

Entre les débuts de notre (jadis) petite équipe web et son fonctionnement actuel, les process et les outils n’ont pas toujours été les mêmes. Vous avez toujours voulu savoir comment travaille la talentueuse #SynalTeam ? C’est le moment de nous accorder toute votre attention !

Bonjour, je m’appelle Fabien et je suis développeur web chez Synaltic depuis 2 ans.
Lorsque Synaltic a démarré les projets web, nous étions une petite équipe de deux-trois développeurs qui travaillaient sur le même projet. Aujourd’hui, comme nous avons plus de projets, l’équipe a dû s’agrandir pour arriver à six développeurs.
Au moment de commencer notre premier gros projet de développement Web, il nous est rapidement apparu nécessaire d’être organisés, car d’autres développeurs allaient rejoindre l’équipe. Il allait falloir aussi bien choisir les frameworks et librairies à utiliser.
Les frameworks utilisés
Historiquement, nous utilisons le framework MeteorJS, justifié par des temps de développements de POC (Proof Of Concept) assez courts, sa réactivité, ainsi que par son intégration du JavaScript côté client et serveur.
Par la suite, nous avons voulu nous diriger vers une architecture par micro services. Meteor regroupant déjà les services côté client, côté serveur ainsi que la base de données dans un seul framework, nous nous sommes tournés vers le framework NodeJs et le paquet NPM Express afin de créer nos API serveurs exécutant des opérations dans MongoDB et VueJS pour le côté client.
Nous sommes arrivés à la conclusion que MeteorJS est pratique pour des petits projets mais les temps de build de l’application augmentent considérablement au fur et à mesure que l’application grossit. Et puis, nous utilisons Docker, qui n’est vraiment pas simple à intégrer avec MeteorJS.
Vue, en revanche, un framework qui permet de créer des composants réutilisables afin de créer des interfaces utilisateurs, est simple à appréhender et il est rapide d’y ajouter ou de modifier des composants. Nous utilisons la fonctionnalité “Single File Components” qui nous permet de définir nos composants dans des fichiers .vue qui contiennent le template, le JavaScript et le CSS. Vue nous permet aussi bien de développer des widgets indépendants que des sites webs complets comprenant différentes pages et requêtant des API.
Le framework NuxtJs, quant à lui, nous permet le rendu d’applications Vue côté serveur (SSR). Il inclut par défaut les modules: Vue 2, Vue router, Vuex, Vue server renderer et vue-meta.
Processus de livraison
Comme tous les devs de l’Univers, ou presque, l’équipe utilise Git pour le versioning. Mais notre utilisation de celui-ci était jusqu’alors assez rudimentaire. Nous n’avions pas de processus de branche, de merge ou de livraison définis. Au mieux nous avions une branche de dev et notre branche principale, master, et nous faisions les merges “manuellement”.
Suite à une formation de 3 jours délivrée par Delicious Insights sur le logiciel Git, nous sommes montés en compétence, ce qui nous a permis d’améliorer nos processus itérativement.
Nous avons alors installé GitLab et utilisons désormais les merges requests, qui demandent la validation par un autre développeur que l’auteur de la modification.
De repo par service à mono repo
Un des projets sur lequel nous travaillons actuellement est composé de plusieurs micro services. Au son lancement, nous avions un repository Git par micro service mais des problèmes se sont rapidement posés : lorsque nous travaillions sur une tâche qui nécessitait la modification du code de plusieurs micro services, il fallait pusher sur plusieurs repositories et notre processus d’intégration continue ne pouvait pas fonctionner ainsi.
Lorsqu’une modification était effectuée sur plusieurs micro services, les collaborateurs ne pouvaient pas savoir quel repository il fallait puller, ce qui n’était, non plus, pas vraiment pratique.
Bien sûr, nous aurions pu modifié notre processus d’intégration continue mais cela nous aurait pris plus de temps de savoir quelle version de quel micro service il fallait livrer au client, car certaines fonctionnalités ou corrections de bugs y étaient présentes.
Nous avons donc migré vers le mono-repo, ce qui signifie que tous nos services sont regroupés dans un répertoire “services”. Nous utilisons LernaJS pour gérer les dépendances NPM de nos services. Grâce à LernaJS il nous est facile d’installer les dépendances de chacun de nos services en exécutant la commande lerna bootstrap à la racine de notre projet.
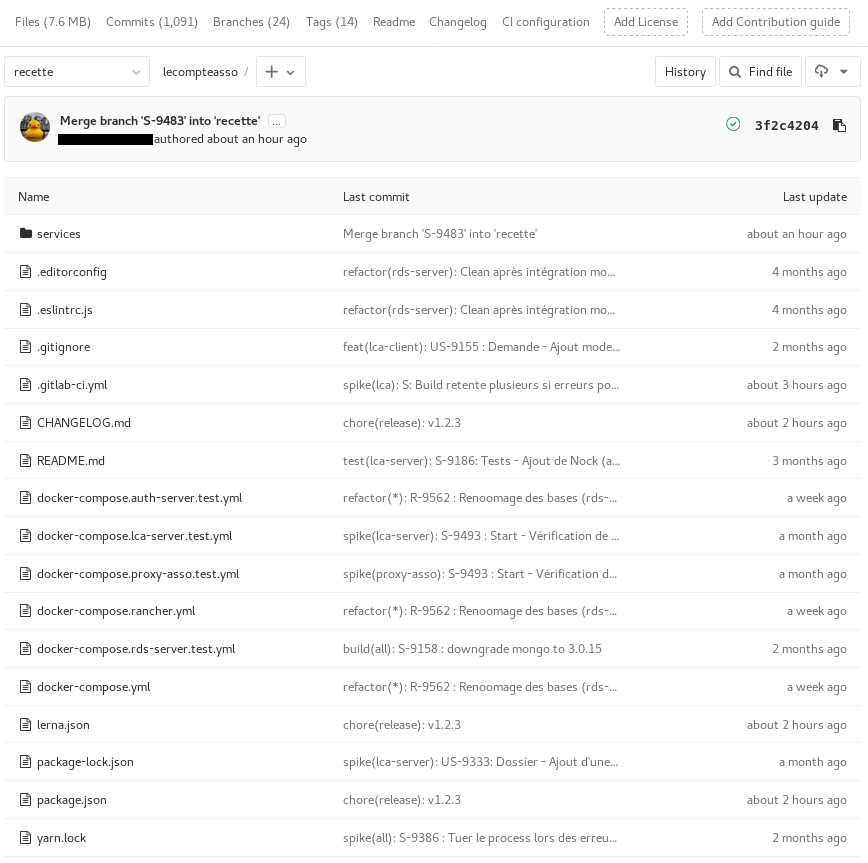
Chaque demande dans notre outil de gestion de projet (Redmine) correspond à une branche sur notre repository Git, où le nom de chaque branche est composé de la première lettre du type de demande ainsi que son numéro.
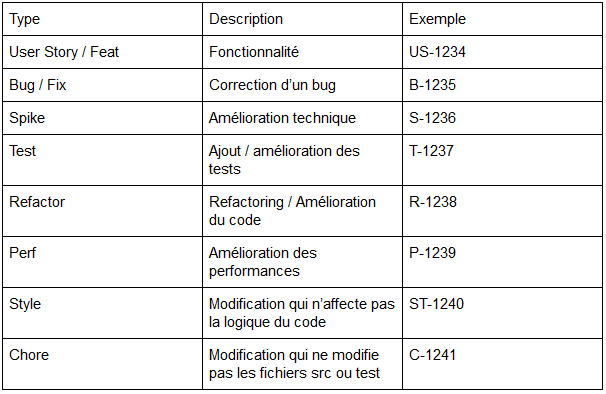
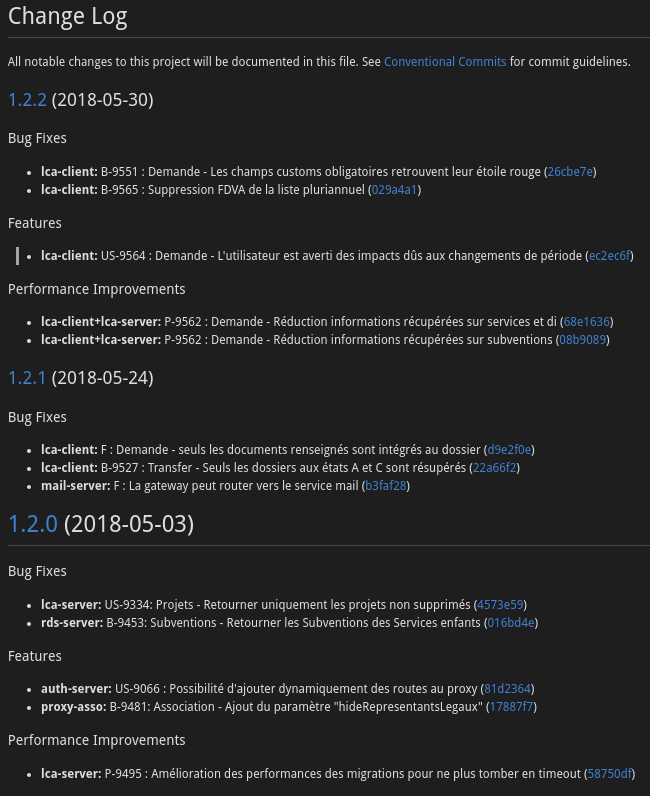
Pour faciliter l’historique des branches et uniformiser nos messages de commit, nous utilisons Commitzen . Afin de versionner nos applications, nous utilisons le Semantic Versioning et chaque version est taguée dans notre repository Git. Commitzen nous permet également de générer le changelog au format Markdown simplement. En voici un exemple :
“Tester, c’est douter ?” FAUX !
Au fur et à mesure que les projets se complexifient, les effets de bord apparaissent et sans tests (unitaires, intégrations), il devient difficile de les détecter avant la livraison.
Chaque modification qui est poussée sur le serveur Gitlab déclenche un processus appelé pipeline. Ce dernier exécute les tests unitaires serveurs (nous utilisons Jest pour cette partie) et si tous les tests sont au vert, il build une image Docker stockée sur Nexus et déploie une instance de test de l’application (une instance par branche) dans une stack de dev qui se trouve dans notre orchestrateur Rancher.

Voici un exemple de pipeline: dans chaque colonne les jobs sont exécutés en parallèle.
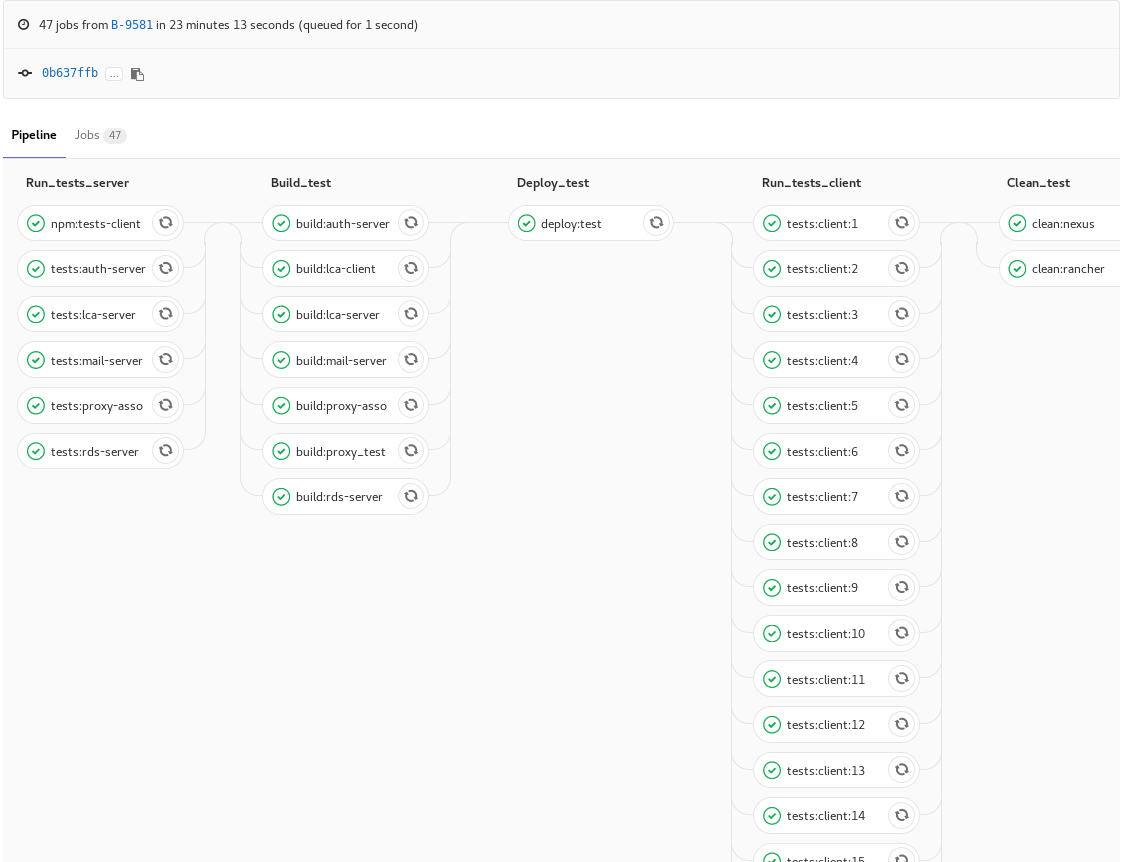
Une fois l’application déployée les tests du client sont lancés, pour cela nous utilisons Testcafe. Si ces tests sont positifs alors l’instance de cette l’application est supprimée.
Si tout le pipeline est bon, alors on peut soumettre une merge request et si le code ne convient pas et/ou que ce n’est pas la bonne façon de procéder, la ligne de code en question sera commentée (une discussion est ouverte) et le code devra être corrigé avant que la merge request soit acceptée.
Une fois que la merge request est acceptée, le client valide ou non la demande dans notre outil de gestion de projets.
Conclusion
L’avantage d’avoir un processus de livraison comprenant les tests et le déploiement de l’application nous permet de nous assurer que l’application démarre correctement et est fonctionnelle.
Depuis que nous avons mis en place ces processus d’intégration continue au sein de nos projets, nous les améliorons afin qu’ils soient plus complets.
La validation des merge request par d’autres développeurs requiert du temps mais cette méthode est très enrichissante car elle nous permet d’avoir un point de vue différent du nôtre et parfois de faire apparaître des problèmes inconnus. Cette méthode peut convenir à des équipes d’au moins deux développeurs.
Et si vous n’utilisez pas les merge requests, il est possible de faire une revue de code afin de discuter d’un bout de code (le sien ou celui d’un collègue).
Pour mettre en place de genre de processus il faut évidemment que les développeurs se prêtent au jeu, même si ce n’est pas un gros projet. Mettre en place des tests et participer aux revues de code sont de bonnes habitudes à prendre pour que cela deviennent un “automatisme”.
Fabien Oger

[…] une approche CI/CD afin d’automatiser ses processus, n’hésitez pas à aller consulter notre article de blog sur la question si cela vous […]
[…] Synaltic, nous avons au fil des années mis en place des processus de validation plus généralement connu sous le nom de CI/CD. De manière à ce que le code fourni réponde tant […]
[…] Une présentation de l’évolution de nos processus de développement. […]