

Conférence POSS 2019 : Gouvernance technique des données, retour d’expérience RTE, Charly Clairmont, CTO chez Synaltic et Arnaud Renard, Responsable Big Data chez RTE.

Conférence POSS 2019 : Gouvernance technique des données
De la multiplicité et la complexité des données à la gouvernance technique des données
En plus de la complexité fonctionnelle des systèmes d’information se rajoute désormais celle lié à leur fiabilisation. En effet, les organisations font face à la multiplicité de sources de données (SGBD, Système de fichiers, NoSQL, Cloud Storage…) et l’hétérogénéité des formats (table, csv, json, xml, avro, parquet, ORC, …)
Architecture hétérogène pour répondre aux nombreux besoins de l’organisation
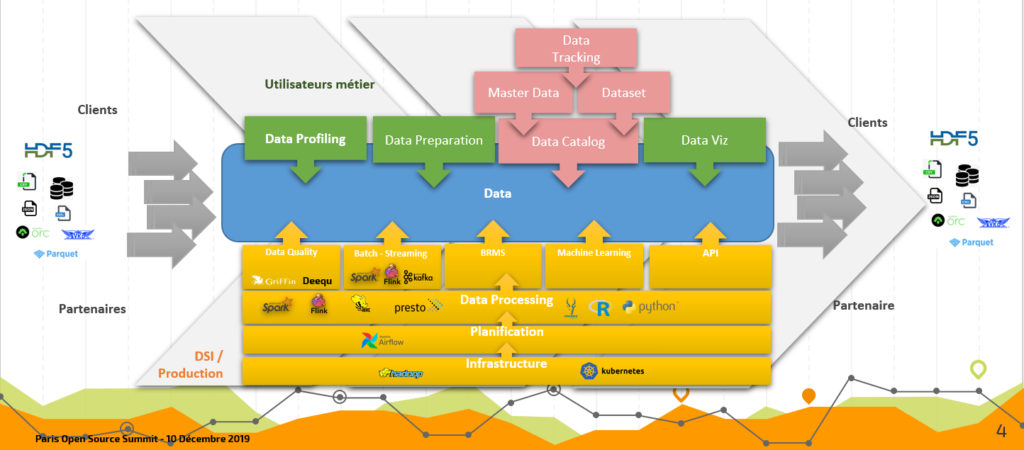
Nombreux formats, nombreux cas d’usage… Comment s’y retrouve-t-on ?
Bien évidemment, elles mettent des flux d’intégration pour une synchronisation de leurs solutions logicielles.
Et une grande partie de ceux-ci ont vocation à obtenir une vision unifiée et homogène des données, composée désormais des couches data lake, data warehouse, data hub.
La donnée accessible à tous
Dans une seconde phase, les processus de décision viennent s’appuyer sur ce socle structuré de données via différents types d’utilisateurs. À la fois consommateurs et acteurs, qui y accèdent en self-service (autonomie).
Pour construire leurs analyses et autres prédictions, de nombreux traitements sont élaborés, exécutés et fournissent des résultats souvent sous forme de jeux de données, qui sont eux-mêmes réutilisés par d’autres process.
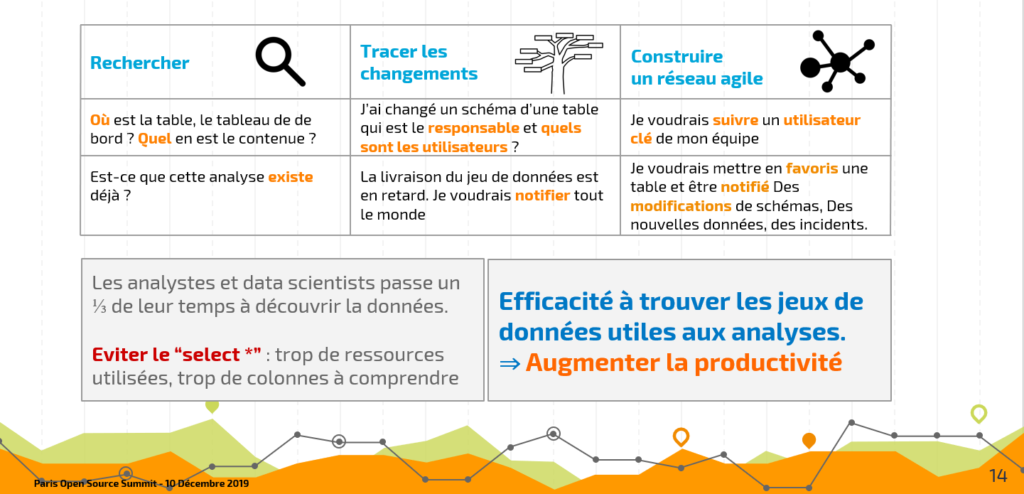
Désormais, les organisations se préoccupent de faciliter la découverte et la navigation de toute cette profusion de données. Elles souhaitent en même temps avoir une traçabilité fine de l’utilisation qui est faite des données.
Faciliter la découverte des données
En open source, il existe différentes initiatives pour ce qui est de la gouvernance des données : Apache Atlas (Hadoop), Marquez (WeWork), Amundsen (Lyft)… Autrement dit, ces solutions s’intéressent principalement à la centralisation des métadonnées.
Synaltic apporte son expertise Dremio dans la chaîne de la gouvernance technique des données chez RTE.
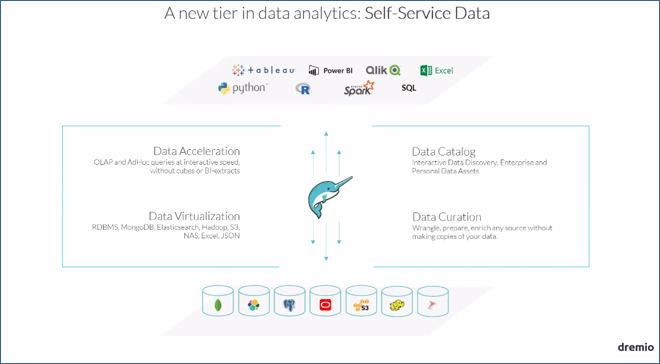
Dremio, un broker de données chez RTE
Dans le cadre de son DataLake, RTE, a commencé à bâtir une solution maison avant de retenir Dremio, pour offrir un point d’entrée unique sur l’ensemble de cet écosystème. Dremio sert différents usages aussi bien le catalogage de données que la base pour la construction d’analyse des usages. Ou encore pour faciliter l’accès aux data scientists depuis Rstudio.
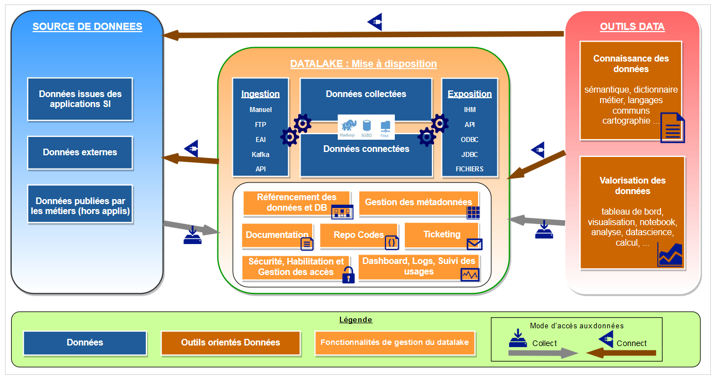
Quelle architecture ?
Ce qui est important ici, c’est que RTE a une infrastructure pour la gouvernance technique des données qui va au delà de Dremio.
Dremio n’est qu’une brique. C’est d’autant plus vrai que les formats de données, leur hétérogénéité est telle qu’une même solution ne sait complètement répondre à l’ensemble des fonctionnalités attendues :
- Référencement des données, des bases de données et des sources des données
- Gestion des métadonnées
- Documentation de sources, des jeux de données
- La gestion des demandes
- Gestion des sources de codes
- Gestion de la sécurité des données
- Monitoring, suivi de l’utilisation des données, des usages
