Maintenant que nous vous avons détaillé comment choisir votre data warehouse dans le cloud nous vous proposons la découverte de quelques unes du marché:
- Snowflake
- AWS Redshift
- Google Big Query
- Azure Data Warehouse
- Benchmark
Vous pouvez revenir aux critères de sélection des data warehouse dans le cloud.
Nous avons voulu tester nous-même ces data warehouses pour nous en faire notre propre idée.
Étant habitués aux entrepôts de données et aux bases de données en général nous voulions surtout nous rendre compte à quel point il était simple de se lancer dans un projet.
En guise d’introduction
Comme les solutions d’Oracle et de Microsoft, Amazon Redshift n’a pas été conçu spécifiquement pour le cloud ! Il repose sur une solution existante d’entrepôt de données “on premise”, ParAccel, achetée auprès d’Actian en 2011.
Redshift offre une architecture de traitement massivement parallèle (MPP) sur une base de données orientée colonne pour prendre en charge l’exécution rapide de requêtes analytiques balayant des téraoctets aux pétaoctets de données. Un entrepôt de données peut être déployé en quelques minutes sur des noeuds de calcul ou de stockage denses commençant à partir d’un SSD de 160 Go seulement, atteignant 2 pétaoctets de stockage (sur disque) avec un cluster de 128 machines.
Amazon Redshift a récemment lancé Spectrum qui prend en charge l’élasticité à la volée avec un séparation des calculs et du stockage.
Scénario
Nous avons poussé des données dans AWS S3, créé une table alimentée par des fichiers qui en sont issus et exécuté des requêtes.
create table trips_csv (
trip_id INTEGER NOT NULL IDENTITY(1,1),
vendor_id VARCHAR(3),
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
passenger_count SMALLINT,
trip_distance DECIMAL(6,3),
pickup_longitude DECIMAL(18,14),
pickup_latitude DECIMAL(18,14),
rate_code SMALLINT,
store_and_fwd_flag VARCHAR(1),
dropoff_longitude DECIMAL(18,14),
dropoff_latitude DECIMAL(18,14),
payment_type VARCHAR(3),
fare_amount DECIMAL(6,2),
surcharge DECIMAL(6,2),
mta_tax DECIMAL(6,2),
tip_amount DECIMAL(6,2),
tolls_amount DECIMAL(6,2),
total_amount DECIMAL(6,2)
);
La table ainsi créée est très proche de celle utilisée pour Snowflake (Ici encore le langage de requêtage SQL correspond au standard connu).
Chargement des données
COPY trips_csv
FROM 's3://<>/csv/yellow_tripdata_2012-11.csv'
access_key_id '<>'
secret_access_key '<>'
DELIMITER ','
EMPTYASNULL
ESCAPE
MAXERROR 10
REMOVEQUOTES
TRIMBLANKS
TRUNCATECOLUMNS;
Rappelez vous bien que Redshift est une base de données dédiée à de l’analytique (OLAP), il n’est donc pas question d’y insérer des données ligne à ligne ! Vous devez charger des données massivement ! Et cela passe via S3 !
Exécution des requêtes
select
count(*) as nb_trips
from public.trips_csv;
select
vendor_id,
count(*) as nb_trips,
avg(TIP_AMOUNT) as avg_tip_amount
from public.trips_csv
group by vendor_id;
select
extract(year from PICKUP_DATETIME) as pickup_year,
extract(month from PICKUP_DATETIME) as pickup_month,
extract(day from PICKUP_DATETIME) as pickup_day,
count(*) as nb_trips,
avg(TIP_AMOUNT) as avg_tip_amount
from public.trips_csv
group by 1, 2, 3
order by 1, 2, 3;
La première exécution d’une requête sur Redshift est toujours plus longue que si vous l’exécuter une nouvelle fois. Cela se comprend parce que vos “reporting” ou tableaux de bord sont demandés par plusieurs utilisateurs.
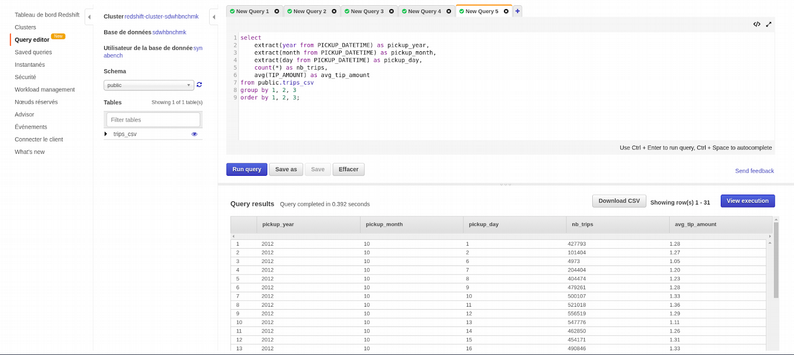
AWS offre un client pour lancer ses requêtes, même si nous en avons tous un tel DBeaver, ou Aquadata Studio.
Bonus
En 2017 AWS rajoute Spectrum à Redshift pour accéder à des données qui ne sont pas portée par lui-même. On peut ainsi lire des donnée dites “externes”.
CREATE EXTERNAL TABLE external_schema.click_stream (
time timestamp,
user_id int
)
STORED AS TEXTFILE
LOCATION 's3://myevents/clicks/'
Il est probable que le marché de l’analytique est en train de vivre une révolution : “SQL on Every Thing” ! C’est chez Facebook où tout a commencé avec PrestoDB, puis Google avec Big Query, y adjoignant au passage l’”autoscaling”. C’est assez naturellement que le marché concurrentiel amène AWS à le proposer d’abord avec Athena (PrestoDB en “mode managé” chez AWS) et plus tard avec Redshift Spectrum.
Appréciation Générale
Redshift est un service d’entrepôt de données entièrement géré avec des sauvegardes, des mises à niveau et des correctifs appliqués automatiquement. Il se prend assez facilement en main ! Cependant, malgré des avantages incontestables, Redshift réclame de la maintenance technique et du support de la part de DBA.