

Conférence POSS 2019 : Streaming Processing avec Debezium de Charly Clairmont, CTO et Yabir Canario De La Mota, Data Engineer chez Synaltic.
Conférence POSS 2019 : Streaming Processing avec Debezium
De la base de données classique au streaming avec Debezium
« Toute organisation a un système d’information réparti sur un nombre d’applications plus ou moins important. Aujourd’hui, elle cherche à obtenir une vision homogène, fédérée, en quasi-temps réel de son activité, si bien que nous avons des demandes client pour lesquelles il est question de fournir aux métiers une information « instantanée » et non plus “vieille de 5 minutes” !
Le CDC (change data capture) existe depuis longtemps, mais avec une mise en œuvre ô combien complexe et coûteuse en performance !

Change Data Capture
Pour résumer, le CDC permet de capturer ce qu’il se passe au sein de votre base de données au moment où elle se produit. (chaque insertion, suppression, et modification…)
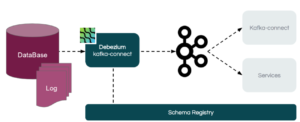
Qu’est-ce-que Debezium ?
Debezium est une plateforme distribuée open source pour le CDC. Sa simplicité de mise en œuvre, son ouverture (open source, multi-bases de données et multi-plateformes de streaming…), ses performances la rendent unique et la placent telle une brique incontournable du système d’information.
En outre, les métiers vont enfin avoir des indicateurs de leurs processus, instantanément, couvrant ainsi de nombreux cas d’usage. (personnalisation client, audit, vision client 360° instantanée, monitoring temps réel…)
“Debezium est certainement l’un des projets les plus importants que puissent connaître notre informatique moderne”
Certes, il vient s’appuyer sur Apache Kafka et désormais Apache Pulsar, cependant, il possède déjà un certain écosystème qui en fait une brique importante. Autrement dit, cela permet de mieux dialoguer avec les systèmes d’information actuels (legacy) et d’apporter du « streaming » aux bases de données classiques.
Quels sont les avantages de Debezium ?
- Simplifie la mise en place du CDC
- Accélère la propagation des changements
- DB Agnostique
- Tolérant à la panne
- Du Batch au Streaming
Une démonstration par Yabir :
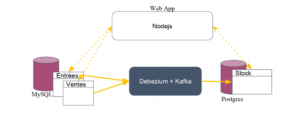
Une plateforme de commerce dont les flux de données sont soutenus par Debezium.
Le modèle de données :
- La gestion des ventes se fait dans une base de données MySQL
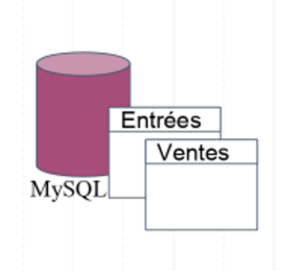
- La gestion des stocks se fait dans PostgreSQL

Le flux de données est le suivant :
- L’application e-commerce gère les ventes et met à jour les enregistrements des ventes
- Une notification des nouvelles ventes dans la gestion des stocks
- Le stock peut alors être mis à jour
Dans le détail, cet exemple, tire des données de la base MySQL, procède aux transformations au sein de Apache Kafka via KSQL et délivre les données mises à jour aux tables PostgreSQL.
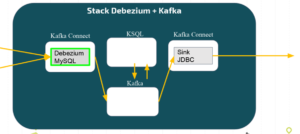
Stack Debezium + Kafka
En conclusion, Debezium peut moderniser les infrastructures “legacy” des organisations. Et ainsi, permettre d’avoir une vision en “temps réel” de leurs activités.
