

Apache Spark est un framework de data processing qui permet de traiter de gros volumes de données. Spark se charge de distribuer le calcul sur plusieurs machines en utilisant principalement les mémoires vives (RAM). Le projet a été initié par Matei Zaharia dans le laboratoire AMPLAB de l’université de Berkeley en 2009 avant d’être confié à la fondation Apache. Matei est actuellement le CTO de Databricks, la société commerciale derrière Apache Spark.
Spark est l’un des projets les plus actifs de la fondation Apache tous domaines confondus (pas uniquement dans la branche Big Data). Spark a été développé pour pallier aux manquements suivants de MapReduce :
- Quel que soit le problème à résoudre il faut le modéliser en une succession d’opérations Map et Reduce (ce qui s’avère difficile pour certains cas d’utilisation, voire impossible à utiliser)
- Lors de différentes phases de Map et Reduce, les résultats intermédiaires sont écrits sur le système de fichier HDFS. Les accès disques étant généralement plus coûteux, cela introduit de la latence dans les traitements MapReduce.
Spark corrige ces manquements en utilisant la mémoire vive plutôt que le système de fichier HDFS, tout en offrant beaucoup plus d’opérations que MapReduce (MapReduce n’offre que 2 opérations : Map() et Reduce()) mais aussi il est plus complet que ce dernier. Spark permet de faire, en outre, les traitements batch, du streaming, du calcul de graphe, du datamining et aussi du traitement SQL. Le Data Engineer peut utiliser Apache Spark pour faire ses jobs ETL et le Data Scientist peut aussi faire ses modèles sur la même plateforme.
Dans ce billet je vais me concentrer sur les fonctionnalités ETL de Spark.
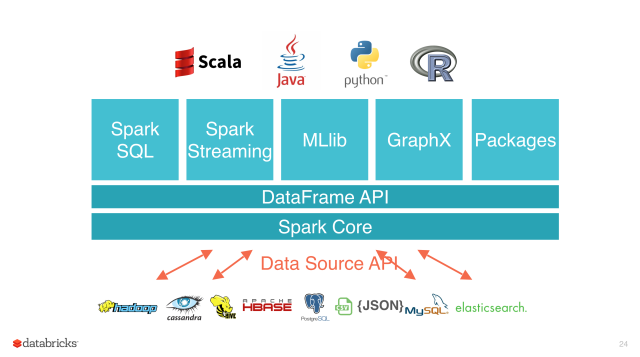
Spark Core est basé sur les collections immutables, les RDD (Resilient Distributed Dataset). Les premières versions de Spark étaient basées sur les API du Spark Core qui donnaient des performances différentes suivant les langages de programmation utilisés. Avec le projet Tungsten, dans la version 2 de Spark, on voit apparaître des notions de dataframe et de dataset, qui est une surcouche intermédiaire qui permet d’avoir des performances uniformes, quel que soit le langage.
Un programme Spark s’exécute comme une suite de processus indépendants coordonnés par un objet SparkContext du main program (ou driver program). Le SparkContext dans le mode déploiement en cluster se connecte à Cluster manager qui, lui, alloue les ressources (CPU, RAM etc ). Une fois connecté au ressource manager le sparkContext acquiert des « executors » sur les machines du cluster qui font le calcul distribué et aussi stockent les données de votre application.
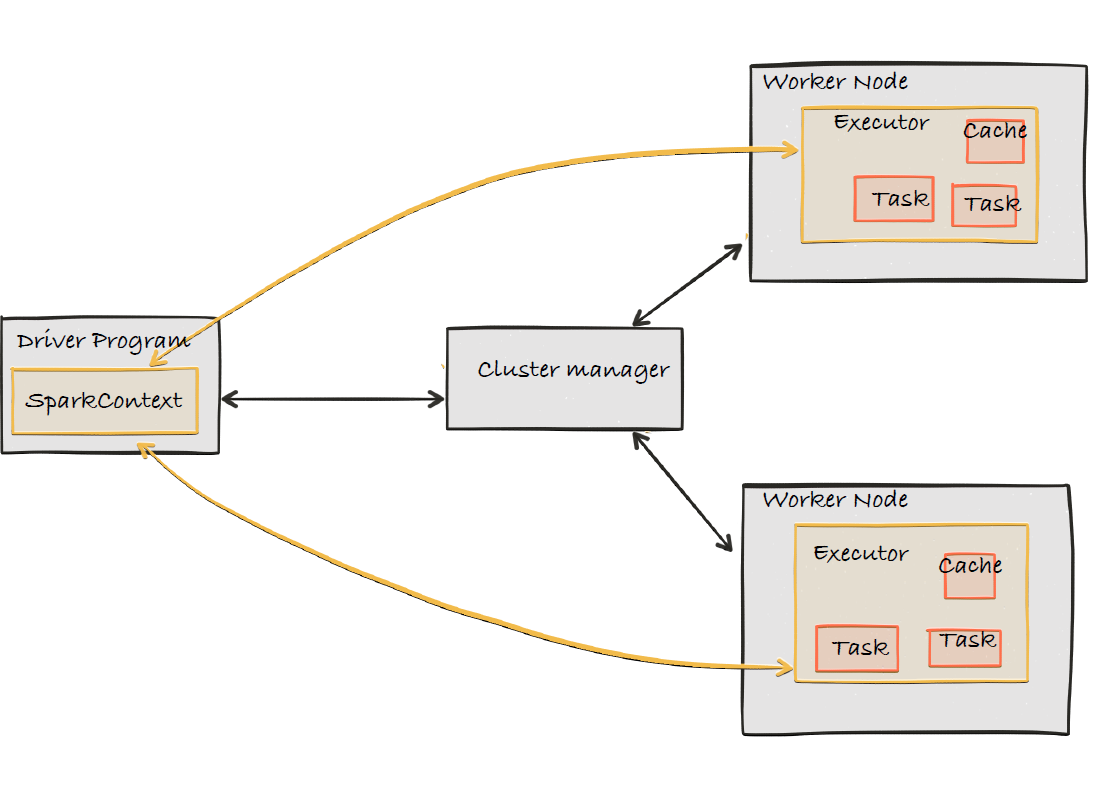
Une application Spark peut tourner en 3 modes :
- en mode local (permet d’exécuter Spark sur une machine et peut utiliser les cœurs de machine pour du multi-threading)
- en mode standalone (utilise dans ce cas un gestionnaire de ressources internes incorporé à Spark)
- en mode cluster (avec un gestionnaire de ressources comme Yyarn sur Hadoop ou avec Mesos)
J’ai choisi de faire un développement en local avec du Scala pour me familiariser avec l’environnement Spark et me départir des contraintes de l’installation d’un cluster. Pardon ? Comment ? Si je m’y connais en Scala ? Non du tout, sinon ce ne serait pas drôle ! Je vais donc utiliser Intellij. Pour configurer votre environnement suivez ce tutoriel.
Les API Scala de Spark sont moins verbeux que les API Java. Je vais procéder à tâtons pour montrer les grands principes de l’ETL.
Fasten your seatbelt, we are taking off to data engineering world with Apache Spark !
Pour la configuration de votre projet voici un exemple de fichier sbt pour exécuter les programmes Scala de Spark :
name := "hello-spark"
scalaVersion := "2.10.4"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.2.0"
Pour illustrer les traitements de données nous allons utiliser 2 fichiers csv suivants :
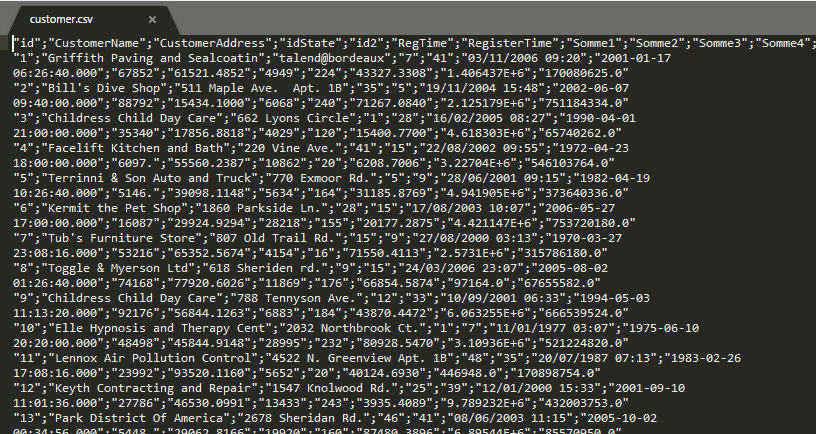
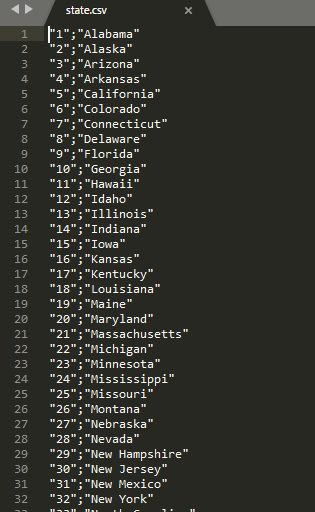
Essayons dans un premier temps de lire le premier fichier customers.csv en utilisant les sessions Spark :
import org.apache.spark.sql.SparkSession
object SparkDf {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]") // configuration de spark en mode local
.appName("Spark SQL basic example")// nom de l'application
.config("spark.some.config.option", "some-value")// on peut ajouter des paramètres spark
.getOrCreate()
val customer = spark.read
.csv("C:\\projet\\data\\customer.csv")
customer.show()
}
}
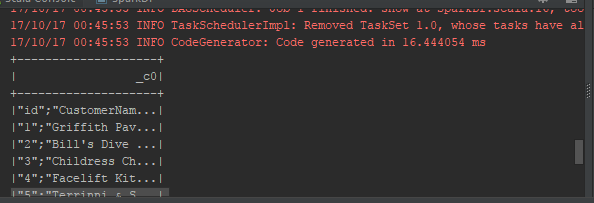
On arrive à lire le fichier mais les colonnes se sont pas bien délimitées. On va ajouter des paramètres supplémentaires pour bien prendre en compte les paramètres csv :
import org.apache.spark.sql.SparkSession
object SparkDf
{def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]") // configuration de spark en mode local
.appName("Spark SQL basic example")// nom de l'application
.config("spark.some.config.option", "some-value")// on peut ajouter des paramètres spark
.getOrCreate()
val customer = spark.read
.option("header","true")
.option("inferSchema","true")
.option("delimiter", ";")
.csv("C:\\projet\\data\\customer.csv")
customer.show()
}
}
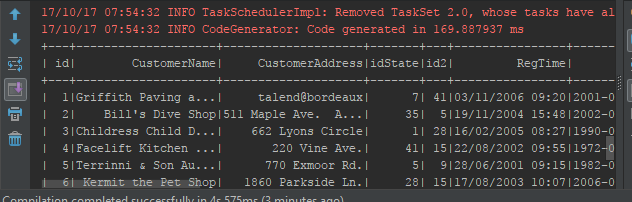
Ensuite on tente de faire une transformation en joignant les fichiers customer.csv et state.csv.
import org.apache.spark.sql.SparkSession
object SparkDf {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]") // configuration de spark en mode local
.appName("Spark SQL basic example")// nom de l'application
.config("spark.some.config.option", "some-value")// on peut ajouter des paramètres spark
.getOrCreate()</codeW
val customer = spark.read
.option("header","true")
.option("inferSchema","true")
.option("delimiter", ";")
.csv("C:\\projet\\data\\customer.csv")
val state = spark.read
.option("header","false")
.option("inferSchema","true")
.option("delimiter", ";")
.csv("C:\\projet\\data\\state.csv")
state.join(customer, customer("idState") === state("_c0")).show()// jointure entre le fichier state et customer
}
}
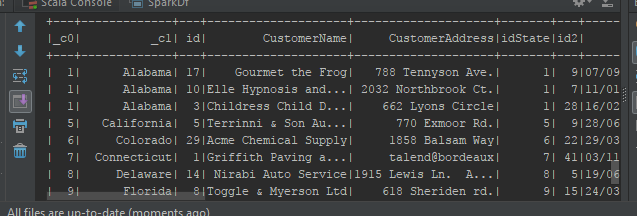
Sur ces exemples on se rend compte que le code n’est pas verbeux et aussi adapté au traitement de données. Le développeur peut ainsi profiter de la gestion de la montée en charge qu’offre un cluster Spark. Dans un autre billet on pourra poursuivre l’exercice en se connectant à d’autres sources de données et en chargeant les données dans une source de destination.
(A suivre)
Horacio Lassey
Crédit Photo : Designed by Freepik

Sections commentaires non disponible.