

Dremio : support DML via Apache Iceberg, un article de blog proposé par Charly CLAIRMONT, CTO au sein de la #SynalTeam.
Dans la gestion de données analytique, Dremio est un peu à part !
- Il propose de la “Virtualisation de données” comme Denodo.
- Comme Trino, PrestoDB, Starburst, Athena, il propose un moteur SQL performant pour traiter massivement les données en parallèle.
- Comme Databricks, Snowflakes, BigQuery, il propose une solution de Data Lakehouse en cloud quasiment du serverless
C’est aussi une interface intuitive pour naviguer dans les données et les manipuler y compris si l’on est un utilisateur métier. C’est encore en toute simplicité et sans omettre la sécurité que les utilisateurs peuvent partager très facilement les jeux de données au sein des organisations.
Par conséquent, Dremio regroupe tous ces avantages en même temps ; contrairement à ses concurrents.
Depuis sa version 22.0 – il y a un mois – Dremio prend en charge le support DML (Data Manipulation Language) pour Apache Iceberg ! Cela permet d’encore plus simplement transformer ses données directement à même votre lac de données via les commandes SQL DML standard. Telles que INSERT, UPDATE, MERGE INTO et DELETE de Dremio. Avec le support SELECT existant pour les tables Iceberg, il est possible d’exécuter n’importe quelle instruction SQL sur les données de votre data lakehouse avec Dremio.
Cette fonctionnalité est désormais disponible dans Dremio Cloud aussi.
Si Dremio disposait déjà des requêtes du type Create Table As Select, avec le support des instructions DML un bien plus grand nombre d’usages sont couverts.
Surtout, si vous avez l’habitude de confier vos requêtes complexes de manipulation, de structuration, de transformation de données à des entrepôts de données ou des outils externes au gestionnaire de base de données, vous pouvez directement le faire à même votre lac de données. Vous n’avez plus besoin de copier vos données dans un système d’entreposage de données fermé et peu flexible pour avoir toute la puissance de SQL à portée de main.
Le support des instructions DML
Il est activé par Apache Iceberg, un format de table hautes performances qui résout les problèmes liés aux tables traditionnelles dans les lacs de données. Il devient rapidement une norme de l’industrie pour la gestion des données dans les lacs de données ; en établissant la base d’un lac ouvert. Iceberg apporte la fiabilité et la simplicité des tables de base de données au Lakehouse ; tout en permettant à plusieurs moteurs de travailler ensemble sur les mêmes données de manière sûre et cohérente.
| CREATE TABLE IF NOT EXISTS « Local ». »t_airbnb_listings » ( « id » INT , « listing_url » VARCHAR , « last_scraped » DATE , « name » VARCHAR , « country » VARCHAR , « latitude » DOUBLE , « longitude » DOUBLE , « weekly_price » DOUBLE ); |
Nous obtenons donc notre table.
Préparons la requête qui alimente cette table :
SELECT
id,
listing_url,
TO_DATE(last_scraped, 'YYYY-MM-DD', 1) AS last_scraped,
name,
country,
CONVERT_TO_FLOAT(latitude, 1, 1, 0) AS latitude,
CONVERT_TO_FLOAT(longitude, 1, 1, 0) AS longitude,
CONVERT_TO_FLOAT(weekly_price, 1, 1, 0) AS weekly_price
FROM Samples."samples.dremio.com"."Dremio University"."airbnb_listings.csv" AS "airbnb_listings.csv"On l’exécute avec une instruction de type “Insert into”.
INSERT INTO "Local"."t_airbnb_listings"
SELECT
id,
listing_url,
TO_DATE(last_scraped, 'YYYY-MM-DD', 1) AS last_scraped,
name,
country,
CONVERT_TO_FLOAT(latitude, 1, 1, 0) AS latitude,
CONVERT_TO_FLOAT(longitude, 1, 1, 0) AS longitude,
CONVERT_TO_FLOAT(weekly_price, 1, 1, 0) AS weekly_price
FROM Samples."samples.dremio.com"."Dremio University"."airbnb_listings.csv" AS "airbnb_listings.csv"Vérifions que les données sont correctes.
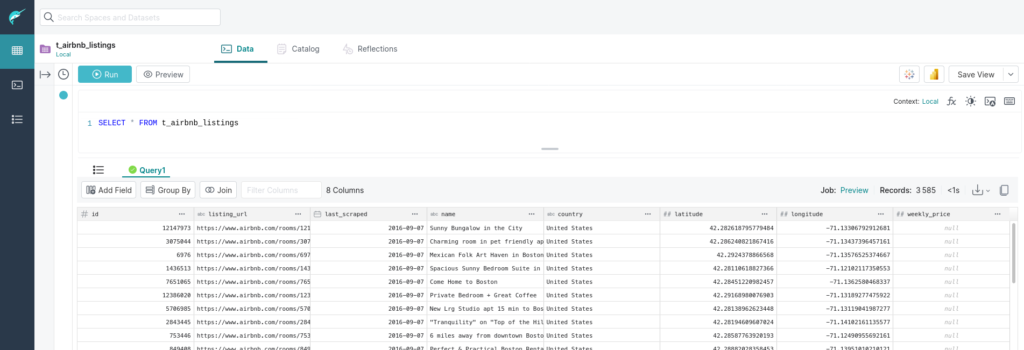
Il apparaît que tous les prix sont null. Nous avons une erreur dans la requête d’alimentation.
Vidons la table.
TRUNCATE TABLE t_airbnb_listingsAppliquons cette nouvelle requête avec la correction dans la requête Select.
INSERT INTO "Local"."t_airbnb_listings"
SELECT
id,
listing_url,
TO_DATE(last_scraped, 'YYYY-MM-DD', 1) AS last_scraped,
name,
country,
CONVERT_TO_FLOAT(latitude, 1, 1, 0) AS latitude,
CONVERT_TO_FLOAT(longitude, 1, 1, 0) AS longitude,
CONVERT_TO_FLOAT(SUBSTR(weekly_price, 2), 1, 1, 0) AS weekly_price
FROM Samples."samples.dremio.com"."Dremio University"."airbnb_listings.csv" AS "airbnb_listings.csv"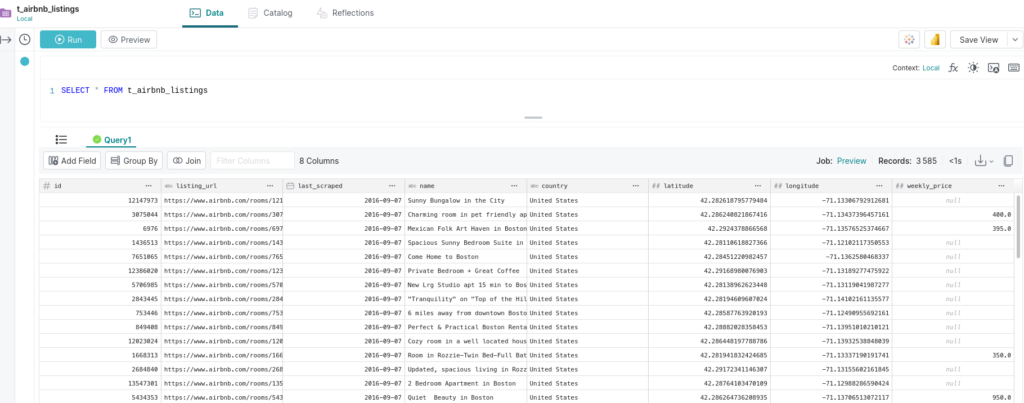
Tout compte fait, il y a toujours des valeurs null dans la colonne prix ! Nous décidons de passer tous ces prix manquant à 100 €.
UPDATE "Local"."t_airbnb_listings"
SET
weekly_price = 100.00
where t_airbnb_listings.weekly_price is null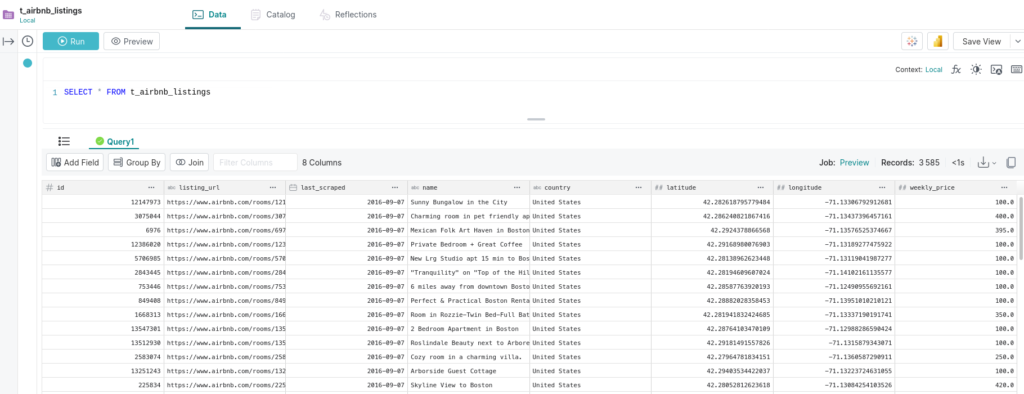
Et décidons de supprimer les lignes qui ont pour latitude 42.365028569643414.
DELETE FROM "Local"."t_airbnb_listings"
where t_airbnb_listings.latitude = 42.365028569643414Pour conclure : il est vrai que le support des instructions DML n’est pas une avancée du point de vue des bases de données ! Mais ici, vous pouvez le faire directement au-dessus de votre Data Lake et embrasser une architecture de type Data Lakehouse. En plus, un Data Lakehouse “ouvert” que vous maitrisez ! Plus besoin d’entrepôts de données extrêmement coûteux !
Ce qu’il faut retenir de ce support des instructions DML : c’est dès lors que vos sources de données sont connectées dans Dremio, vous pouvez très aisément collecter, manipuler, organiser, structurer et diffuser les données ; aussi simplement que vous le feriez avec une requête SQL.
Si vous souhaitez essayer Dremio, Synaltic est là pour vous aider. Nous avons mis au point des ateliers pour vous faciliter la prise en main et la découverte.
Catalogue de Formation