

La transformation digitale passe par la maîtrise de ses données, ce qui permet de construire une approche “Data Driven” pour guider sa stratégie.
Une telle approche nécessite à un moment ou à un autre la construction d’un Data Warehouse et plus largement un projet d’informatique décisionnelle.
Il est à noter que la construction du data warehouse peut s’inscrire dans une gestion de données bien plus large tel un Data Lake qui peut lui même être couplé à un Data Hub. Et non, ce ne sont pas forcément des synonymes.
Dans cet article, ou plutôt série d’articles, il va être question de data warehouse et de cloud. Les sollicitations pour adopter le cloud sont très importantes. Si choisir un data warehouse reste complexe, il l’est tout autant lorsqu’il est dans le cloud, par exemple comment faire lorsque son système d’information commence à être distribué chez plusieurs fournisseurs alors même qu’il a déjà une belle existence ‘on premise’ ?
Nous consacrerons ainsi un article pour chacun des candidats suivant et un benchmark de nos observations:

Qu’est-ce qu’un data warehouse ?
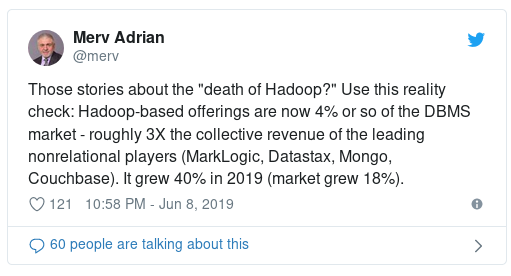
Même avec la progression d’Hadoop (40% par an), et l’adoption des data lakes, les sociétés sont encore nombreuses à opérer des data warehouses parce que leurs activités en dépendent. En effet, elles sont beaucoup à avoir besoin de données très intégrées, systématiquement nettoyées, faciles d’accès et historisées. Ce sont clairement les critères que spécifient les utilisateurs métier. Ces derniers recherchent donc un data warehouse aux caractéristiques suivantes :
- Orienté sujet : il s’agit d’organiser et structurer les données afin qu’elles facilitent le suivi d’un processus d’entités telles que le client, le produit, les ventes, les achats, la finance… Cela correspond généralement au “jargon”, à la sémantique du métier.
- Intégré : fournir une donnée fiable, homogénéisée quand bien même pour la constituer il faut réunir plusieurs sources ! Cette donnée ainsi “intégrée” est délivrée avec une qualité qui renforce la confiance de ses utilisateurs.
- Historisée : une fois la donnée capturée à intervalle régulier selon l’activité de l’organisation, elle prend un caractère invariant dans le temps ! Cette fréquence a pour but d’aider à dégager des tendances, et dresser des séries temporelles utiles aux analyses pour optimiser les activités de l’organisation.
- Non volatiles : ces “photos” prises à intervalles réguliers n’ont pas vocation à être modifiées ! Elles doivent supporter la construction de rapports fiables et “reproductibles” telle que s’est déroulée l’activité.
- Propres : de bruits qui perturbent une lecture fluide de l’activité ! Ici apparaissent toutes les questions liées à la qualité de données.
Si nous ne l’avons pas encore dit, il va de soi que le data warehouse est un système de stockage de données ; c’est une base de données ! Elle doit pour autant être distinguée des bases de données classiques. Même s’il est complètement possible d’exploiter une base de données transactionnelle tel un entrepôt de données, cela ne fait pas d’elle un data warehouse. Une base de données qui gère des applications fonctionne avec des transactions (OLTP). Or les data warehouses ont pour but l’analytique (OLAP).
Les challenges actuels des data warehouses
Depuis quelques années les acteurs du cloud se sont particulièrement distingués quant à leurs offres de data warehouse “à la demande”. En effet, une grande part d’acteurs a fait de tels choix et a migré vers le cloud.

Prévision sur l’évolution des services de data warehouse.
Avec autant de data warehouses qui font partie des fondements de nombreuses sociétés, il serait présomptueux de parler de la mort du data warehouse au profit du data lake. Choisissez les bons outils en fonction de vos besoins ! En effet, le data lake n’est pas l’alpha et l’oméga ! Il ne répond pas précisément aux caractéristiques précédemment décrites : certes il est une source de vérité dans de nombreux cas d’utilisation, mais il n’est certainement pas orienté sujet et intégré !
L’idéal est de coupler data lake, data warehouse et data hub pour répondre à l’ensemble des enjeux de la gestion des données.
L’importance de moderniser son approche du data warehouse.
Renforcer son data warehouse par un data lake ou tout simplement lui donner une nouvelle jeunesse est un projet d’entreprise ayant pour but d’augmenter la valeur de la donnée dans l’organisation et avec un impact positif et significatif sur son activité.
Un tel bénéfice est possible grâce à la variété des types de données qui peuvent être connectées : tant les transactionnelles, que celles qualifiées de big data dont la valeur ne peut être révélée sans un couplage aux premières.
Dans le cadre de data warehouses existants, il convient une fois de plus de les coupler à un data lake afin de décloisonner l’organisation et corréler des activités vues jusqu’alors de manière disjointe. Il faut donc bien noter que chaque brique de management de la donnée répond à des besoins spécifiques !
Toutefois, il convient d’exploiter au mieux Data Lake, Data Warehouse, Data Hub afin d’avoir un cadre qui réponde à la fois aux enjeux métiers tel que l’analytique, la gestion de références, la gestion de données de référence, la diffusion de données ; qu’aux enjeux techniques à savoir décloisonner la donnée, diminuer la redondance (la copie) et maximiser la réutilisabilité des données.
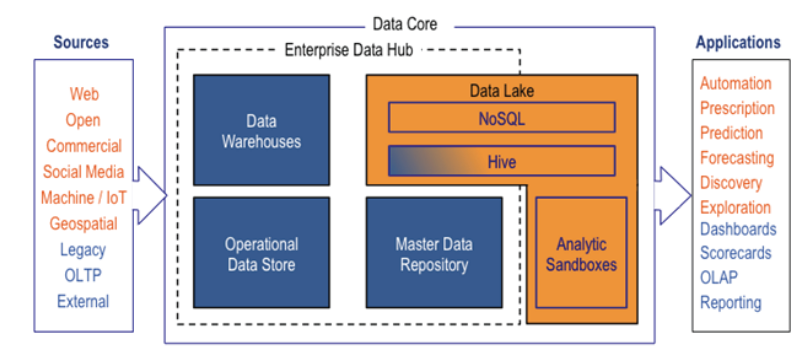
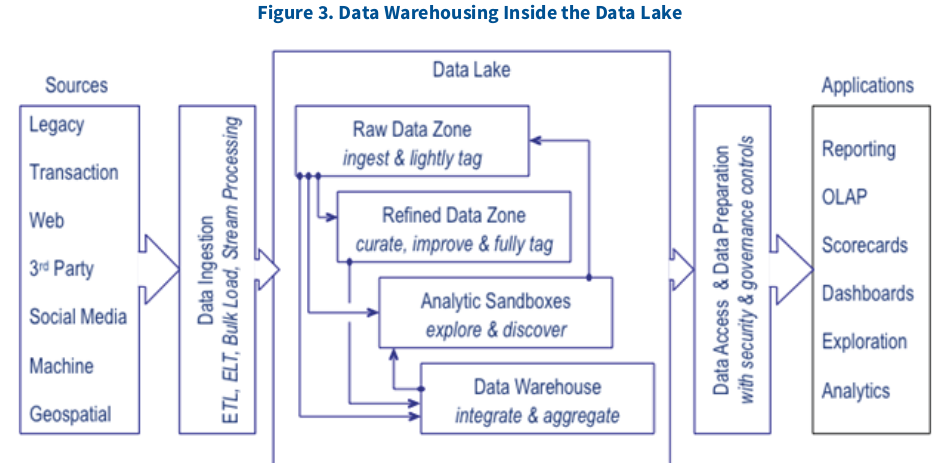
Le cloud, telle une optimisation de votre architecture de data warehouse.
Avoir une architecture qui tire déjà partie du cloud permet de franchir le pas vers un data warehouse dans le cloud.
Ce dernier vous apporte une capacité certaine pour passer aussi bien à l’échelle que bénéficier de l’élasticité des environnements. Vous retrouvez ces fonctionnalités aussi bien pour le stockage des données que pour les traitements. C’est sans compter le découplage des unités de stockage de ceux qui exécutent les traitements. Il est, de cette manière, possible d’allouer des unités de traitements toujours les plus optimisées à la quantité de données stockées.
Etant donné que ce sont des services “managés”, cela représente souvent moins de contraintes pour les équipes de l’organisation : en effet, cela implique moins de tâches d’administration et de gestion, aussi bien pour l’infrastructure que pour la base de données elle-même.
Les data warehouses hébergés progressent plus rapidement que ce même secteur “on premise”, à l’image de l’arrêt de Netenza et de l’offre DB2 Data Warehouse Cloud ! De même, le choix d’optimisation des coûts des organisations pousse les éditeurs à avoir des offres de plus en plus adaptées à ces nouvelles exigences. Ici, nous avons le cas de SAP qui fait de Hana le socle principal de toute son offre cloud y compris pour ce qui est du data warehouse.
Hadoop a bouleversé le marché du data warehousing et les acteurs de ce marché le lui rendent bien aujourd’hui, justifiant une lourdeur face au stockage cloud associé à une offre data warehouse lui aussi dans le cloud. L’idée étant d’ingérer la même variété de données, de simplifier les couches applicatives et prôner une connectivité pour l’ensemble de l’écosystème du système d’information. Il est pour cela bien entendu que les performances des réseaux améliorent les délais d’acheminement de la donnée depuis le cloud jusqu’aux équipements des organisations.
Même si les éditeurs de data warehouse pour le cloud proclament qu’ils font mieux qu’Hadoop, ils sont loin d’offrir toutes les fonctionnalités existantes et totalement intégrées des distributions telles Cloudera et son désormais futur CDP.
Cependant, il est certain que le data warehouse dans le cloud, ou à la demande, offre le “pay as you go” : une facturation à la consommation et sans un investissement lourd au départ, ce qui reste vrai pour des structures dont la progression de la quantité de données et des traitements évolue assez lentement.
La flexibilité des data warehouses dans le cloud se caractérise aussi par leurs API qui vont permettre des automatisations jusqu’ici jamais considérées.
Comment choisir alors son data warehouse ?
Faut-il choisir le cloud ?
Cette réponse peut être très simple si la majorité des données se trouve déjà dans le cloud. De manière similaire si toutes vos données sont “on premise” vous voudrez sans doute la garder en interne. Ces deux points de vue sont renforcés surtout si la quantité de données transportées sur le réseau s’avère trop conséquente.
Toutefois, quand bien même vos données sont en majorité en interne, vous souhaitez sûrement en partager le résultat avec vos partenaires et votre écosystème. Il s’agit certainement d’un argument qui vous pousse à reconsidérer la question. N’est-ce pas ?
Voilà quelques critères à considérer pour choisir un data warehouse dans le cloud.
Transparence des coûts
Ne faites pas des coûts le seul critère de votre choix ; mais il est clair qu’il sera incontestablement un des plus importants que vous considérerez.
Déployer une infrastructure de data warehousing on premise propose une lisibilité limpide des coûts. Ce n’est pas tant le cas pour ce qui est du cloud. Même si peu de DSI n’ont jamais fait le calcul du coût moyen d’une requête sur leur data warehouse, de l’infrastructure qui la soutient, des ingénieurs qui y travaillent, il faut bien avoir en tête que désormais les fournisseurs d’entrepôt de données en SAAS proposent leurs prix selon ces critères.
Chaque acteur possède son propre modèle de tarification.
Amazon Redshift, par exemple, facture en se basant sur le type d’instance qui soutient votre data warehouse, quand Big Query de Google Cloud Platform facture d’une part la quantité de données stockées et d’autre part celle qui est balayée à chaque requête. L’organisation et le format des données employé modifient aussi le tarif qui vous sera appliqué. La prédictibilité du tarif est souvent difficile. On y parvient seulement une fois que quelques semaines voire mois à exploiter la solution sont passés.
Voilà pourquoi il vous faut bien comprendre le modèle tarifaire de la solution retenue.
Intégration
Un data warehouse n’existe généralement pas juste pour lui-même. Il s’inscrit dans une architecture décisionnelle, et est le réceptacle du système opérationnel. Il est donc important de sélectionner une solution qui permet de tirer partie au mieux de son écosystème (existant ou à venir).
Fiabilité
Il est facile de vous dire que les sociétés telles que Google, Amazon, Microsoft ou même OVH en France sont des marques qui attirent tous les talents. Il est tout aussi facile de comprendre qu’ils hébergeront certainement mieux que nous autres une infrastructure distribuée, redondée et optimiseront le data warehouse qu’ils ont eux-mêmes conçu. Mais il n’y a pas de solution parfaite : rappelez vous comment ces sociétés communiquent lorsqu’elles font face à des incidents très impactants. Assurez vous alors de bien comprendre comment fonctionne le support.
Performance
Il y a deux grands axes de performance : accès aux données et rapidité des traitements. Est-ce-que la solution retenue ingère rapidement de la donnée, sait l’analyser dans des délais acceptables et la restituer sous les 5 secondes, par exemple. Qui veut attendre aujourd’hui ?
Tout comme les modèles tarifaires, chaque fournisseur met l’accent sur des points particuliers pour améliorer les performances de sa solution.
Amazon Redshift propose un format orienté colonne et du traitement massivement parallèle.
Google Big Query utilise autant de ressources nécessaires pour fournir les résultats en quelques secondes.
Snowflake ne partage aucune ressource entre les data warehouses, ainsi aucune requête d’un data warehouse n’est impactée par une autre d’un autre data warehouse. Azure gen 2 propose un cocktail des différentes solutions suscitées.
Bien entendu la performance est aussi fonction d’optimisation des formats de données, de la structuration (partition, index…). Vous aurez besoin d’ETL, afin de bien gérer le cycle de vie des données de leur collecte, en passant par les processus de qualité (déduplication, homogénéisation…) jusqu’à leur agrégation pour leur diffusion. Vous pourrez faire sans ETL mais c’est sûr qu’il vous manquera la productivité, et un suivi ciblé de vos traitements.
Passage à l’échelle / auto-scaling
Si votre activité connaît une forte croissance, votre data warehouse devra suivre ! Cette élasticité se mesure selon trois axes : les coûts, les ressources et la simplicité.
Bigquery est incroyablement élastique ! il se retaille rapidement et simplement jusqu’au petaoctet, et ne réclame aucun suivi ou analyse pour s’assurer que le cluster dispose de toutes les ressources qui lui sont utiles. Bigquery s’occupe de tout.
Redshift a besoin de plus de maintenance que Bigquery, bien optimisé le coût peut être plus intéressant. Redshift passe à l’échelle horizontalement ; cela signifie qu’il suffit de lui rajouter des noeuds.
Snowflake reste tout aussi une solution peu onéreuse, car il facture le stockage après compression ! Mais il peut toutefois être difficile de construire son budget en fonction des quantités de données que génère son activité et donc savoir combien est-ce que ça peut coûter.
Snowflake fournit une option d’auto-scaling, qui peut être démarré ou arrêté dynamiquement au besoin selon les traitements que vous avez à gérer.
Azure a une approche comme Snowflake avec un découplage du stockage et du calcul, permettant d’améliorer le rapport le passage à l’échelle – rentabilité. Ce découplage signifie qu’ils peuvent être mis à l’échelle indépendamment et que vous pouvez suspendre et reprendre le cluster. Le stockage d’objets “blob” persiste même lorsque les calculs sont peu importants.
Les prochains articles vous détaillent les différentes data warehouse du cloud.
Contactez-nous et parlons de vos données.


[…] https://www.synaltic.fr/blog/cloud-data-warehouse-comment-choisir-votre-data-warehouse-dans-le-cloud… ! […]