

Depuis quasiment quinze ans, nous intervenons chez nos clients dans le cadre de projets qui mêlent, entre autres, intégration de données et informatique décisionnelle. Aujourd’hui nous sommes de plus en plus impliqués pour concourir au succès de projets de type Business Intelligence, Master Data Management, Data Lake, applications analytiques à façon… Quels points communs partagent tous ces types de projets ? Bien entendu la donnée et surtout, sa qualité !
Mettre en exergue la qualité des données
Il est toujours intéressant de capter le contexte qui précède la décision de lancer un projet informatique dans les organisations. Il apparaît souvent utile de se faire expliquer un peu l’historique de la construction d’une application. En effet, il est alors plus facile de comprendre pourquoi en bout de chaîne, la qualité des données n’est jamais aussi optimum qu’attendue : “le chiffre que vous m’annoncez n’est pas le bon” !
Dans la plupart des cas, il s’agit de prendre des décisions à partir de faits tangibles. Or, si l’on s’appuie sur des données erronées, il est difficile de prendre les bonnes décisions à la fin.
Faisons un test : tapez dans votre moteur de recherche favori “Non-Qualité de Données”…
Ce qu’il faut surtout noter c’est le coût de la non-qualité de la données. Une étude de 2015 faite par AT&T montre que chaque année la non-qualité de donnée représenterait quelques 600 milliards de dollars rien qu’aux Etats-Unis (1) ! A l’ère du Big Data ce record a sans doute déjà été battu.
La qualité de données revêt de nos jours une importance capitale car avec de la donnée impropre, le machine learning (en très forte progression) fournira des résultats complètement inappropriés ! Il est même à penser que l’on parlerait d’introduction de biais dans l’algorithme.
La qualité des données désigne l’aptitude de l’ensemble des caractéristiques intrinsèques des données (fraîcheur, disponibilité, cohérence fonctionnelle et/ou technique, traçabilité, sécurisation, exhaustivité) à satisfaire des exigences internes (pilotage, prise de décision…) et des exigences externes (réglementations,…) à l’organisation” (2).
Cette définition ne dessine pas pour autant le contour des origines de la non-qualité. Comment apparaît-elle ? Évidemment, elle est souvent due à des erreurs humaines ou organisationnelles. Des erreurs de saisies, des interfaces utilisateurs où les validations sont peu rigoureuses… Dans le cadre d’import de données, cela peut aussi être des règles mal définies pour enrichir le jeu de données. Durant des étapes de maintenance de base de données, une suppression de contrainte que l’on oubliera de réactiver… Les cas sont finalement très nombreux.
Démarche qualité de données : globalement
La mise en place d’une démarche de gestion de qualité de données s’accompagne de bon sens, de rigueur, de responsabilité.
Il est important de clairement identifier des responsables de la donnée pour celle issue de vos logiciels métiers, ainsi que celle reçue de vos partenaires.
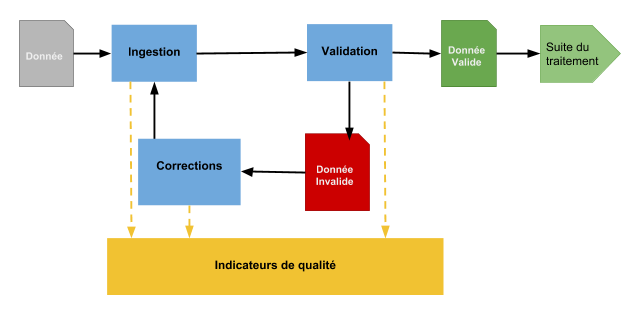
A chaque étape où la donnée entre dans votre système d’information, il convient d’avoir une sorte de pare-feu. Si vous recevez de la donnée de votre partenaire, le / la responsable désigné(e) la valide. S’il s’agit d’une donnée saisie, alors il faudrait que ce pare-feu de donnée soit intégré au logiciel où l’enregistrement prend naissance. Les règles de consistance de la donnée valident la possibilité de l’insérer ou pas.
Dans le cas d’une démarche d’entreprise telle que la construction d’un Data Warehouse, d’un MDM, d’un Data Lake, ou encore dans le cadre d’une indexation de données pour un moteur de recherche, il faut une implication complète des responsables de données voire de toute l’organisation.
Comme déjà évoqué plus haut, la problématique de la qualité de données est telle que l’organisation toute entière doit être dévolue à l’éradication de cette non-qualité.
Cette démarche qualité de données associée aux principes du Cloud, du Big Data, au mouvement DevOps a fait naître un nouveau courant : le DataOps (3)!
Si nous nous focalisons sur le cadre de la construction d’un Data Warehouse, la gestion de la qualité ne s’arrête pas uniquement à la phase d’ingestion de la données. Tout au long des différentes étapes, un nombre de tests conséquents s’articulent pour d’une part, valider la donnée au fur et à mesure et d’autre part, tracer l’ensemble des transformations, améliorations, enrichissements, agrégations des enregistrements.
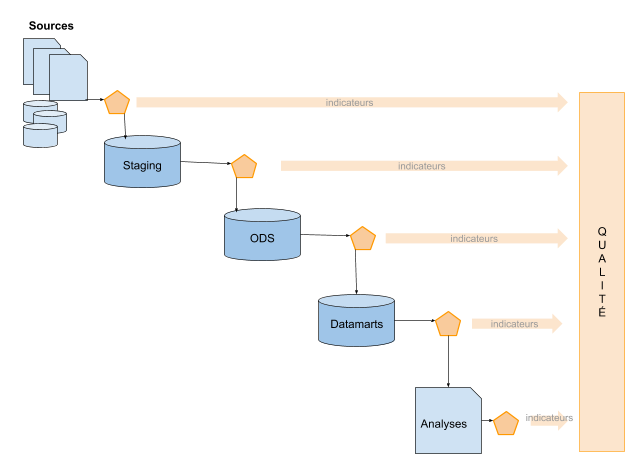
Tous ces tests permettent de livrer des données dont la qualité est optimum et surtout d’avoir une traçabilité intégrée. C’est entre autre une manière de mettre en œuvre le fameux data lineage.
Afin de détailler le propos il convient tout de même de s’arrêter sur les types d’indicateurs utiles à la mise en place des tests qui jalonnent les étapes d’intégration (ETL, streaming) des processus de raffinement des données.
Il existe 6 types d’indicateurs de qualité de données :
- Profil de données – analyses statistiques : distribution des données, unicité, nombre d’attributs vides…
- Exactitude : les données reflètent-elles l’activité métier
- Complétude : toutes les données nécessaires à l’observation de l’activité métier sont-elles présentes
- Conformité : toutes les valeurs de données de l’activité respectent-elles les règles métier spécifiées
- Intégrité : les données sont-elles cohérentes les unes par rapports aux autres
- Consistance : les données renferment-elles des doublons
- Disponibilité (Timeliness) – Les données sont-elles disponibles dans les délais autorisés
Au delà du bon sens et pour aller plus loin, la qualité de données suit tout de même, des étapes distinctes :
- Profilage des données
- Nettoyage
- Homogénéisation
- Dédoublonnage
- Enrichissement
- Suivi des indicateurs
Outils et solutions
Tout au long de votre lecture vous avez dû vous rendre compte à quel point l’organisation devait être impliquée, et que la qualité de données s’inscrit définitivement dans une démarche d’entreprise. Vous n’aurez pas de stratégie digitale sans donnée. Et elle existera encore moins si vous n’y associez pas une démarche de qualité de données.
Heureusement, de nombreux outils et solutions existent pour entreprendre une véritable stratégie de qualité de données. Vous pouvez démarrer avec des processus maison à base d’ETL, de routines… Vous pourrez aussi mettre en place des solutions éditeur. Mais, une chose est sûre : vous compterez avec vos équipes pour que la démarche qualité fasse partie de votre culture et serve votre stratégie digitale.
Chez Synaltic nous utilisons selon les cas Talend Data Quality, Apache Griffin, ou encore des solutions maisons basées sur des librairies open source pour répondre aux enjeux de la qualité de données.
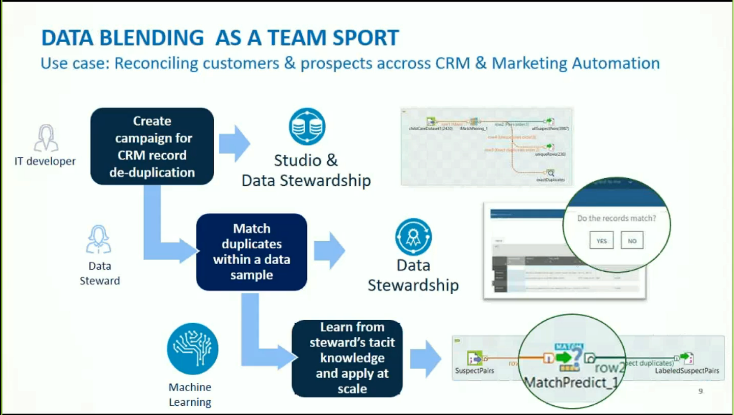
Talend Data Quality
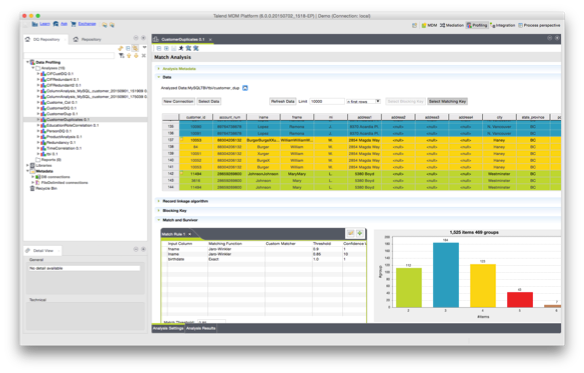
Talend Stewardship Console scénario (5) (6)
Apache Griffin : Mesurer est le maître mot

La plupart des solutions reprennent en grande partie l’architecture décrite par Ralph Kimball et entre autre son modèle screen pour le suivi des erreurs.
A notre sens, il n’existe pas de solution complètement globale et toute automatisée qui soutiendrait une démarche de qualité totale de données. Ces solutions ne couvrent souvent qu’une partie de la chaîne.
La recherche de cette qualité optimale de données peut être atteinte dans le cadre d’un projet de type Data Warehouse, MDM, Data Lake, d’indexation de données couplé à une démarche de qualité de données où l’on est en mesure de réinjecter la donnée “propre” dans le système source.
Charly Clairmont
(1) Data Quality: The other Face of Big Data. Barna Saha, Divesh Srivastava
(2) Qualité des données, Quelle(s) vérité(s) dans les entreprises. PWC, Micropole, EBG
(3) The DataOps Manifesto
(4) White Paper: An Architecture for Data Quality, Ralph Kimball
(5) Talend Data Stewardship Application – Get Started Building Governance, Talend
(6) Team-Driven Data Quality and Data Stewardship – Spring ’18, Talend

Sections commentaires non disponible.