

Comment aider à appréhender une spécification : notamment celle pour qui vous aidera à définir vos data products.
Comment parler d’une spécification ? Comment expliquer à quoi ça sert ? Pourquoi un standard va vous aider dans vos tâches quotidiennes ? Plus de 20 ans que Synaltic accompagne les organisations à appréhender leur données. Décider avec les données n’est pas une petite affaire… et il faut reconnaître qu’il faut de la méthode. Pour éviter que l’on se perdre en conjecture plusieurs initiatives proposent des spécifications “standards” afin d’aller droit au but dans la définition des Data Products et des Data Contracts.
Nous avons choisi d’illustrer l’usage de telles spécifications par l’exemple et montrer comment une équipe data exploite de pareils outils.
Les coulisses
Avant de commencer nous allons vous présenter nos acteurs. Vous noterez que ce sont des personnages avertis. Ils sont organisés dans une Data Product Team.
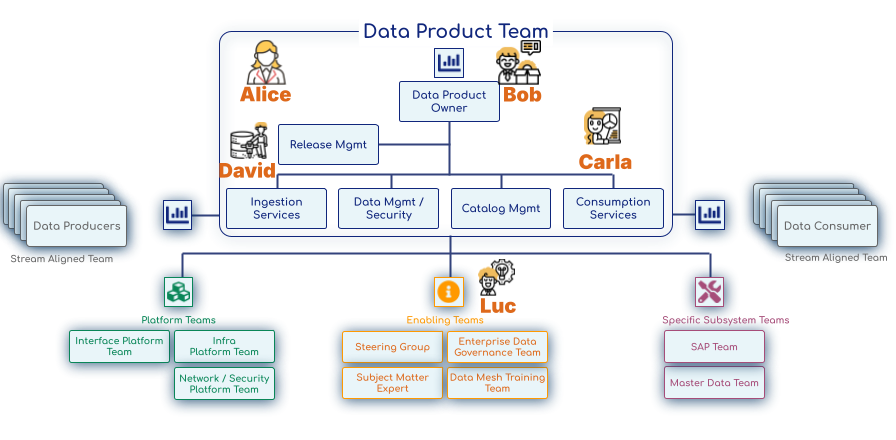
Nos acteurs
- Luc (Data Facilitator (Data Architect)) : Ce rôle correspond à un membre des « Enabling Teams » ou de l’architecture d’entreprise, dont la mission est d’aider les équipes alignées sur le flux de données (Data Product Teams) à surmonter les obstacles et à adopter les bonnes pratiques.
- Alice (Métier – Responsable des Ventes) : Elle représente le « Business Domain Expert » ou « Business Stakeholder » qui définit la valeur métier du Data Product et le consomme. Dans la topologie d’Eric Broda, les consommateurs de données sont souvent des « Consumer Teams » (Stream Aligned Teams).
- Bob (Business Analyst) : Il peut être vu comme un « Data Product Owner » (ou très proche de ce rôle) qui gère le backlog et la communication du Data Product, ou un « Metadata Management » si son rôle se concentre sur la sémantique métier. Le Data Product Owner est responsable de la feuille de route du produit de données et de la liaison avec les parties prenantes.
- Carla (Data Analyst) : Son rôle s’inscrit dans les « Consumption Services » au sein de la Data Product Team, car elle aide à définir comment les données seront consommées et assure leur qualité pour l’analyse.
- David (Data Engineer) : Il fait partie des « Ingestion Services » et « Data & Security Management » au sein de la Data Product Team, responsable de la construction des pipelines et de la gestion technique des données.
Le pitch
Dans le cadre d’une transformation Data Driven et en s’appuyant sur une vision Data Mesh ambitieuse, une responsable des ventes (Alice) frustrée par des rapports chaotiques met au défi son équipe de données de construire des « Data Product » fiables. Guidés par un architecte (Luc) perspicace et armés des « Data Contracts », ils devront relever le défi de modéliser les ventes de Northwind (L’entreprise), prouvant que la clé de l’analyse future réside moins dans la technologie que dans la clarté et la confiance des données.
Planter le décor
Luc (Data Facilitator (Data Architect)) : Bonjour à tous et bienvenue ! Aujourd’hui, nous allons explorer un concept clé de l’architecture Data Mesh : les Data Contracts et Data Products. Pour initier nos travaux, nous utiliserons notre base de données principale. Elle se nomme comme notre entreprise du reste : Northwind. Bien sûr c’est notre base opérationnelle. Notre objectif est de bâtir une version analytique sous forme de Data Warehouse. Nous allons nous appuyer sur une architecture Data Mesh pour parvenir à cet objectif.
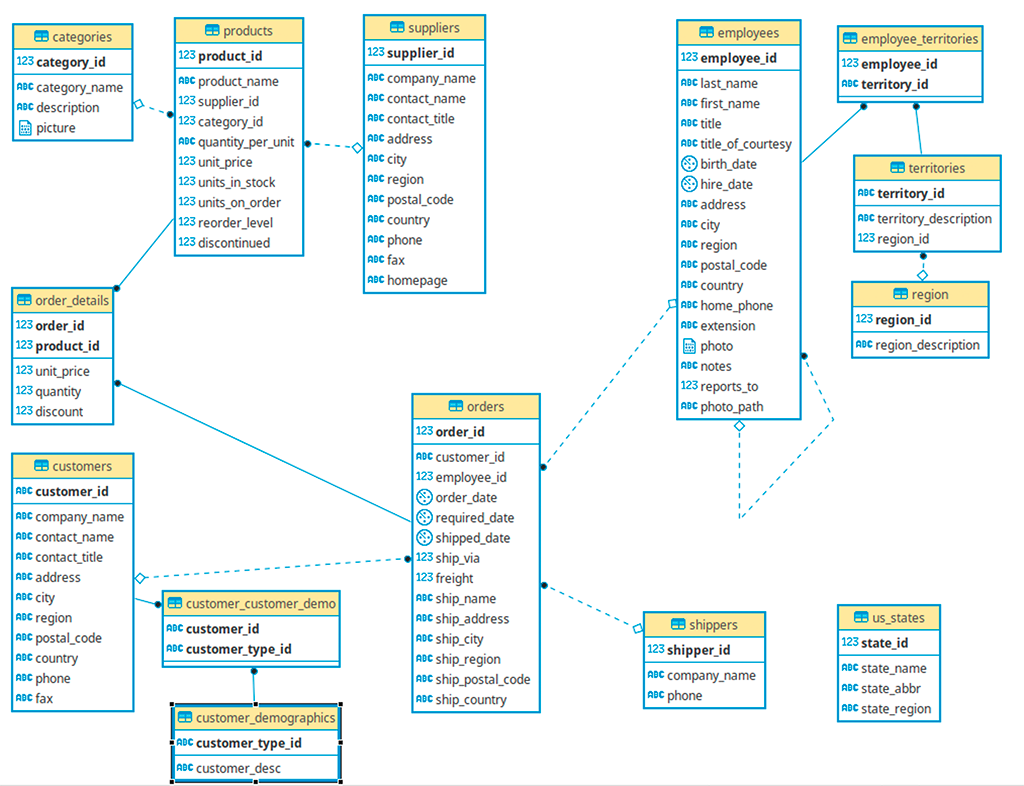
Dans un Data Mesh, les données sont traitées comme des produits. Cela signifie qu’elles doivent être faciles à découvrir, à comprendre, à utiliser, et surtout, fiables. C’est là qu’interviennent les Data Contracts. Ils définissent les attentes et les garanties autour d’un produit de données, un peu comme un contrat entre un fournisseur et un consommateur.
Par la suite, et sous forme de dialogue, il va s’agir de suivre les acteurs afin de comprendre comment est-ce que les équipes métier expriment leurs besoins, et comment les équipes techniques les traduisent en spécifications formelles de Data Products et Data Contracts, en assurant la qualité et l’interopérabilité. La réussite de ce projet selon l’architecture Data Mesh dépendra de la structure, de la bonne organisation de l’équipe produit de données, plus que de choix technologiques.
Distribution des rôles
Notre Data Product Team évolue au sein du Domaine « Ventes et Commandes ». C’est une équipe alignée sur le flux (Stream Aligned Team) ; elle est responsable de la livraison de services de données de bout en bout (ingestion, consommation, découverte, observabilité, etc.) pour un produit de données. Elle possède une portée et des limites claires, un propriétaire responsable et une équipe qualifiée.
Revenons à nouveau sur les rôle de chacun :
- Alice (Métier – Responsable des Ventes) : La cliente principale de notre Data Product. Elle fait partie de ce que l’on pourrait appeler une « Consumer Team » qui accède et utilise les données que nous offrons.
- Bob (Business Analyst / Data Product Owner) : Le « Data Product Owner ». Il est responsable du succès des produits de données du domaine en termes de valeur métier, de satisfaction des utilisateurs et de maintenance du cycle de vie. Il gère la feuille de route du Data Product et la communique.
- Carla (Data Analyst / Consumption Services) : Son rôle est d’aider à la consommation des données et de construire les services nécessaires pour que les utilisateurs comme Alice puissent exploiter le Data Product. Elle a des compétences dans le développement d’interfaces interopérables.
- David (Data Engineer / Ingestion & Data Management) : Il est chargé des « Ingestion Services » (construction et évolution des pipelines pour ingérer les données) et du « Data & Security Management » (gestion, sécurisation et gouvernance des données). Il possède les compétences en pipeline, SQL et ingénierie de données.
- Luc (Data Facilitator (Data Architect)) : Mon rôle est celui d’un consultant de l’équipe « Enabling Team », aidant l’équipe produit à surmonter les obstacles et à adopter les meilleures pratiques, notamment autour des standards comme les Data Contracts.
Scène 1 : L’expression du besoin métier
Luc (Data Facilitator (Data Architect)) : Notre équipe du domaine « Ventes et Commandes » se réunit pour définir les données dont elle a besoin pour ses analyses et rapports.
Alice (Métier) : Bonjour l’équipe. J’ai un problème. Mes rapports de ventes actuels sont compliqués à construire. Je veux savoir, par exemple, combien nous avons vendu de chaque produit, quel employé a réalisé la vente, et à quel client, pour pouvoir analyser la performance et identifier des tendances. Je veux aussi pouvoir segmenter mes analyses par région de livraison. En gros, j’ai besoin d’une vision claire de « qui a vendu quoi à qui, où et quand ».
Bob (Business Analyst / Data Product Owner) : C’est très clair, Alice. Actuellement, nos données de ventes sont dispersées dans différentes tables opérationnelles (commandes, détails de commande, produits, clients, employés). Pour vos besoins analytiques, il faudrait que ces informations soient regroupées et faciles à interroger. Ma mission est de m’assurer que le produit de données que nous construisons réponde à ce besoin de valeur.
Carla (Data Analyst / Consumption Services) : Oui, c’est ce que l’on appelle un « modèle dimensionnel ». On aurait des tables « dimensions » pour les clients, les produits, les employés, les dates, et une table « faits » pour les ventes qui relierait tout ça. Je vais aider à définir la meilleure façon de consommer ces données.
David (Data Engineer / Ingestion & Data Management) : Exactement. Dans une approche Data Mesh, ces regroupements deviendraient nos « Data Products ». Chaque Data Product aurait son propre « Data Contract » pour garantir qu’il répond à vos attentes, Alice. Je serai responsable de l’ingestion des données et de leur gestion au sein de ces produits.
Alice (Métier) : Un contrat de données ? C’est une bonne idée ! Je veux être sûre que les données que j’utilise sont toujours à jour et fiables. Par exemple, si le nom d’un produit change dans la base opérationnelle, je veux que cela se reflète rapidement dans mes rapports. Et surtout, je veux être certaine de ne pas avoir de doublons ou d’erreurs de calcul.
Bob (Business Analyst / Data Product Owner) : Donc, la fiabilité et la fraîcheur sont des exigences clés. Nous allons documenter cela dans le contrat. C’est mon rôle d’assurer la feuille de route du produit et la satisfaction utilisateur.
Scène 2 : Spécifier le Data Product et les Data Contracts (Partie 1 – Dimensions)
Luc (Data Facilitator (Data Architect)) : L’équipe décide de commencer par les dimensions, qui sont les « qui, quoi, où, quand » de l’analyse.
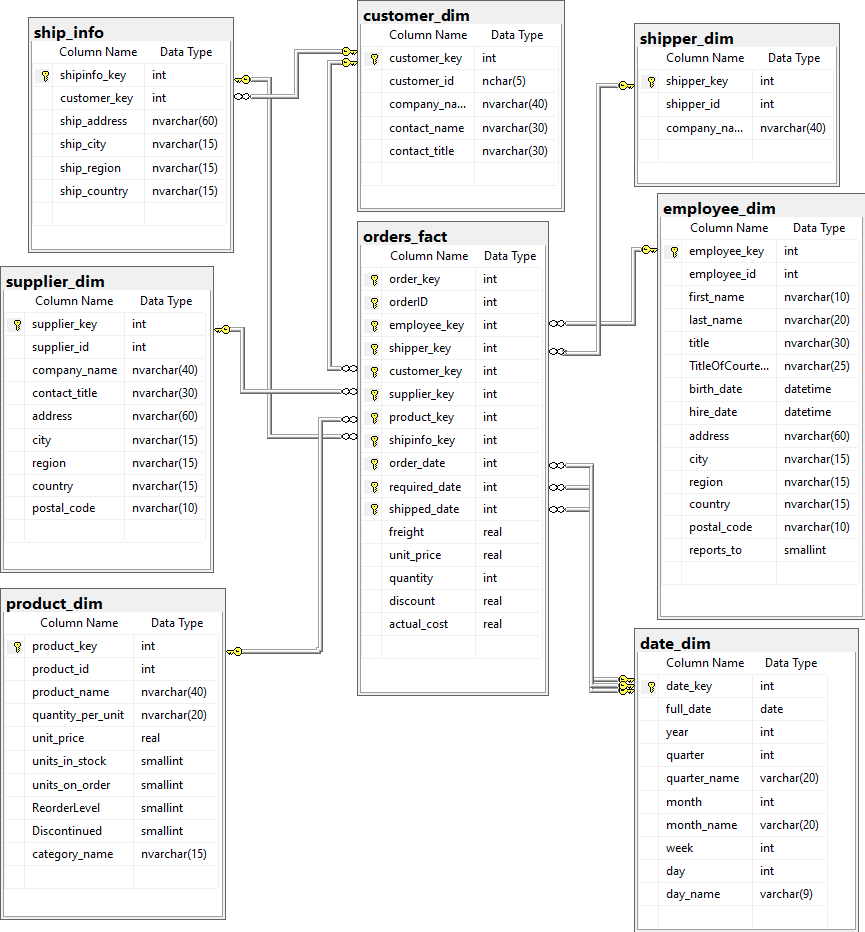
David (Data Engineer / Ingestion & Data Management) : Commençons par la dimension Customer_Dim (Client). Alice, vous voulez les noms de compagnies, les noms des contacts, etc. ?
Alice (Métier) : Oui, le company_name, contact_name et contact_title sont essentiels. Et bien sûr, un identifiant unique pour chaque client.
Carla (Data Analyst / Consumption Services) : L’identifiant opérationnel customer_id est déjà unique. On peut l’utiliser comme clé métier et ajouter une customer_key numérique auto-incrémentée comme clé de substitution ( surrogate key) pour notre dimension.
David (Data Engineer / Ingestion & Data Management) : Parfait. Nous allons spécifier cela dans notre Data Contract pour customer_dim. Je vais utiliser la syntaxe de Data Contract Specification de datacontract.com (Cette spécification est de plus compatible avec Open Data Contract-Standard (ODCS) et Open Data Product Standard (ODPS) de Bitol.io – initiative portée par la Fondation Linux – ces standards sont très similaires dans leur approche pour la structuration des métadonnées et des règles autour des données).
(David projette un écran montrant le YAML)
# customer-dim-contract.yaml
dataContract:
id: "urn:northwind:sales:customer-dim"
version: "1.0.0"
info:
name: "Customer Dimension"
description: "Dimension table for customer information."
owner: "sales_domain_team"
contact: "sales.data.product@northwind.com"
terms:
usage:
description: "Provides core customer attributes for sales analysis. Joinable with orders_fact using customer_key."
schema:
type: "table"
name: "dbo.customer_dim"
description: "Customer dimension."
columns:
- name: "customer_key"
type: "INT"
description: "Surrogate key for customer dimension."
primaryKey: true
unique: true
- name: "customer_id"
type: "NCHAR(10)"
description: "Original customer ID from operational system."
required: true
# Implicit reference to operational model
- name: "company_name"
type: "NVARCHAR(40)"
description: "Name of the customer's company."
required: true
- name: "contact_name"
type: "NVARCHAR(30)"
description: "Full name of the primary contact person."
required: false
- name: "contact_title"
type: "NVARCHAR(30)"
description: "Title of the contact person."
required: false
quality:
- name: "customer_id_uniqueness"
type: "uniqueness"
column: "customer_id"
threshold: 1.0 # 100% unique values
- name: "company_name_completeness"
type: "completeness"
column: "company_name"
threshold: 1.0 # 100% non-null values
# ... other sections like SLA, Observability, etc.Luc (Data Facilitator (Data Architect)) : David explique que id est un identifiant unique pour le contrat, version permet de suivre les évolutions, et info fournit des métadonnées. La section terms contient les règles. usage explique comment utiliser le produit. schema décrit la structure des données, avec les types, descriptions, si la colonne est clé primaire (primaryKey), unique (unique), ou requise (required). quality spécifie les attentes de qualité.
Bob (Business Analyst / Data Product Owner) : Excellent ! Pour la Date_Dim (Date), nous aurions le full_date, year, quarter, month, week, day, etc. Est-ce que cette dimension sera pré-remplie ? C’est crucial pour la planification de la feuille de route.
David (Data Engineer / Ingestion & Data Management) : Oui, la dimension date est généralement pré-remplie sur une longue période, de la première date de commande (1996-07-04) jusqu’à une date future, par un script ou un flux spécial. Son contrat n’aurait pas de source opérationnelle directe, mais un script de génération. C’est une tâche pour les « Ingestion Services ».
(David ajoute la spécification Date_Dim)
Carla (Data Analyst / Consumption Services) : Pour Employee_Dim (Employé), nous aurions l’employee_id, first_name, last_name, title, hire_date, address, city, region, country, et le reports_to pour la hiérarchie.
David (Data Engineer / Ingestion & Data Management) : Tout à fait. Et pour Product_Dim (Produit), on inclura le product_id, product_name, quantity_per_unit, unit_price, et l’indicateur discontinued. Il faudra aussi joindre la table categories pour obtenir le category_name. Et la même logique pour Supplier_Dim et Shipper_Dim.Luc (Data Facilitator (Data Architect)) : Les principes sont les mêmes pour toutes les dimensions : définir le schéma, les règles de qualité (unicité des clés, complétude des champs importants) et les transformations depuis le modèle opérationnel (y compris les jointures nécessaires pour dénormaliser les attributs comme le nom de catégorie pour le produit, ou les adresses d’expédition).
Scène 3 : Spécifier le Data Product et les Data Contracts (Partie 2 – Table de Faits)
Luc (Data Facilitator (Data Architect)) : Une fois les dimensions définies, l’équipe passe à la table de faits, qui contient les mesures numériques des événements.
Alice (Métier) : Pour les ventes, ce qui m’intéresse le plus, ce sont les quantités vendues (quantity), le prix unitaire (unit_price), la remise (discount), et bien sûr, le coût réel calculé (actual_cost).
Bob (Business Analyst / Data Product Owner) : Et toutes ces mesures doivent être associées aux dimensions que nous venons de définir : le client, l’employé, le produit, l’expéditeur, et les dates (commande, requise, expédiée). C’est crucial pour la valeur métier que le produit de données doit délivrer.
David (Data Engineer / Ingestion & Data Management) : C’est le rôle de la table de faits Orders_Fact. Elle aura des clés étrangères vers chaque dimension. De plus, la table opérationnelle Order Details contient la product_id et la order_id ainsi que le unit_price, quantity, et discount. Nous devrons donc joindre Orders et Order Details pour obtenir toutes les informations et ensuite joindre les dimensions pour récupérer les clés de substitution. Tout cela relève de mes responsabilités en matière de services d’ingestion.
(David ajoute la spécification Orders_Fact)
# orders-fact-contract.yaml
dataContractSpecification: 1.1.0
id: "urn:northwind:sales:orders-fact"
info:
title: Orders Fact
version: 1.0.0
owner: "sales_domain_team"
description: "Fact table for sales order details."
contact:
name: Bob (Data Product Owner)
email: bob.dpo@northwind.com
terms:
usage: "Primary table for sales analysis, allowing aggregation by customer, product, employee, shipper, and time dimensions. Measures include quantity, price, discount, and actual cost."
limitations: "Daily batch update, not for real-time order tracking. Calculations are based on transactional data at the time of order."
models:
orders_fact:
type: table
description: "Sales order details at line item granularity."
fields:
order_key:
description: "Surrogate key for each fact record."
type: integer
primaryKey: true
unique: true
quality:
- type: sql
description: "Order key must be unique."
query: "SELECT COUNT(order_key) - COUNT(DISTINCT order_key) FROM {model}"
mustBe: 0
orderID:
description: "Original order ID from operational system."
type: integer
required: true
employee_key:
description: "Foreign key to Employee Dimension."
type: integer
required: true
quality:
- type: sql
description: "Employee key must exist in employee_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN employee_dim AS d ON f.employee_key = d.employee_key WHERE f.employee_key IS NOT NULL AND d.employee_key IS NULL"
mustBe: 0
shipper_key:
description: "Foreign key to Shipper Dimension."
type: integer
required: true
quality:
- type: sql
description: "Shipper key must exist in shipper_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN shipper_dim AS d ON f.shipper_key = d.shipper_key WHERE f.shipper_key IS NOT NULL AND d.shipper_key IS NULL"
mustBe: 0
customer_key:
description: "Foreign key to Customer Dimension."
type: integer
required: true
quality:
- type: sql
description: "Customer key must exist in customer_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN customer_dim AS d ON f.customer_key = d.customer_key WHERE f.customer_key IS NOT NULL AND d.customer_key IS NULL"
mustBe: 0
supplier_key:
description: "Foreign key to Supplier Dimension (derived from product's supplier)."
type: integer
required: true
quality:
- type: sql
description: "Supplier key must exist in supplier_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN supplier_dim AS d ON f.supplier_key = d.supplier_key WHERE f.supplier_key IS NOT NULL AND d.supplier_key IS NULL"
mustBe: 0
product_key:
description: "Foreign key to Product Dimension."
type: integer
required: true
quality:
- type: sql
description: "Product key must exist in product_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN product_dim AS d ON f.product_key = d.product_key WHERE f.product_key IS NOT NULL AND d.product_key IS NULL"
mustBe: 0
shipinfo_key:
description: "Foreign key to Ship Info Dimension."
type: integer
required: true
quality:
- type: sql
description: "Ship Info key must exist in ship_info_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN ship_info AS d ON f.shipinfo_key = d.shipinfo_key WHERE f.shipinfo_key IS NOT NULL AND d.shipinfo_key IS NULL"
mustBe: 0
order_date:
description: "Foreign key to Date Dimension for order date (YYYYMMDD)."
type: integer
required: true
quality:
- type: sql
description: "Order date key must exist in date_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN date_dim AS d ON f.order_date = d.date_key WHERE f.order_date IS NOT NULL AND d.date_key IS NULL"
mustBe: 0
required_date:
description: "Foreign key to Date Dimension for required delivery date (YYYYMMDD)."
type: integer
required: true
quality:
- type: sql
description: "Required date key must exist in date_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN date_dim AS d ON f.required_date = d.date_key WHERE f.required_date IS NOT NULL AND d.date_key IS NULL"
mustBe: 0
shipped_date:
description: "Foreign key to Date Dimension for actual shipped date (YYYYMMDD)."
type: integer
required: true
quality:
- type: sql
description: "Shipped date key must exist in date_dim (referential integrity)."
query: "SELECT COUNT(*) FROM {model} AS f LEFT JOIN date_dim AS d ON f.shipped_date = d.date_key WHERE f.shipped_date IS NOT NULL AND d.date_key IS NULL"
mustBe: 0
freight:
description: "Freight cost for the order."
type: number
required: false
unit_price:
description: "Unit price of the product at the time of order."
type: number
required: true
quantity:
description: "Quantity of the product ordered."
type: integer
required: true
quality:
- type: sql
description: "Quantity must be positive."
query: "SELECT COUNT(*) FROM {model} WHERE quantity <= 0"
mustBe: 0
discount:
description: "Discount applied to the line item."
type: number
required: true
actual_cost:
description: "Calculated actual cost of the order line item (Unit Price * Quantity * (1 - Discount))."
type: number
required: true
quality:
- type: sql
description: "Actual cost calculation must be accurate (within tolerance)."
query: "SELECT COUNT(*) FROM {model} WHERE ABS(actual_cost - (unit_price * quantity * (1 - discount))) > 0.001"
mustBe: 0
servicelevels:
retention:
description: "Orders fact data is retained for 7 years for historical analysis."
period: P7Y
unlimited: false
frequency:
description: "Orders_Fact data is updated daily at 07:00 AM CET, after all dimensions are loaded."
type: batch
cron: "0 7 * * *"
# ... other sectionsCarla (Data Analyst / Consumption Services) : Super ! La clause references dans les colonnes des clés étrangères est très claire. Ça m’assure que je pourrai toujours joindre mes dimensions correctement. Et la règle de qualité calculation_accuracy pour actual_cost est exactement ce qu’il faut pour la fiabilité des chiffres ! C’est ce type de garantie qui facilite la consommation des données.
David (Data Engineer / Ingestion & Data Management) : En effet. La supplier_key dans la table de faits est un bon exemple. Dans le modèle opérationnel, le supplier_id est sur la table products. Nous devrons donc joindre orders, order_details, et products pour récupérer le supplier_id opérationnel, puis faire une recherche sur notre dimension supplier_dim pour obtenir la supplier_key correspondante. C’est ce que j’ai détaillé dans la section logic des transformations. C’est une tâche clé pour mes services d’ingestion.Luc (Data Facilitator (Data Architect)) : Toutes les dimensions (customer_dim, date_dim, employee_dim, product_dim, supplier_dim, shipper_dim, ship_info) et la table de faits (orders_fact) du modèle dimensionnel ont été couvertes. Les clés primaires et uniques, les exigences de non-nullité (required), et les relations de clés étrangères sont spécifiées.
Scène 4 : Le rôle de datacontract-cli et le versionning Git
Luc (Data Facilitator (Data Architect)) : Maintenant que les contrats sont spécifiés, comment les équipes les utilisent-elles et les maintiennent-elles ? Mon rôle, en tant que membre de l’Enabling Team, est d’apporter les outils et les bonnes pratiques.
David (Data Engineer / Ingestion & Data Management) : Une fois nos fichiers YAML de Data Contracts écrits, nous pouvons utiliser l’outil en ligne de commande datacontract-cli.
(David ouvre un terminal)
David (Data Engineer / Ingestion & Data Management) : Je peux valider nos contrats localement pour m’assurer qu’ils respectent le standard :
datacontract test customer-dim-contract.yamldatacontract test orders-fact-contract.yamlSi tout est bon, il me dira Data Contract ‘urn:northwind:sales:customer-dim’ version ‘1.0.0’ is valid.
Carla (Data Analyst / Consumption Services) : Et si je veux voir un aperçu ou générer de la documentation ? C’est utile pour la phase de consommation.
David (Data Engineer / Ingestion & Data Management) : datacontract-cli peut faire ça aussi. Par exemple, pour générer un aperçu lisible :
datacontract lint customer-dim-contract.yaml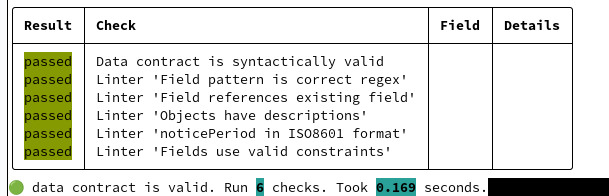
datacontract export --format html customer_dim_contract.yaml --output customer_dim_contract.htmlDepuis le navigateur web on peut parcourir la documentation
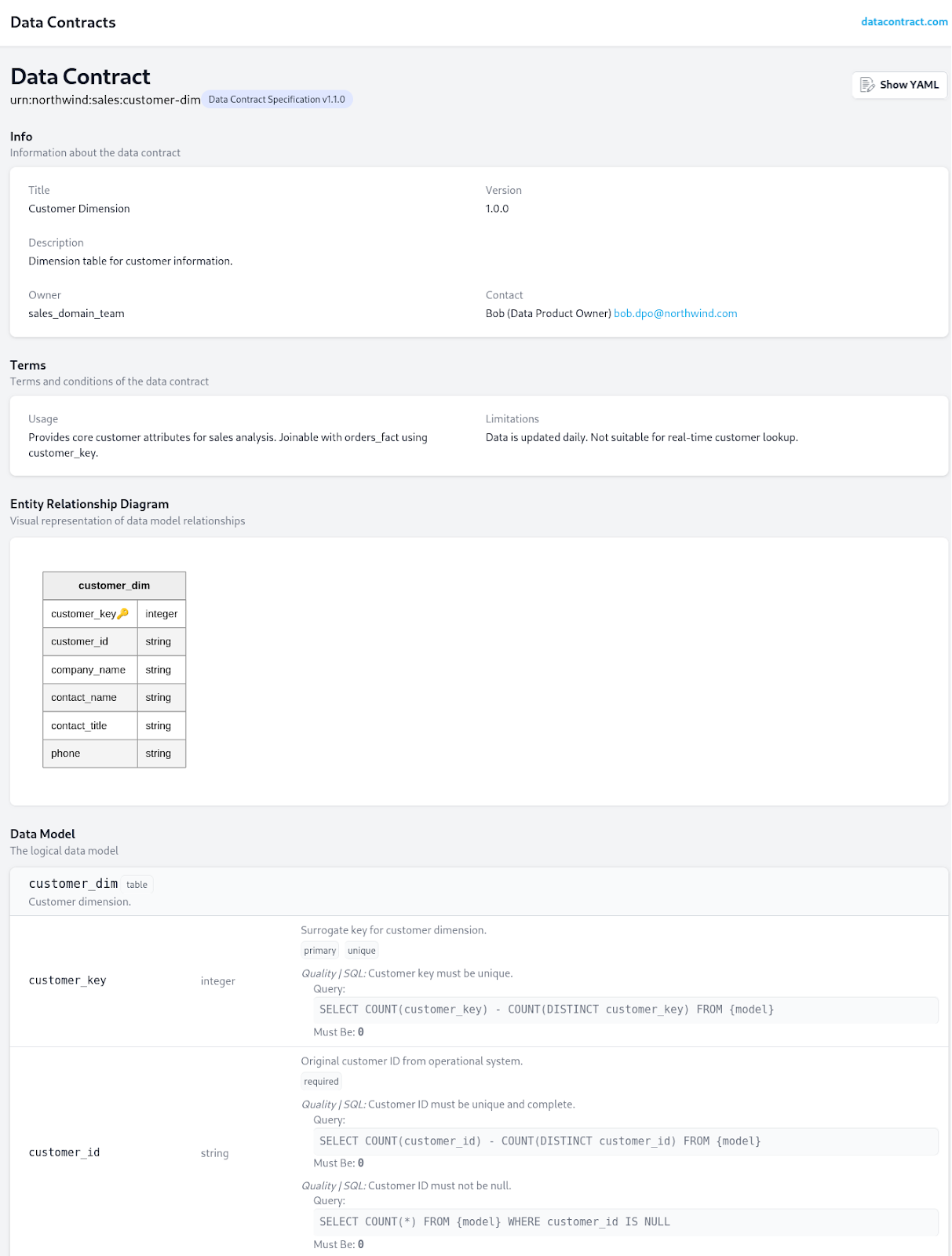
Il peut même générer des schémas SQL pour valider la conformité de nos tables, bien que nous ayons déjà les nôtres dans northwind-datawarehouse.sql.
Bob (Business Analyst / Data Product Owner) : Et le versionnement, comme Alice l’a mentionné ? C’est clé pour la gestion de la feuille de route et la communication des changements.
David (Data Engineer / Ingestion & Data Management) : C’est là que Git entre en jeu. Chaque fichier de contrat (customer-dim-contract.yaml, orders-fact-contract.yaml, etc.) est versionné dans un dépôt Git, idéalement dans le même dépôt que le code qui génère le Data Product. C’est une responsabilité partagée entre « Release Management » et « Ingestion Services ».
David (Data Engineer / Ingestion & Data Management) : Quand nous faisons un changement, par exemple, si nous ajoutons une nouvelle colonne ou modifions une règle de qualité, nous mettons à jour le fichier YAML.
(David modifie un contrat pour l’exemple)David (Data Engineer / Ingestion & Data Management) : Supposons qu’Alice veuille maintenant suivre le phone du client. Je vais ajouter la colonne à customer_dim:
# customer-dim-contract.yaml (modifié)
# ... (début du fichier)
columns:
# ... (colonnes existantes)
- name: "phone" # Nouvelle colonne
type: "NVARCHAR(24)"
description: "Phone number of the customer."
required: false
# ... (fin du fichier)David (Data Engineer / Ingestion & Data Management) : Après cette modification, je devrais incrémenter la version du contrat dans le YAML, par exemple de 1.0.0 à 1.1.0.
dataContractSpecification: 1.1.0
id: "urn:northwind:sales:customer-dim"
info:
title: Customer Dimension
version: 1.1.0
owner: "sales_domain_team"
# ... le reste du contratDavid (Data Engineer / Ingestion & Data Management) : Ensuite, je valide les changements, les pousse sur Git, et ça déclenche une revue de code et potentiellement une mise à jour de nos pipelines ETL/ELT. Chaque version du contrat correspond à une version du code et du schéma du Data Product. Cela garantit que tout consommateur qui utilisera dès la mise en production la version 1.1.0 saura exactement à quoi s’attendre, et les changements intervenus par rapport à la version 1.0.0.
Alice (Métier) : C’est génial ! Donc, si j’utilise la version 1.0.0 avec un rapport, et dans le cadre de nos discussions régulières je saurai que la version 1.1.0 qui arrive va corriger telle ou telle règle. Je demanderai ainsi à mettre à jour les rapports dépendants afin que les livraisons du modèle, des flux et des rapports soient concomitants. C’est très clair.
Scène 5 : Intérêt des standards et interopérabilité
Luc (Data Facilitator (Data Architect)) : Pour conclure, explorons les perspectives offertes par ces standards, notamment en termes d’interopérabilité. Mon rôle est aussi d’aider à la gouvernance d’entreprise et à l’architecture.
Bob (Business Analyst / Data Product Owner) : David, pourquoi est-ce si important d’utiliser des standards comme Data Contract Specification de datacontract.com ou ceux Bitol.io, au lieu de juste documenter nos tables ?
David (Data Engineer / Ingestion & Data Management) : C’est une excellente question, Bob. L’utilisation de ces standards apporte plusieurs avantages clés :
- Expressivité Formelle et Machine-Lisible : Premièrement, ils nous fournissent un langage formel (YAML) pour décrire précisément les spécifications. Ce n’est pas juste du texte libre. Ce format est lisible par les humains, mais surtout, il est lisible et interprétable par les machines. Cela signifie que des outils peuvent automatiser la validation du schéma, la surveillance de la qualité, et même la génération de documentation ou de code.
- Automatisation et Gouvernance : Puisque les contrats sont machine-lisibles, nous pouvons automatiser la gouvernance des données. Par exemple, à chaque déploiement de notre Data Product, notre pipeline peut automatiquement vérifier que le schéma de la table en production correspond bien à ce qui est défini dans le contrat. Si ce n’est pas le cas, le déploiement peut être bloqué. Cela réduit considérablement les erreurs et la dette technique. La gestion des données et la sécurité sont au cœur de mes responsabilités.
- Clarté et Confiance : Pour les équipes consommatrices (comme Alice), le Data Contract est une source unique de vérité et une garantie. Elles savent exactement à quoi s’attendre en termes de structure, de sémantique, et de qualité. Cela bâtit la confiance dans le produit de données et encourage son adoption.
- Interoperabilité et Évolutivité : C’est le point majeur dans une architecture Data Mesh ou un environnement polyglotte (Data Warehouse, Data Lakehouse, Data Marts). Imaginez que nous ayons plusieurs domaines de données. Si chaque domaine expose ses Data Products avec des Data Contracts standardisés, n’importe quelle autre équipe (ou même un outil externe) peut comprendre et consommer ces données sans avoir à demander des explications spécifiques à chaque fois.
- Passer d’un Data Warehouse à l’autre : Si nous décidons de migrer de PostgreSQL vers Snowflake pour notre Data Warehouse, les Data Contracts restent les mêmes. Seule l’implémentation derrière (le code ETL/ELT) change. Les consommateurs n’ont pas besoin de s’adapter si le contrat est maintenu.
- Vers un Data Lakehouse : Si une autre équipe veut utiliser nos données de vente pour un modèle de Machine Learning dans un Data Lakehouse, elle n’a qu’à se référer au Data Contract. Le contrat lui dit tout ce qu’elle doit savoir pour ingérer et utiliser ces données, indépendamment de la technologie sous-jacente. Cela facilite grandement le partage et la réutilisation des données à travers l’organisation.
- Découverte et Partage : Les Data Contracts peuvent être publiés dans un catalogue de données centralisé, rendant les Data Products découvrables et transparents pour toute l’organisation. C’est la fondation de l’interopérabilité à grande échelle.
Alice (Métier) : Je vois ! C’est comme une API standardisée pour les données. Cela rend les données de notre domaine de ventes beaucoup plus accessibles et fiables pour d’autres équipes, même si elles ne connaissent pas tous les détails techniques de notre système.
Carla (Data Analyst / Consumption Services) : Et pour moi, en tant que Data Analyst, ça simplifie énormément mon travail. Moins de temps à comprendre des schémas ad-hoc ou à corriger des erreurs de données imprévues. Je peux me concentrer sur l’analyse de la valeur.
David (Data Engineer / Ingestion & Data Management) : Exactement. Les Data Contracts sont la pierre angulaire de produits de données autonomes, interopérables et fiables, permettant à une organisation de véritablement devenir « data-driven ». Ils formalisent la collaboration entre producteurs et consommateurs de données.Luc (Data Facilitator (Data Architect)) : Et voilà ! De l’expression du besoin métier à la spécification technique et aux avantages de l’interopérabilité, vous avez maintenant une vision complète des Data Contracts et Data Products dans un contexte Data Mesh, illustrée par nos amis de Northwind. Merci de nous avoir suivis !
Making-Off
De la fiction à la réalité… Beaucoup de nos clients, nous demande comment est-ce qu’un projet se passe, comment d’autres clients mettent place leur projet ? Ce dialogue doit pour tout un chacun être instructif. Une équipe certes avertie, avec une culture de la données établie qui sait de quoi elle parle : Data Mesh, Data Product, Data Contract. Chaque membre de l’équipe dans un dialogue constructif, apporte sa pierre l’édifice, échange : les connaissances de chacune élèvent l’autre. Pourquoi, standardise-t-on des spécifications pour traiter de la donnée ? Parce que le sujet s’est tellement répandu qu’il est important que les organisations ne réinvente pas de pareilles choses. Il faut former les équipes à ce type de standards. En plus, la documentation à l’ancienne dans le document Word, Excel présentent des limites (il faut en extraire le contenu pour les machines…). Dans le cadre de cet article nous nous sommes appuyés sur Open Data Product Standard (ODPS), Open Data Contract Standard (ODCS), Data Contract Specification. Toutefois, il faut bien noter que des solutions telle que Datamesh-Manager ou Blindata qui vous aidera dans l’élaboration de vos projets avec une vision Data Mesh.
Pour aller plus loin
- Data Mesh Architecture – https://www.datamesh-architecture.com/
- Bitol Initiative Fondation Linux : https://bitol.io
- Data Contract Specification – https://datacontract.com
- Data Product Descriptor Specification – https://dpds.opendatamesh.org/
