

Bravo, vous avez parcouru plusieurs articles qui tentent de vous apporter quelques éclaircissements dans votre choix de data warehouse dans le cloud. Vous avez pu découvrir comment il était simple de prendre en main des solutions telles que:
Vous pouvez revenir aux critères de sélection des data warehouse dans le cloud.
Pour finir cette série d’articles nous proposons de comparer leur performance technique.
Les résultats qui sont présentés ici sont ceux de Fivetran, un éditeur d’ETL en SAAS. Leur benchmark est remarquable car ils ont fait de choix de sélectionner des critères d’évaluations au plus proche de la réalité des entreprises. De même, leur benchmark est open source et s’appuie sur des standards (99 TPC-DS). Pour rester dans des cas proches des ceux des organisations il propose une vaste variétés de requêtes, des jointures (nombreuses), des modèles orientés datamart. Une attention toute particulière a été porté aux mécanismes de “caching” dont disposent les moteurs de data warehouse.
Pour ce qui est des coûts et afin de faciliter la lecture, tout a été ramené et synthétisé à un coût moyen pour chaque requête.
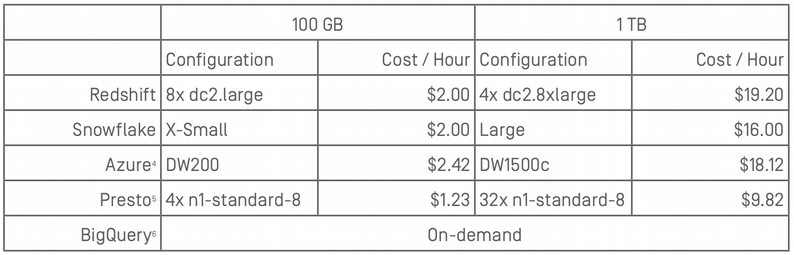
Les benchmarks ont été menés selon deux volumes de données distincts : 100 Go et 1 To.
En effet, le plus souvent les clients de Fivetran ont des volumes de données qui vont de quelques dizaines de gigaoctets de données à quelques centaines. La table de fait la plus large va de 400 millions de lignes pour le scénario à 100 Go jusqu’à 4 milliards de ligne dans le cas du scénario à 1 To.
Les infrastructures qui ont soutenu les tests sont les suivants :
Presto DB
L’idée était de proposer un comparatif entre les entrepôts de donnée du cloud. PrestoDB existe chez AWS en tant que service managé et est open source. Presto dépend fortement de la manière dont vous stockez les données. Presto a récemment obtenu un planificateur de requêtes basé sur les coûts, développé au cours de la dernière année par les équipes Presto de Facebook et Starburst. Cela fait une énorme différence de performance sur le benchmark TPC-DS, mais cela dépend des statistiques précises sur les tables pour estimer le coût d’exécution des requêtes. Pour ce benchmark Fivetran s’est basé sur une installation de PrestoDB avec pour stockage HDFS, des fichiers au format ORC, Hive et son métastore pour avoir les statistiques par table.
PrestoDB est open source et vous pouvez vous rendre compte qu’il ne démérite pas !
La plus performante
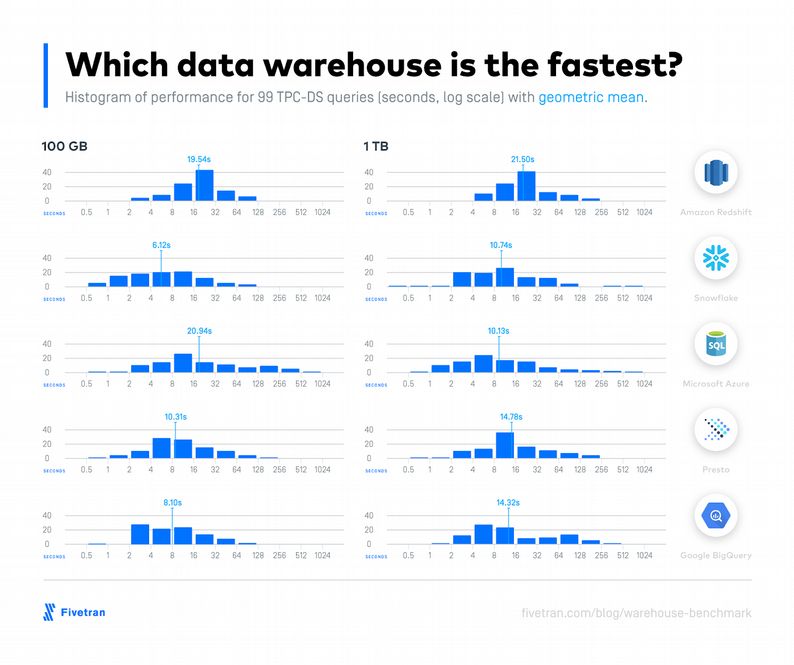
Comparaison trouvée ici
Redshift était environ 2x plus lent que les entrepôts les plus rapides, en raison du ralentissement de son “compilateur de requêtes”. Cependant, en se basant sur les temps des deuxième exécution en lieu et place des premières, Redshift aurait pu être l’entrepôt le plus rapide
Les performances d’Azure sont proches des autres data warehouses pour un 1 To et diffère pour 100 Go. Ce résultat est obtenu parce que les tests ont été menés avec la 2ème génération (Gen2) de data warehouse d’Azure pour traiter 1 To, et la 1ère génération (Gen1) pour les 100 Go. La génération 2 n’étant pas encore disponible aux moments des tests pour 100 Go
Il y a peu de différence notable en passant à l’échelle ! Les temps moyens de réponse restent très acceptables avec une infrastructure qui évolue par rapport au volume. Cela a déjà été dit mais les performances sont tellement liées aux formats et à la structuration des données !
La moins chère
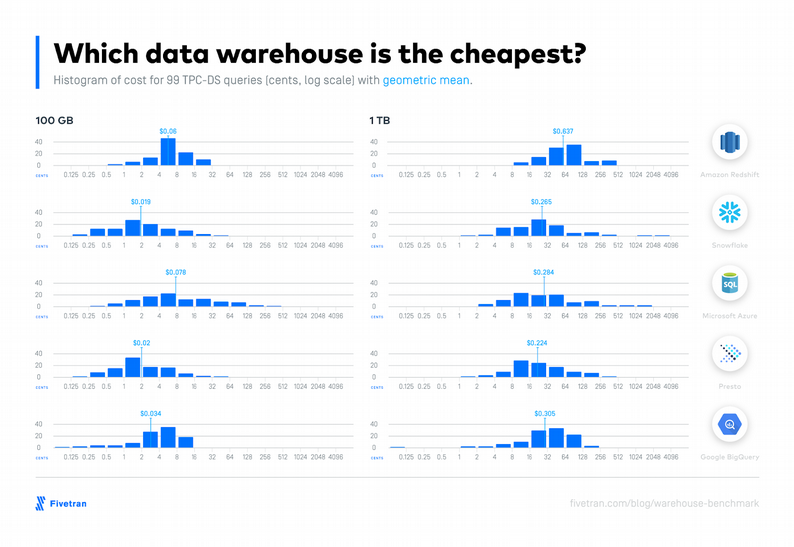
Comparaison trouvée ici
Bigquery facture à la requête, il était donc important de trouver une manière d’homogénéiser la lecture quant au coût engendré par l’utilisation de data warehouse dans le cloud. Le temps passé à exécuter les requêtes, le nombre de requêtes concurrentes potentielles sont autant de critères pris en compte pour arriver à obtenir ce coût moyen par requête.
Résultat du benchmark
Evidemment que les coûts de possession et les performances ne peuvent être les seuls critères à prendre en compte. Et surtout il va falloir considérer bien d’autres facteurs. Par exemple, la faciliter à traiter tel ou tel format de données ; comment est gérée la disponibilité du data warehouse ; comment se passe la mise à l’échelle ; la capacité à optimiser les jointures ! Avec le mouvement DataOps, l’automatisation prend une place certaine.
Un dernier critère et non des moindres à bien mesurer, est la capacité de ce data warehouse à s’inscrire dans votre écosystème existant.
Les conclusions de Fivetran peuvent apparaître très consensuelles mais résument bien ce que nous observons chez Synaltic.
“Ces entrepôts ont tous un excellent rapport coût / performance. Nous ne devrions pas être surpris qu’ils se ressemblent: les techniques de base pour la création d’un entrepôt de données orienté colonne rapide sont bien connues depuis que le document C-Store a été publié en 2005. Ces entrepôts de données utilisent sans aucun doute les mêmes solutions de performance standard : stockage colonne, planification des requêtes basée sur les coûts, plan d’exécution couplé à la compilation des requêtes en “juste à temps”.
Nous devrions être sceptiques si un entrepôt de données se vantait d’être beaucoup plus rapide qu’un autre.
Les différences les plus importantes entre les entrepôts sont des différences qualitatives engendrées par des choix de conception : certains entrepôts mettent l’accent sur la facilité de passer à l’échelle, d’autres sont faciles à utiliser.”
Ce que vous pouvez retenir de cette série d’articles, c’est notre volonté à vous partager nos connaissances, et notre capacité à accompagner vos choix.
Nous travaillons à la fois sur l’intégration des données (ETL, ESB) et sur toute la chaîne décisionnelle.
Avec le cloud nous sommes aujourd’hui en mesure de vous soutenir dans de tel projet et sur ce type de plateforme à la fois dans le cadre de manipulation de données, de traitements analytiques, de présentation et de diffusion. Fort d’une expertise de 15 années de projet de data warehouse, de notre SynalTeam formée à la fois sur l’infrastructure, le cloud, le management de la données, des nouveaux processus de déploiement en continue appliqués à la gestion des données (DataOps) nous vous offrons toutes les ressources pour réussir vos projet de data warehouse dans le cloud.
Si vous lisez notre blog, vous connaissez aisément nos valeurs “open source” ! Nous ne pouvons conclure un tel article sans rappeler cet attachement et lister les solutions open source qui répondent à cette problématique de data warehouse : MariaDB Columstore, Greenplum, Dremio et PrestoBD déjà cité.
Contactez-nous et parlons de vos données.
{kind=link}
{kind=link}