
Dans cet article, Charly Clairmont vous présente quelques subtilités d’Apache Kafka, outil open source de système de messagerie distribué, originellement développé chez LinkedIn. Attention les « non-techs », passez votre chemin, dans ce post, ça parle broker, mémoire, partition, flux et autres joyeusetés ! Les autres, amusez-vous bien !
Apache Kafka comme système de messagerie
Comment la notion de flux de Apache Kafka se compare-t-elle à un système traditionnel de messagerie d’entreprise?
La messagerie a traditionnellement deux modèles:
- la mise en file d’attente
et
- publish-subscribe (la publication / souscription)
Dans une file d’attente, un groupe de consommateurs peut lire à partir d’un serveur et chaque enregistrement va à l’un d’eux. Dans le publish-subscribe l’enregistrement est diffusé à tous les consommateurs. Chacun de ces deux modèles a une force et une faiblesse. La force de la file d’attente est qu’elle permet de diviser le traitement des données sur plusieurs instances de consommateur, ce qui vous permet d’échelonner votre traitement. Malheureusement, les files d’attente ne sont pas multi-abonné – une fois qu’un processus lit les données, elles ne sont alors plus disponibles. Le publish-subscribe, lui, permet de diffuser des données vers plusieurs processus, mais n’a aucun moyen de mettre à l’échelle le traitement dès que chaque message est envoyé à chaque abonné.
Le concept de groupe de consommateurs dans Apache Kafka généralise ces deux concepts. Comme avec une file d’attente, le groupe de consommateurs permet de diviser le traitement sur une collection de processus (les membres du groupe de consommateurs). Comme avec publish-subscribe, Apache Kafka permet de diffuser des messages à plusieurs groupes de consommateurs.

L’avantage du modèle d’Apache Kafka est que chaque « topic » a ces deux propriétés : il sait passer à l’échelle et à la fois être multi-souscripteur. Il n’est pas nécessaire de choisir l’un ou l’autre.
Apache Kafka a donc l’avantage de garantir l’ordre des messages plus fortement qu’un système de messagerie traditionnel.
Une file d’attente traditionnelle conserve les enregistrements en ordre sur le serveur et si plusieurs consommateurs consomment de la file d’attente, le serveur transmet les enregistrements dans l’ordre dans lequel ils sont stockés. Cependant, bien que le serveur distribue les enregistrements dans l’ordre, les enregistrements sont distribués de façon asynchrone aux consommateurs, de sorte qu’ils peuvent arriver dé-ordonnés sur différents consommateurs. Cela signifie effectivement que l’ordre des enregistrements est perdue en présence d’une consommation parallèle. Les systèmes de messagerie travaillent souvent autour de cela en ayant une notion de «consommateur exclusif» qui permet à un seul processus de consommer à partir d’une file d’attente, ce qui malheureusement signifie qu’il n’y a pas de parallélisme dans le traitement.
Apache Kafka le fait mieux. En ayant une notion de parallélisme – la partition – au sein des « topics« , Apache Kafka est capable de fournir à la fois des garanties sur l’ordre et l’équilibrage de charge sur un pool de processus de consommation. Cela est réalisé en assignant les partitions du « topic » aux consommateurs d’un groupe de consommateurs afin que chaque partition soit consommée par exactement un consommateur dans le groupe.
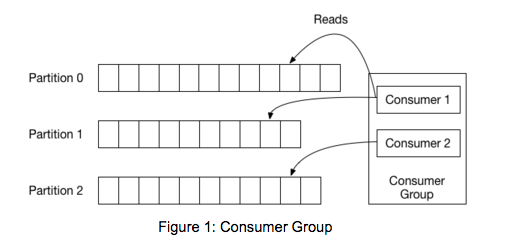
En faisant cela, Apache Kafka s’assure que le consommateur est le seul lecteur de cette partition et consomme les données dans l’ordre. Étant donné qu’il existe de nombreuses partitions, cela équilibre encore la charge sur de nombreuses instances de consommateur. Notez cependant qu’il ne peut y avoir plus d’instances de consommateurs dans un groupe de consommateurs que les partitions.
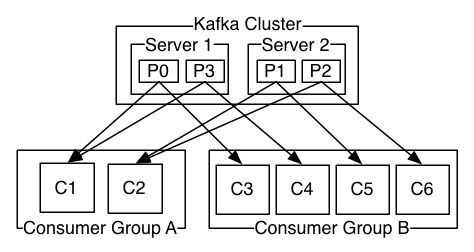
Le parallélisme et donc la performance de Apache Kafka est lié à ce nombre de partitions qui permet d’avoir plus de producteurs, plus de consommateurs. L’interrogation qui nous vient alors est de savoir désormais combien pouvons nous avoir de partition à même un seul nœud (ou broker), est-ce que l’on peut avoir un plus grand nombre de consommateurs que l’on a de partitions ?
Combien de partitions sur un même broker ?
Apache Kafka Consumer
Le consommateur d’Apache Kafka est très efficace. Il fonctionne en extrayant des morceaux de message directement depuis le système de fichiers. Il utilise l’API sendfile pour transférer ces blocs de données directement à travers le système d’exploitation sans le surcharger d’un descripteur de fichier vers un autre (autrement dit, une copie de données quasi indolore et extrêmement rapide). Le consommateur lit presque exclusivement le pagecache du système d’exploitation, car il lit des données qui viennent d’être écrites par un producteur (il est toujours mis en cache). Si l’on utilisait des outils pour mesurer les entrées / sorties sur un serveur de production, on verrait effectivement qu’il n’y a aucune lecture physique, même si une grande quantité de données est consommée.
Rendre les consommateurs si efficace est très important pour permettre à Apache Kafka de l’être tout autant. Son mécanisme de réplication est lui-même basé sur des consommateurs : rendre le consommateur efficient rend la réplication efficiente.
Confluent a bien détaillé le sujet pour aider à mieux comprendre comment bien choisir son nombre de partitions :
How to choose the number of topics/partitions in a Kafka cluster?
Confluent – Jun Rao
Mars 2015
La conclusion de cet article est assez claire : avoir un plus grand nombre de partitions augmente les performances car on obtient un débit plus élevé. Cependant, il faut avoir à l’esprit qu’un trop grand nombre de partitions au total ou un trop grand nombre de partitions par broker (serveur) a aussi des conséquences sur la disponibilité et la latence elle même.
L’inconvénient du trop grande nombre de partitions par serveur entraîne un grand nombre de fichiers ouverts sous Linux. On risque d’atteindre la limite et faire face à des exceptions : « java.io.IOException: Too many open files ». Si bien qu’il faille bien penser à modifier la quantité de fichiers ouverts en même temps comme lors de l’installation d’Oracle, Hadoop… et consort (ulimit – n xxxxx).
Chez LinkedIn, certains des topics à fort volume sont configurés avec plus d’une partition par broker. Le fait d’avoir plus de partitions augmente le parallélisme E / S : tant pour producteurs (comme nous l’avons déjà vu) que pour les consommateurs (puisque la partition est l’unité de distribution des données aux consommateurs). Il faut donc bien garder à l’esprit que plus de partitions ajoute de nouvelles contraintes (vu au paragraphe précédent) :
- (a) il y aura plus Fichiers et donc plus de gestionnaires de fichiers ouverts;
- (b) il y a plus de vérifications par les consommateurs qui peuvent augmenter la charge de / pour ZooKeeper.

Donc c’est un équilibre à trouver entre la performance que l’on attend et la latence que l’on est prêt à concéder si l’on a un trop grand nombre de partition.
On peut aussi prendre le problème dans l’autre sens maintenant et se demander ce qu’il se passe s’il l’on a trop de consommateurs pour peu de partitions.
Rappelons que :
- Si toutes les instances de consommateur font partie du même groupe de consommateurs, cela fonctionne exactement comme une file d’attente traditionnelle équilibrant la charge sur les consommateurs.
- Si toutes les instances de consommateurs sont de groupes de consommateurs différents, cela fonctionne comme publish-subscribe et tous les messages sont diffusés à tous les consommateurs.
Ainsi, plus vous avez de groupes d’abonnés, plus la performance est faible, car Apache Kafka a besoin de répliquer les messages à tous ces groupes et de garantir l’ordre total. On peut voir ça sous un autre angle moins on a de groupes, et plus on a de partitions, plus on va gagner en parallélisme pour traiter des messages. A l’inverse il ne peut y avoir plus d’instances de consommateurs dans un seul groupe de consommateurs que de partitions !
Et la mémoire dans tout ça ?
Les brokers devront allouer un tampon de la taille de replica.fetch.max.bytes pour chaque partition qu’ils répliquent. Donc, si replica.fetch.max.bytes = 1 Mo et vous avez 1000 partitions (sur de nombreux brokers), cela prendra environ 1 Go de RAM. Effectuez les calculs et assurez-vous que le nombre de partitions multipliées par la taille du plus grand message ne dépasse pas la mémoire disponible. Idem pour les consommateurs et fetch.message.max.bytes – assurez-vous qu’il y a suffisamment de mémoire pour le plus grand message pour chaque partition que le consommateur réplique. Cela peut signifier que vous vous retrouvez avec moins de partitions si vous avez des messages importants, ou vous pouvez avoir besoin de serveurs avec plus de RAM.
Pour plus de détails, je vous recommande la lecture de cet article (en anglais) de Gwen Shapira.
Charly Clairmont
PS : J’avais écrit cet article il y a quelques temps déjà… Mais je pense qu’il trouvera son utilité encore aujourd’hui !

Sections commentaires non disponible.