

Le 17 Novembre s’est tenu à Paris, à la Maison de la Mutualité, le Talend Connect, une journée de conférences et d’échanges qui regroupe les clients et les partenaires des solutions Talend. Notre envoyé spécial #SynalTeam du jour, Horacio Lassey, vous en propose un petit compte rendu !
La roadmap, moment fort de la conférence
C’est le CTO de Talend, Laurent Bride, qui était chargé de dévoiler la feuille de route de la société, fraîchement entrée au NASDAQ, depuis cet été. Son message s’articulait autour de 3 axes :
- Les progrès sur les dernières releases,
- La roadmap,
- Le futur des outils.
Les progrès sur les dernières releases
Concernant les progrès sur les dernières releases, il a cité le support de Git ainsi que les outils d’intégration continue, fonctionnalités entreprises très demandées, afin que Talend soit de plus en plus conforme aux cycles de développement logiciel agiles. Talend s’ouvre aussi de plus en plus aux métiers de l’entreprise avec par exemple l’intégration des composants de machine learning et les outils de libre-service.
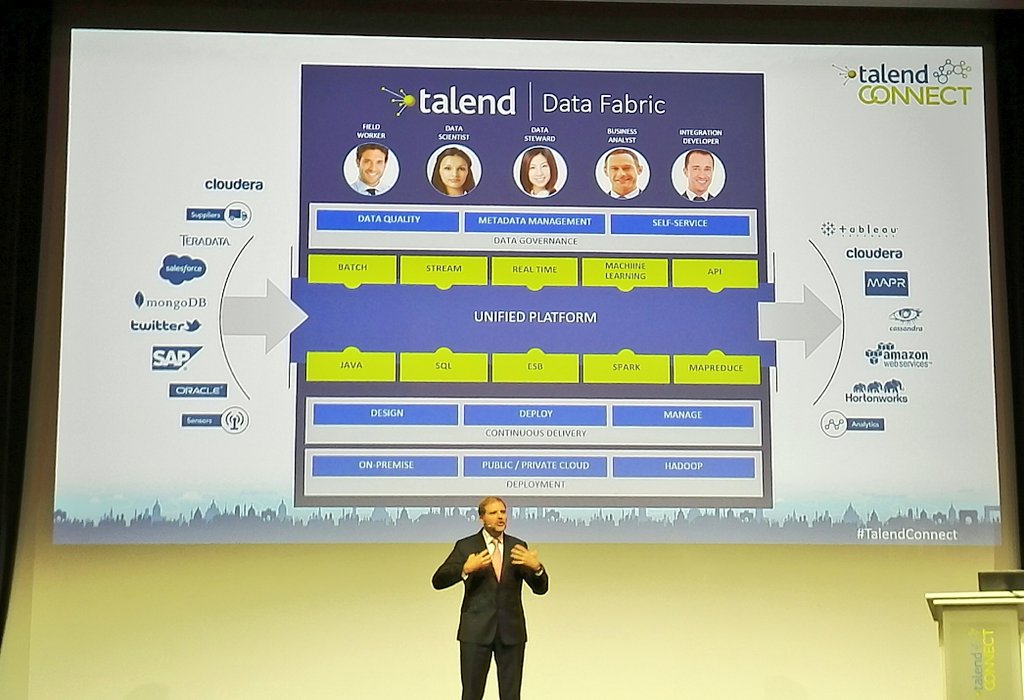
La roadmap
Les investissements de Talend sur les deux prochaines années vont tourner autour :
- du Big Data,
- du Cloud hybride,
- du Libre service,
- et de la Gouvernance.

A court terme la version 6.3, qui sortira courant janvier 2017, va mettre l’accent sur l’intégrité des données avec une nouvelle application de Data Stewadrship, la première version de Data prep pour Big Data, ainsi que la première version de Talend à générer du code Spark 2.0 (API unifié batch et streaming).

Cette version intégrera aussi Apache Atlas, framework de gouvernance de données et de métadata pour Hadoop. Dans les nouveaux composants qui feront leur apparition on peut citer : MapRDB , MapRStream, les composants AWS avec le support multipart upload etc…
Le futur des outils
Laurent Bride a également présenté les grandes mutations que l’on voyait dans le secteur de l’IT :
- Le batch processing qui devient du stream processing,
- Les data center internes qui deviennent du cloud hybride,
- Information mise à disposition par l’IT à la découverte des données par l’utilisateur métier.

Bien que la plupart des organisations se tournent de plus en plus vers du stream processing, le traitement de données par batch reste encore une pratique courante dans les entreprises. Le stream processing vient aussi avec son lot de contraintes comme le traitement des données en retard, le calcul par rapport au temps de traitement ou temps d’apparition de l’évènement. Un bon outil d’intégration doit être en mesure de gérer toute cette complexité de façon intrinsèque.
Talend annonce que ses prochaines versions nommées DataStream tourneront sur Apache Beam et auront une interface web. Apache Beam (pour Batch + strEAM) est un projet développé initialement par Google sous le nom Google DataFlow. Google a donné le projet à fondation Apache et réunit plusieurs grands acteurs comme (Cloudera, Talend, dataArtisans, PayPal etc). Il offre une couche d’abstraction pour faire les traitements batch et stream mais aussi permet de faire tourner le même code sur des environnements différents comme Google Cloud, Apache Spark, Flink, Apex etc…
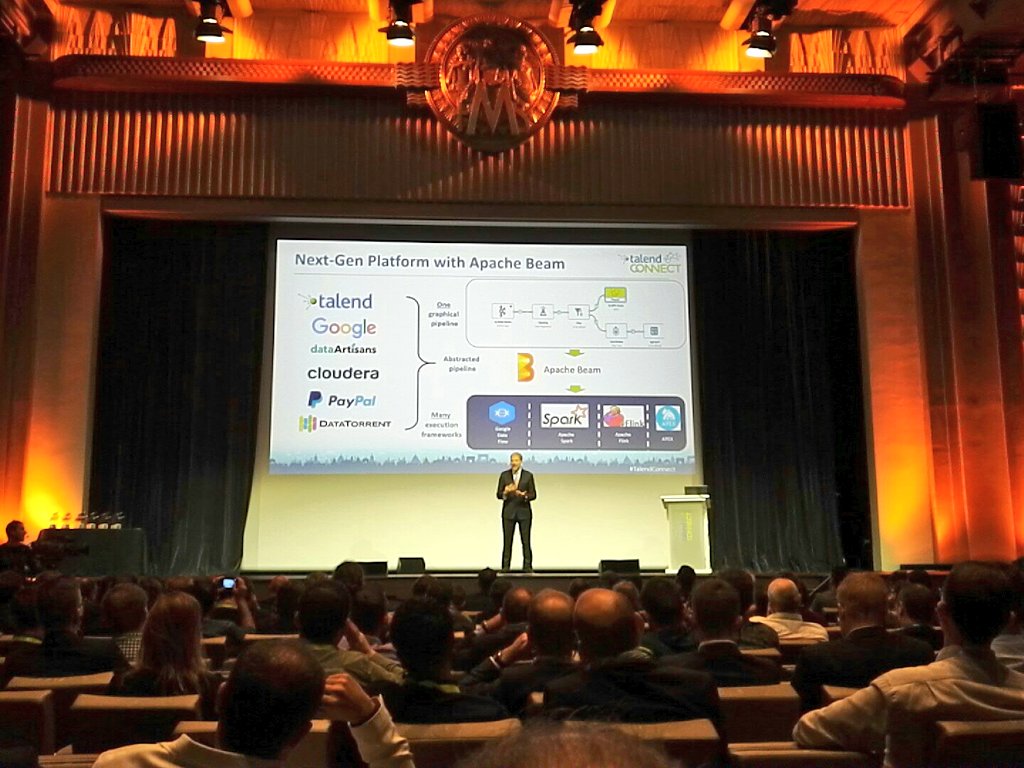
L’idée pour Talend est ainsi d’avoir une seule interface graphique qui gère les problématiques de traitement batch et de streaming tout en étant capable de s’exécuter sur plusieurs environnements. Pour ceux qui ont déjà pu observer peu sous le capot de leur Studio, Talend génère du code java avec le langage JET. C’est toute cette couche qui sera remplacée à terme par du code Apache Beam. Cela nécessite la réécriture du code de tous les composants. C’est donc un changement majeur sur le moteur interne des produits Talend. La première version de DataStream est annoncée pour le premier trimestre 2017.
Pour plus de détails sur le modèle derrière Apache Beam, je vous recommande de lire les deux billets de Tyler Akidau (en anglais) :
Horacio Lassey
Petit bonus ! La vidéo de Talend des meilleurs moments de la journée, avec des morceaux de #SynalTeam dedans !

Sections commentaires non disponible.