

Analyse ultra-rapide avec Tableau Online et Dremio, traduit et adapté du site de l’éditeur.
Analyse ultra-rapide avec Tableau Online et Dremio
Guide de configuration de Tableau Online Bridge avec Dremio
Aperçu
Tableau Bridge est un moyen de connecter votre instance Tableau Online à vos données. La connexion à des sources de données en ligne à l’aide de Tableau Online est facile, vous pouvez vous connecter à la fois aux données en direct et extraites en fonction de votre environnement.
Mais que se passe-t-il si vos sources de données changent constamment ?
Vous ne voudriez pas avoir à publier et re-publier vos classeurs chaque fois qu’un changement se produit au niveau du jeu de données. Il peut également y avoir des cas où la sécurité empêche l’accès aux sources de données internes (sur l’infrastructure on premise). Ce qui peut aussi être le cas pour Dremio. Avec Tableau Bridge, il est facile de créer une connexion sécurisée entre Tableau Online et vos ensembles de données internes, y compris Dremio.
Dans ce didacticiel, vous allez être guidé à travers les étapes :
- Pour configurer de Tableau Online avec Tableau Bridge
- Pour créer une connexion en direct à Dremio depuis Tableau Online
Besoin de se rafraîchir la mémoire sur Dremio ? Synaltic, partenaire officiel de la solution vous accompagne dans la découverte de cet outil !
Pré-requis
- Un cluster Dremio en cours d’exécution, consultez la documentation pour plus de détails sur la façon de déployer Dremio sur votre environnement. Synaltic peut aussi vous aider dans cette démarche
- Un système pour l’exécution de Tableau Bridge (doit être activé 24h / 24 et 7j / 7 pour les requêtes en direct)
- Tableau Desktop (pour la publication)
- Compte administrateur pour Tableau Online
Configurer Tableau Bridge avec Tableau Online
- Téléchargez les pilotes ODBC Dremio pour l’environnement sur lequel vous allez travailler.
- Téléchargez et installez Tableau Bridge sur la machine dédiée à l’exécution du pont.
- Installez Tableau Bridge sur la machine qui exécutera le pont. Le pont doit être disponible 24h / 24 et 7j / 7 pour l’utilisateur qui interagit avec Tableau de bord sur Tableau Online, sinon les requêtes échoueront.
- Ouvrez le pont et ajoutez une connexion à Tableau Online
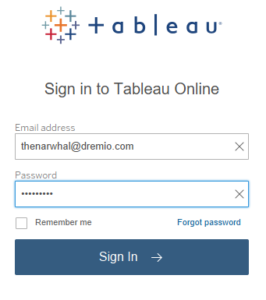
Maintenant sur votre navigateur, accédez à online.tableau.com et ouvrez le menu des paramètres en bas à gauche.
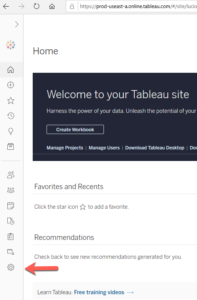
Sélectionnez l’option Pont en haut
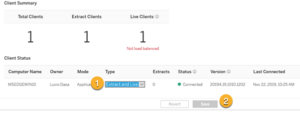
Cochez l’option : Enable Tableau Bridge clients to maintain live connections to on-premises data puis cliquez sur Enregistrer.
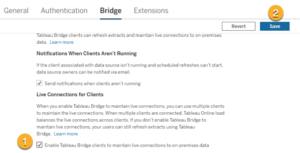
Dans la section État du client, définissez le nouveau pont sur Extract and Live, puis cliquez sur Enregistrer.
Configurer un tableau de bord et publier
Maintenant que tout est prêt, amusons-nous !
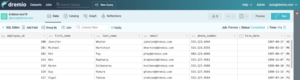
Tout d’abord, accédez à votre interface utilisateur Dremio et créez un jeu de données virtuel (VDS). Pour ce tutoriel, j’ai créé un VDS «Employé» qui est le résultat d’une jointure de deux ensembles de données différents provenant de PostgreSQL et SQL Server.
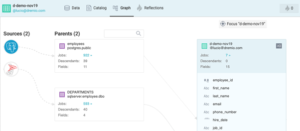
Nous pouvons vérifier la lignée de ces données dans l’entrée Graph.
Maintenant, créons un classeur dans Tableau à l’aide de l’ensemble de données résultant. Pour une explication détaillée de ce qui est sur le point de se passer, consultez notre didacticiel Visualiser votre premier ensemble de données avec Tableau .
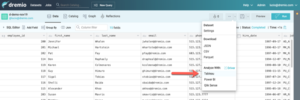
Tout d’abord, créez le fichier TDS pour l’ensemble de données que nous voulons visualiser, faites-le en cliquant sur l’ellipse à côté de l’icône de la disquette, puis sélectionnez Tableau dans le menu déroulant.
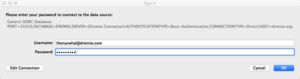
Ouvrez le fichier TDS et, lorsque vous y êtes invité, saisissez les mêmes informations d’identification que vous avez utilisées pour vous connecter à l’interface utilisateur Dremio.
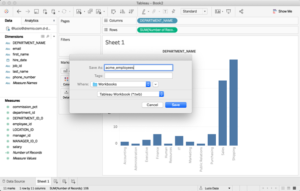
Créer et enregistrer le classeur.
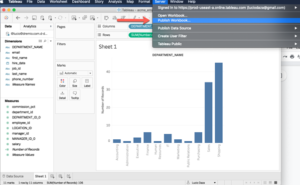
Ensuite, dans Tableau à partir du menu Serveur, vérifiez que vous êtes connecté, sinon connectez-vous au serveur à l’aide de vos informations d’identification Tableau Online, puis sélectionnez Publier le classeur.
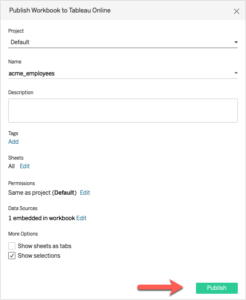
Laissez tous les paramètres par défaut et cliquez sur Publier.
Une fois le classeur publié correctement, vous recevrez la notification suivante (cliquez sur Terminé)
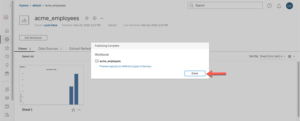
Testez votre connexion en direct Tableau Online
Vous pouvez utiliser deux méthodes pour vérifier que Tableau envoie des requêtes à Dremio et non à un extrait sur le serveur.
Première méthode : ouvrez votre classeur et sélectionnez Modifier le classeur.
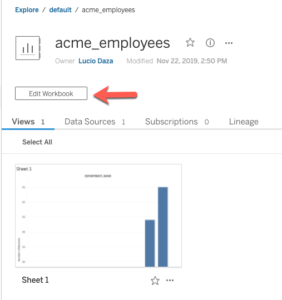
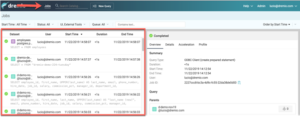
Apportez ensuite des modifications à votre classeur, puis explorez l’entrée Jobs dans l’interface utilisateur de Dremio.
Seconde méthode : à partir de Tableau Online, sélectionnez Sources de données et vérifiez que la source de données indique Live
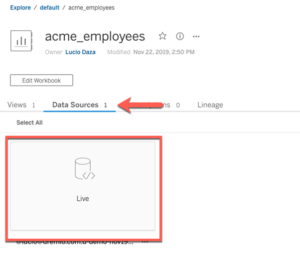
Il est tout à fait possible que la connexion dise “Extraire”, ce qui signifie que les requêtes ne sont pas envoyées à Dremio.
Pour résoudre ce problème, sélectionnez simplement les points de suspension sur le jeu de données et cliquez sur Modifier la connexion.
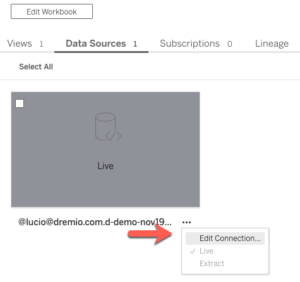
Ensuite, fournissez vos informations d’identification et informations sur le serveur et cliquez sur Enregistrer.
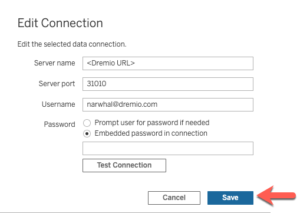
Comme le montre l’exemple ci-dessus, il est très simple de travailler avec vos classeurs Tableau sur Tableau Online tout en vous assurant qu’il existe une connexion en direct à Dremio. J’espère que vous avez apprécié ce didacticiel, visitez la bibliothèque de didacticiels de Dremio pour lire d’autres didacticiels comme celui-ci. Ainsi, découvrez comment Dremio, le moteur de lac de données, peut vous aider à obtenir des informations plus rapidement à partir de vos données.
Sources : https://www.dremio.com/tutorials/lightning-fast-analytics-with-tableau-online-and-dremio

[…] Analyse ultra rapide avec Tableau Online et Dremio […]