité (des schémas), capacité de voyage dans le temps (time travel), format ouvert et interopérable – sont cruciales pour construire des pipelines de données robustes nécessaires à l’entraînement de modèles d’apprentissage automatique (ML) et à l’alimentation d’applications d’IA.
Cependant, au-delà de la simple lecture ou écriture de tables, un défi spécifique a été mis en évidence : l‘exécution efficace de logique Python personnalisée, souvent sous forme de fonctions définies par l’utilisateur (User-Defined Functions – UDFs), directement sur les données résidant dans les tables Iceberg.
L’insistance sur le support Python et l’IA signale une expansion du rôle d’Iceberg au-delà de ses origines dans l’analytique à grande échelle. Initialement conçu pour optimiser les requêtes SQL sur de grands volumes de données tabulaires, Iceberg est de plus en plus sollicité par les data scientists pour leurs workflows ML. Les défis de performance rencontrés avec les UDFs Python soulignent la nécessité d’une intégration plus profonde entre le format de stockage (Iceberg) et les bibliothèques ou frameworks ML. Des fonctionnalités comme le voyage dans le temps, initialement utiles pour l’audit ou la correction d’erreurs, deviennent critiques pour la reproductibilité en ML, permettant de suivre précisément les versions de données utilisées pour entraîner un modèle spécifique.
Cette focalisation sur Python et l’IA indique qu’Iceberg pénètre activement le domaine des opérations d’apprentissage automatique (ML Ops).
5. Maintenir Apache Iceberg : Automatisation et Bonnes Pratiques Opérationnelles
À mesure qu’Apache Iceberg est déployé à plus grande échelle et pour des cas d’usage plus dynamiques, la gestion opérationnelle devient un enjeu majeur. Le Summit de 2025 a mis en lumière un fort intérêt pour l’automatisation des tâches de maintenance récurrentes des tables. Ces tâches incluent l’évolution des stratégies de partitionnement (par exemple, passer de partitions horaires à journalières sans interrompre les lectures), la compaction régulière des petits fichiers et l’expiration des anciens snapshots pour gérer l’espace de stockage et la rétention des données.
Face à ces défis, une bonne pratique émergente consiste à gérer les opérations Iceberg en appliquant les principes DevOps aux données. Des équipes construisent des interfaces et des processus qui s’appuient sur des configurations déclaratives (ex: YAML), des flux de validation via pull requests, des pipelines d’intégration et de déploiement continus (CI/CD), et des couches d’abstraction pour masquer la complexité sous-jacente et fournir un accès fluide et contrôlé aux plateformes de données pour les utilisateurs finaux.
Parallèlement, l’observabilité des données est de plus en plus reconnue comme une composante critique pour gérer la complexité des déploiements Iceberg, en particulier ceux impliquant du streaming, des évolutions de schéma fréquentes ou des pipelines multi-étapes. Il ne suffit plus de surveiller la santé des pipelines ou de l’infrastructure ; il est essentiel de détecter en temps réel les problèmes liés aux données elles-mêmes au sein des tables Iceberg.
L’ensemble de ces discussions sur l’automatisation, la gestion du streaming, les pratiques DevOps et l’observabilité convergent vers une conclusion importante : la maturité opérationnelle, et pas seulement l’ajout de nouvelles fonctionnalités au format lui-même, est la clé du succès à long terme d’Apache Iceberg.
6. Frontières de la Performance : Optimisation des Requêtes et Exploration de Nouveaux Formats
L’amélioration continue des performances des requêtes sur les tables Apache Iceberg reste une priorité majeure pour la communauté et les fournisseurs de l’écosystème. Des initiatives spécifiques aux vendeurs ont été annoncées lors du sommet, comme l’application par Snowflake de ses services propriétaires d’optimisation (Search Optimization Service) et d’accélération des requêtes (Query Acceleration Service) directement aux tables Iceberg. Dremio aussi, avec la sortie de sa version 26 intègre des fonctionnalités d’automatisation pour mieux “partitionner” les données et améliorer significativement les performances. L’objectif affiché est d’atteindre une parité de performance entre les données stockées dans des formats ouverts comme Iceberg et celles stockées dans les formats natifs des plateformes.
Au-delà des optimisations spécifiques aux moteurs, des considérations générales de performance liées à la structure même des tables Iceberg ont été discutées. Par exemple, l’impact de l’évolution du schéma (comme l’ajout de colonnes très larges) ou des modifications de la stratégie de partitionnement sur l’efficacité de l’élagage des fichiers (file pruning) et la vitesse globale des requêtes a été souligné, nécessitant une surveillance attentive des métriques de performance comme la latence des requêtes et le nombre de fichiers scannés.
Parallèlement aux optimisations basées sur les moteurs et la structure des tables Iceberg, un intérêt notable émerge au sein de la communauté pour l’exploration de nouveaux formats de fichiers colonnaires qui pourraient potentiellement remplacer ou compléter le format Parquet, actuellement omniprésent. Les formats Vortex et Lance ont été cités comme exemples lors des discussions du sommet. La motivation derrière cette exploration est la possibilité que ces formats plus récents offrent des avantages de performance significatifs pour des types spécifiques de requêtes ou des caractéristiques de données particulières.
Cet intérêt pour de nouveaux formats de fichiers sous-jacents est logiquement lié à une demande croissante pour des moteurs de données capables de lire de manière transparente plusieurs formats de fichiers (Avro, Parquet, ORC, Lance, Vortex, etc.) au sein d’un même environnement lakehouse géré par Iceberg.12 Cela reflète un désir de flexibilité architecturale, permettant aux équipes de choisir le format de fichier le plus approprié pour chaque jeu de données ou cas d’usage spécifique, tout en bénéficiant de la couche de gestion unifiée fournie par Iceberg.
7. Gouvernance et Sécurité dans les Lakehouses Ouverts
Avec la pénétration croissante d’Apache Iceberg dans les environnements d’entreprise, l’accent mis sur les fonctionnalités robustes de gouvernance des données et de sécurité s’intensifie. Les discussions lors de l’Iceberg Summit 2025 ont clairement indiqué que des capacités telles que la sécurité au niveau des lignes (row-level security), le masquage des colonnes (column masking) et le contrôle d’accès fin basé sur les rôles (RBAC) sont des exigences prioritaires, en particulier pour les grandes organisations.
Les fournisseurs de plateformes de données, conscients de ces besoins critiques, s’efforcent d’étendre leurs cadres de sécurité et de gouvernance existants pour englober de manière transparente les tables Iceberg. Snowflake, par exemple, a explicitement annoncé l’application de ses contrôles de sécurité, de ses fonctionnalités de conformité, et même de ses capacités de continuité d’activité (réplication, reprise après sinistre) aux tables Iceberg gérées ou externes. L’objectif est d’offrir un niveau de contrôle et de protection équivalent à celui des tables natives, sécurisant ainsi les environnements lakehouse ouverts. Tous les fournisseurs s’efforcent de pourvoir un tel niveau de sécurité. Crunchy Data qui a annoncé son data warehouse soutenu par PostgreSQL et dont le stockage repose sur Apache Iceberg, a intégré nativement la sécurité de PostgreSQL à Iceberg ! Idem pour Dremio !
Le catalogue Iceberg joue un rôle central dans la mise en œuvre de ces politiques de gouvernance. Comme mentionné précédemment, les catalogues basés sur REST (et potentiellement standardisés via Apache Polaris) sont considérés comme le point d’application idéal pour définir et faire respecter les règles de sécurité et d’accès de manière cohérente, quel que soit le moteur de calcul utilisé pour interroger les données. Cependant, il a également été noté que les catalogues open source (OSS) sont actuellement en phase de rattrapage par rapport aux plateformes commerciales matures en ce qui concerne l’exhaustivité et la facilité de gestion des fonctionnalités de gouvernance d’entreprise.
8. Dynamique Communautaire et Perspectives d’Avenir
Le succès et l’évolution rapide d’Apache Iceberg reposent en grande partie sur une communauté open source dynamique et collaborative. L’Iceberg Summit 2025 a été une vitrine de cette communauté, rassemblant des contributeurs individuels, des ingénieurs de diverses entreprises et des utilisateurs pour partager leurs expériences et façonner collectivement l’avenir du projet. L’importance de l’implication communautaire a été soulignée à plusieurs reprises, que ce soit pour influencer la feuille de route technique, contribuer au code, améliorer la documentation (un excellent moyen de s’impliquer et d’apprendre), ou présenter des cas d’usage concrets et des meilleures pratiques lors d’événements comme le sommet.
Un facteur clé de cette dynamique est le soutien et l’investissement significatifs de la part des principaux acteurs de l’industrie. Des entreprises comme AWS, Snowflake, Microsoft, Dremio, et bien d’autres, ne sont pas seulement des utilisateurs d’Iceberg, mais aussi des contributeurs actifs à son développement, intégrant le format dans leurs plateformes et participant à sa gouvernance. Cette implication industrielle massive est un indicateur fort de l’importance stratégique d’Iceberg et agit comme un puissant catalyseur pour l’innovation. Il est particulièrement notable que cette collaboration se produise même entre concurrents directs, opérant sous le modèle de gouvernance neutre de l’Apache Software Foundation (ASF).
Ce modèle de « coopétition », où des entreprises concurrentes sur le marché collaborent au développement du standard ouvert sous-jacent, semble être un moteur majeur de l’accélération du développement d’Iceberg. Il apporte des ressources d’ingénierie considérables et des perspectives diverses au projet central, ce qui conduit probablement à une innovation plus rapide et à une plus grande robustesse par rapport à un projet mené par un seul fournisseur ou une communauté plus restreinte.
Les fournisseurs sont incités à contribuer en amont les fonctionnalités dont ils ont besoin pour leurs propres plateformes afin d’assurer la compatibilité et de tirer parti de l’écosystème plus large. Pour les utilisateurs, cela se traduit par une innovation rapide et un standard qui bénéficie des investissements de multiples acteurs.
9. Conclusion : que retenir ?
L’Iceberg Summit 2025 a confirmé et éclairé la trajectoire ascendante d’Apache Iceberg en tant que standard de facto pour les tables analytiques dans les architectures de données modernes.
Les discussions et annonces ont mis en évidence plusieurs tendances clés qui façonneront son avenir à court et moyen terme.
L’évolution vers la version 4, avec son accent attendu sur une disposition adaptative des métadonnées, promet des gains de performance significatifs, en particulier pour des scénarios qui étaient moins optimisés auparavant, comme la lecture de petites tables.
Parallèlement, l’émergence des catalogues REST, potentiellement standardisés par Apache Polaris, est en passe de révolutionner l’interopérabilité et la gouvernance centralisée, découplant les moteurs de calcul de la gestion des métadonnées.
L’intégration de plus en plus profonde avec Python pour répondre aux besoins de la data science et de l’IA est devenue une priorité absolue, bien que des défis de performance subsistent, notamment pour les UDFs.
Face à la complexité inhérente aux déploiements à grande échelle, en particulier avec l’ingestion en streaming, la nécessité d’une automatisation poussée de la maintenance, de l’adoption de pratiques DevOps et de solutions d’observabilité des données est devenue incontournable.
Enfin, la quête de performances optimales se poursuit sur plusieurs fronts (moteurs, format, fichiers sous-jacents), et la maturation des fonctionnalités de gouvernance est essentielle pour l’adoption en entreprise.
La valeur fondamentale d’Apache Iceberg réside dans sa capacité à fournir une fondation ouverte, fiable et performante, comblant efficacement le fossé historique entre la flexibilité brute des data lakes et la structure rigide mais fiable des data warehouses. Il permet aux organisations de construire des lakehouses ouverts.,
En définitive, Apache Iceberg semble solidement engagé sur une trajectoire de croissance continue et de consolidation en tant que pilier incontournable de l’écosystème des données ouvertes. Poussé par la collaboration communautaire et les investissements stratégiques de l’industrie, il est bien positionné pour continuer à définir l’avenir des infrastructures de données analytiques.
Vous pouvez découvrir en détail Apache Iceberg avec notre livre blanc.
Toutes les sessions de Iceberg Summit 2025.