

Cycle de vie, chaîne de traitement et chaîne de valeur de la donnée : Quésaco ? ; un article proposé par Galla Topalian !
Cycle de vie, chaîne de traitement et chaîne de valeur de la donnée : Quésaco ?
Un regard fonctionnel sur la donnée…
La culture de la donnée est dotée de son propre vocabulaire. Le définir, c’est commencer à appréhender la richesse et la diversité des métiers impliqués dans l’exploitation, le traitement et l’administration de ses données. En quelques lignes, focus sur ces trois expressions :
1. La chaîne de valeur de la donnée

Freepik
La chaîne de valeur de la donnée décrit toutes les étapes qui permettent d’identifier, recueillir, stocker, transformer, enrichir, exploiter et diffuser les données afin de les rendre exploitables. Dans cette perspective, c’est la génération de valeur – et donc l’usage de la donnée – qui est mise en avant.
L’objectif de valeur est le cap fondamental de tout projet data. La chaîne de valeur est donc d’abord et avant tout guidée par une vision fonctionnelle de la donnée, de son sens, de sa valeur – sa capacité à résoudre un problème, répondre à une question, générer des opportunités, confirmer ou donner une direction.
A qui s’adresse la chaîne de valeur de la donnée ?
La chaîne de valeur doit donc être comprise et intégrée par les métiers de l’organisation. Il s’agit d’une vision à but fondamentalement fonctionnel et permet de décrire le sens, la signification des étapes de transformation de la donnée, tout autant que ses usages finaux.
Quels sont les outils de gestion de la chaîne de valeur ?
- cartographie des données
- catalogue de données et de métadonnées
- cartographie des processus métier en relation avec la donnée
- cartographie des traitements en relation avec la donnée
Qui sont les acteurs de la chaîne de valeur ?
- Utilisateurs Métier
- Le garant de la qualité des données : Data Steward
- L’analyse des données : Data Analyst
- Data Scientist
- Data Facilitateur (Livre blanc Data Facilitateur)
- Chief Data Officer
- Data Product Owner
- Data Protection Officer
2. La chaîne de traitement de la donnée
Cette acception décrit une dimension plus technique, outillant la chaîne de valeur. On peut se représenter cette chaîne comme une véritable ligne de production en usine. Les données sont en quelque sorte les matières premières de cette chaîne, tandis que les machines sont les traitements appliqués. Pour résumer, l’objectif de cette chaîne est de délivrer des données parfaitement préparées, prêtes à la consommation. Par conséquent, son efficacité repose sur plusieurs paramètres :
- automatisation
- surveillance
- maintenabilité
- évolutivité

Freepik
Les paramètres :
L’automatisation d’abord, car les flux de données générés et utilisés par les organisations ne permettent plus un traitement manuel, au cas par cas. Après une phase de test et de validation sur des échantillons, les processus doivent être capables de reproduire les traitements en production, c’est-à-dire de façon continue sur toutes les nouvelles données arrivant dans le système. Par conséquent, la résistance à la panne, la scalabilité et la haute disponibilité sont autant de qualités nécessaires au bon fonctionnement de la chaîne.
La surveillance, car toute machine, tout processus doit pouvoir être corrigé ou amélioré. Que la panne soit matérielle (un serveur en panne) ou fonctionnelle (des données inattendues et non exploitables), le système doit être capable de sonner l’alerte pour mener à une réparation ou une évolution. Ce sont les questions adressées par le monitoring. Le monitoring est couplé à une question convexe, celle de la capacité à tester l’ensemble de la chaîne pour valider son bon fonctionnement. Le déploiement automatique de test et l’audit de la chaîne de traitement garantissent sa qualité et son bon fonctionnement.
La maintenabilité, car la chaîne de traitement doit être capable de durer dans le temps. Comme dans une ligne de production, les outils doivent en effet, être suffisamment découplés et intégrés pour pouvoir être changés – comprendre mis à jour ou dépanné – sans impacter l’ensemble de la chaîne.
L’évolutivité : la chaîne de traitement doit trouver un équilibre entre la robustesse de son système et sa capacité à évoluer. Qu’il s’agisse de nouveaux besoins fonctionnels, d’une évolution des données ou d’un changement d’infrastructure, les évolutions doivent pouvoir être développées, intégrées et déployées dans cette chaîne sans compromettre son usage, dans une approche fondamentalement agile.
L’ensemble de ces bonnes pratiques garantissant le fonctionnement de la chaîne de traitement est identifié par la méthodologie dataOps.
Elle permet en effet, de mêler les problématiques de développement – ce que font les machines – et celles d’infrastructure – l’organisation et la maintenance de la ligne opérationnelle.
A qui s’adresse la chaîne de traitement de la donnée ?
Fondamentalement, cette chaîne n’est qu’un outil au service de la valeur !
Quels sont les outils de la chaîne de traitement ?
- ETL et orchestrateur
- Monitoring (ELK)
- Alerting
- Versionnement (GIT)
- Déploiement (CI/CD)
- Industrialisation (containerisation)
3. Le cycle de vie de la donnée
Cette vision traduit une approche plus administrative, quasi-documentaire de la donnée, orientée ressource. Physiquement, une donnée, qu’est-ce que c’est ? Le passage dans le cloud a pu augmenter la sensation d’immatérialité conférée de longue date à la donnée. Objet malléable, duplicable, évolutif, la donnée n’en demeure pas moins un artefact physique qui a un poids, des étiquettes, un prix de stockage, des conditions d’utilisation, des usages. En d’autres termes, tous ces aspects doivent être gérés au-delà des chaînes de valeur et de traitement.

Freepik
Trajectoire d’une donnée : un exemple
Comme nous l’avons dit précédemment, la donnée “naît”, la donnée “vit”, et un jour… la donnée “meurt”. Entre-temps, elle a subi de nombreuses modifications, peut avoir été “consommée” par de nombreuses applications pour des usages très variés.
Par exemple, prenons le cas d’une fiche client dans un grand groupe de distribution.
Générée ou acquise manuellement par les “métiers” ou des acteurs externes dans une base de données opérationnelle – ici le CRM – elle a un usage propre à cette étape – par exemple, permettre de cumuler des points de fidélité. Elle sera partagée avec l’ERP pour la facturation ; la comptabilité ; la logistique. Autant de services qui viendront enrichir la donnée initiale. Sortie de la base opérationnelle, une fois agrégée dans un cube, elle permet d’analyser la situation client pour 2020 et de comparer le nombre de clients à 2019.
Analysée et exploitée dans les modèles des Data Scientist, elle permettra donc de déterminer les objectifs de l’acquisition de nouveaux clients en 2022….
La donnée aura été manipulée pour permettre ces différents usages ! Simplification, anonymisation, enrichissement sont autant d’étapes nécessaires à son exploitation. La donnée originale existe toujours mais a produit des artefacts exploités à différents niveaux de l’organisation.
Exemple :
Demain, votre client change d’adresse. Faut-il garder l’historique ? Doit-on le rapprocher de nouveaux groupes clients ?
Si l’enseigne fusionne avec une autre entreprise : comment rapprocher le client présent dans les deux bases ?
Et si le client demande, conformément à son droit, de ne plus faire partie de votre base ? A-t-on encore accès à cette information dans le tableau de bord clientèle ?
Comment déterminer la fraîcheur de la donnée et comment la supprimer si elle est obsolète ?
D’ailleurs, toutes ces questions sont directement convexes à celle de la gouvernance de la donnée qui dirige la façon de conserver, de partager et d’exploiter les données conformément à leur valeur, au droit applicable et à la sécurité.
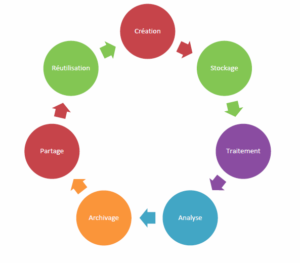
Qui sont les acteurs du cycle de vie de la donnée ?
Administrateur de base de données, juristes, décideurs… nombreux sont les parties prenantes de ce cycle administré par le CDO (Chief data officer) et relayé par le garant de la qualité des données.
Quels sont les outils du cycle de vie ?
- Référentiels métiers
- Monitoring
- Data Warehouse
- Cadre juridique
- MDM
- Data Lake
- CDP (Customer Data Platform)
- Data Lakehouse
- PIM (Product Information Management)
Conclusion
ça y est, vous êtes incollable sur la donnée. A mi-chemin entre un produit et une ressource, la donnée est une denrée vivante ! En plus, sa fraîcheur, sa qualité et sa pertinence sont les seules garanties d’une véritable valeur. Au contraire, une donnée négligée fait peser un grand risque sur votre organisation.
Nous l’avons donc vu, la bonne gestion de la donnée est autant une question d’outil et de processus qu’une question organisationnelle et humaine ! En résumé, ces diffférents rôles… sont autant de spécialistes de la donnée, piliers de votre gouvernance !
