

Nous ne comptons plus les solutions pour orchestrer des tâches. Si Apache Airflow a démarré autour de 2015, de nombreuses solutions nées après, proposent toutes de corriger toutes ses imperfections.
Tout d’abord il faut bien noter que Apache Airflow® est née dans l’idée de gérer et faciliter la planification de flux de données. Ce point est très important pour le comparer à tous ces concurrents. Il convient dès lors d’avoir en tête les cas d’usage pour lesquels l’employer et en tirer de réels bénéfices et au contraire savoir quand il ne faut pas l’utiliser.
Nous reviendrons plus tard en détail sur la notion de “Backfill”, “Ré-exécution” ou “Ré-alimentation”. Listons d’abord quand il faut employer Apache Airflow et quand il ne faut pas l’employer. Et gardons en tête que ces cas d’usage sont liés au concept de ré-alimentation.
Quand utiliser Apache Airflow®
Apache Airflow® est très utile pour les cas d’usage suivant :
- Migration des données, alimentation de data warehouse, data lake, data lakehouse depuis des données issues de systèmes opérationnels ; par exemple l’alimentation de plate-forme de données basée sur le cloud telle que Dremio, Databricks, Snowflake, Redshift, BigQuery, Synapse pour une transformation ultérieure ;
- Gérer des pipelines d’apprentissage automatique de bout en bout ;
- Intégration de données via des pipelines ETL/ELT avec Talend, DBT (extrait-transform-load/extrait-load-transform) complexes ;
- Génération de rapports automatisée ;
- Tâches DevOps : par exemple, créer des sauvegardes planifiées et restaurer les données à partir de celles-ci.
Il faut bien avoir en tête que Airflow n’est pas un planificateur “généraliste” ! Airflow doit servir à orchestrer des flux de données. Comme tout autre outil, il n’est pas omnipotent et présente de nombreuses limites.
Quand ne pas utiliser Apache Airflow®
Airflow n’est pas un outil de traitement de données en tant que tel mais plutôt un instrument permettant de gérer plusieurs composants du traitement de données. Il n’est pas non plus destiné aux traitement de données en continu (streaming).
Cependant, la plate-forme est compatible avec les solutions prenant en charge l’analyse en temps quasi réel et en temps réel, telles qu’Apache Kafka, Apache Spark ou des solutions de traitement temps réel plus récentes RizingWave, Materialize. Dans des pipelines complexes, les plateformes de streaming peuvent ingérer et traiter des données en direct provenant de diverses sources, les stockant dans un référentiel tandis qu’Airflow déclenche périodiquement des flux de travail qui transforment et chargent les données par lots.
Une autre limitation d’Airflow est qu’il nécessite des compétences en programmation. Il s’en tient à la philosophie du “pipeline as code”, ce qui rend la plate-forme inadaptée aux non-développeurs.
Backfilling / Ré-Exécution / Ré-Alimentation
Tout ingénieur de données doit disposer d’une procédure de ré-alimentation de données au cas où les données doivent être mises à jour en masse.
La ré-alimentation des données est le processus consistant à remplir les données manquantes du passé sur un nouveau système qui n’existait pas auparavant, ou à remplacer les anciens enregistrements par de nouveaux enregistrements suite à une mise à jour.
La ré-alimentation des données se produit généralement après qu’une anomalie de données ou un incident de qualité des données qui a entraîné la diffusion de mauvaises données dans l’entrepôt de données, dans le data lake ou le data lakehouse.
Il vaut donc mieux préparer ces flux, sa modélisation de données, ces pipelines le cas échéant. Par ailleurs, vous pouvez aussi vous référer au modèle pour la gestion des erreurs de Ralph Kimball 😉
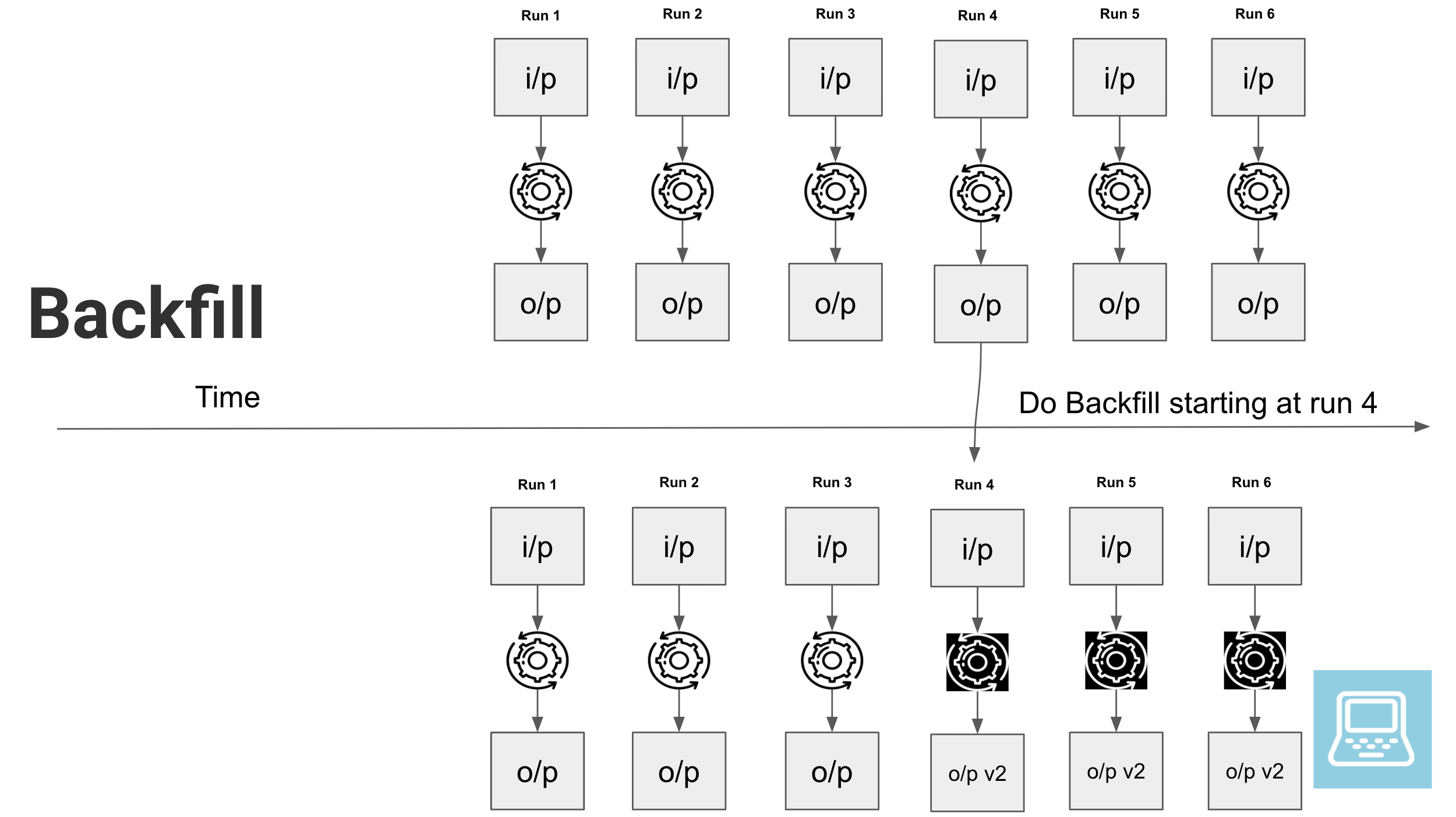
source de l’illustration: https://www.startdataengineering.com/images/backfill-sql-airflow/backfill.png
La ré-alimentation intervient dans les cas suivants :
- Vous devez appliquer une modification à certaines logiques métier à un ensemble de données déjà traité.
- Vous vous rendez peut-être compte qu’il y a une erreur dans votre logique de traitement et souhaitez corriger les données déjà traitées.
- Vous souhaiterez peut-être ajouter une colonne supplémentaire et la remplir avec une certaine valeur dans un ensemble de données existant. La plupart des frameworks d’orchestration ETL prennent en charge la ré-alimentation.
Ce concept est lui aussi au cœur d’Apache Airflow ! Il convient de concevoir ces traitements avec la possibilité d’une part de les repenser le cas échéant, de ré-alimenter vos tables, mais aussi aussi pour ne développer qu’un traitement qui sait à la fois charger l’historique (et être exécuté sur les données du passé) et à la fois charger les données dans le cadre des exécution régulières. C’est un gain de temps pour le développement et pour la maintenance.
Airflow, Aujourd’hui
La toute dernière version de Apache Airflow, 2.8.0 est sortie le 15 décembre 2023. Elle sort après le Summit de septembre. Il est sans doute temps de vous mettre à jour
What Everybody Ought to Know About Airflow
Cette session vous retrace les évolutions et les dernières avancées d’Apache Airflow, très utile pour vous lancer en 2024 avec cette solution d’orchestration.
Future of the Airflow UI
Un retour sur les évolutions de l’interface graphique d’Apache Airflow
Micropipelines: A microservice approach for DAG authoring using datasets
Un conseil, rester simple ! La construction de flux de traitement doit rester simple. Vous devez penser à la maintenance future que vous même ou que vos collègues auront à faire. Ne complexifiez pas vos traitements ! Peut-être que les Micropiplines sont une solution.
Airflow at Bloomberg: Leveraging dynamic DAGs for data ingestion
Les pipelines de traitement sont souvent les mêmes ! Sans doute que des modèles peuvent être salvateurs et productifs !
(Apache Airflow®) Deferrable Operators
Bien qu’Airflow soit capable d’exécuter des tâches sur ses workers (mais Airflow n’est pas le moteur de calcul), il sert principalement de planificateur pour gérer les flux de travail. Dans de nombreux cas, le gros du travail lié à l’exécution de tâches massives est confié à des systèmes externes (Docker, Kubernetes, Spark, Trino, Athena, Snowflake, Dremio…). Les tâches Airflow impliquent souvent de vérifier l’état du traitement sur ces systèmes externes et d’attendre les résultats.
Pour optimiser l’utilisation des ressources et minimiser les opérateurs ou les capteurs inactifs, Airflow a introduit un composant principal appelé Triggerer. Le déclencheur permet d’effectuer des contrôles légers au lieu d’exécuter la tâche ou le capteur en continu sur un worker et d’occuper un emplacement (pool). Au lieu de cela, ces tâches peuvent s’interrompre lorsqu’elles savent qu’elles doivent attendre et déléguer la responsabilité de leur reprise à un déclencheur.
Les déclencheurs sont de petits morceaux de code Python asynchrones conçus pour être exécutés ensemble dans un seul processus Python. Leur nature asynchrone leur permet de coexister efficacement. Voici un aperçu du fonctionnement de ce processus :
- Report de tâche : lorsqu’une instance de tâche atteint un point où elle doit attendre, elle se reporte à l’aide d’un déclencheur associé à l’événement qui devrait la reprendre. En différé, le worker est libéré pour exécuter d’autres tâches.
- Enregistrement et exécution : la nouvelle instance de déclencheur est enregistrée dans Airflow et récupérée par un processus de déclenchement, qui est responsable de la gestion des déclencheurs.
- Exécution du déclencheur : le processus déclencheur exécute le déclencheur jusqu’à ce qu’il atteigne la condition de déclenchement spécifiée. Une fois le déclencheur déclenché, il déclenche la re-planification de la tâche source associée.
- Reprise de la tâche : le planificateur ajoute ensuite la tâche à la file d’attente à exécuter sur un nœud de travail, garantissant ainsi que son exécution reprend lorsque les ressources sont disponibles.

Pour en savoir plus sur les Deferrable Operators, nous vous invitons à regarder cette vidéo. Il s’agit de la présentation de Syed Hussain réalisée lors de l’Airflow Summit d’octobre 2023 : « Deep dive into how AWS is developing Deferrable Operators for the Amazon Provider Package to help users realize the potential cost-savings provided by Deferrable Operators, and promote their usage. »
Introducing airflowctl: A CLI to streamline getting started with Airflow
Les nouveaux utilisateurs débutant avec Airflow sont fréquemment confrontés à plusieurs défis, allant de la complexité des conteneurs et des environnements virtuels à l’enfer des dépendances Python. De plus, leur familiarité avec des outils tels que Docker, docker-compose et Helm peut être quelque peu limitée, voire excessivement limitée. En revanche, les utilisateurs chevronnés d’Airflow rencontrent leurs problèmes, englobant des conflits de configuration avec les projets Airflow en cours et des subtilités provenant des configurations Docker et docker-compose et le manque de visibilité sur tous les projets.
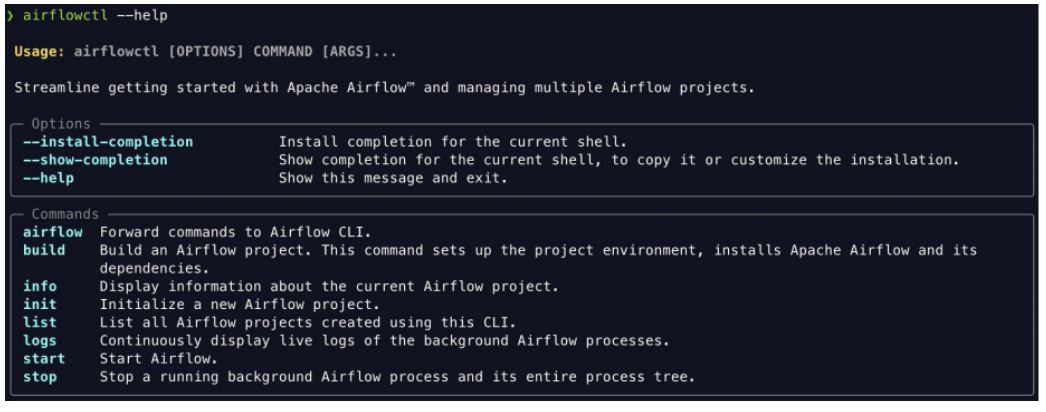
Avec airflowctl, les utilisateurs peuvent installer et configurer Airflow à l’aide d’une seule commande. Les utilisateurs existants peuvent l’utiliser pour gérer plusieurs projets Airflow avec différentes versions d’Airflow sur la même machine. Cela permet de créer et de déboguer des DAG dans un IDE de manière transparente.
