

Merci à Dipankar Mazumdar, Jason Hughes, JB Onofré pour mettre en relief ce qu’est un data lakehouse. The Data Lakehouse: Data Warehousing and More
Le data lakehouse est un nouveau modèle d’architecture. Nombreux soutiennent qu’il a commencé à remplacer l’architecture bien connue de l’entrepôt de données. Ce nouveau modèle repose sur
- le stockage objet peu coûteux,
- des formats ouverts (ex : Parquet, Iceberg, Delta),
- un moteur de traitement performant qui offre ainsi un support de premier ordre pour l’ingénierie des données (transformation des données, ETL, ELT),
- l’analyse de données (BI) et de l’inférence (science des données),
- un catalogue de toutes les jeux de données où qu’ils soient.
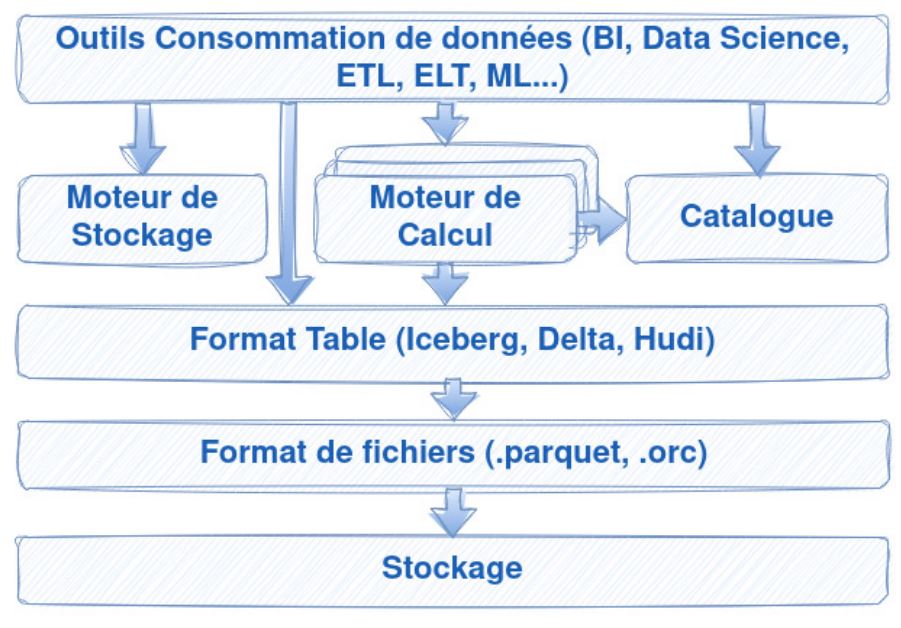
Le modèle d’architecture de données du data warehouse est dépassé ! Il présente un nombre certain de manques qui a souvent pour conséquence la prolifération des copies de la même donnée en fonction de l’utilisation qui en est attendue. Et si l’on considère les formats ouverts actuels, le modèle du data warehouse enferme les utilisateurs dans un stockage propriétaire, une prison dorée, du verrouillage fournisseur. Le data lakehouse offre la flexibilité du data lake et l’accès simplifié du data warehouse ! Le data lakehouse répond :
- à la modélisation des données : définir le modèle de données qui décrit l’activité réelle des métiers, capturant les relations entre les entités métier.
- à l’intégration de données : contrairement au data warehouse classique, il n’est point nécessaire de transformer la donnée avant de la charger afin de contraindre à un schéma. Schéma qui peut s’avérer inapproprié, obligeant à revoir le processus de chargement ! Le data lakehouse, tel le data lake offre la possibilité du chargement des données avec la flexibilité du schéma à la lecture. Les capacités de transformation des données peuvent être faites avec l’outil de son choix.
- la qualité des données : comme dans un data warehouse vous êtes en mesure de bâtir vos référentiels (CDP, PIM…), y compris ceux pour vos données maître (MDM). Vous êtes aussi en mesure de gérer l’historique des données avec par exemple les techniques de dimension à changement lent, ou implémenter des modélisation tel que data vault.
En plus, le data lakehouse offre de nouvelles possibilités : une réduction des copies de données, une meilleure gouvernance des données, une capacité inédite d’isoler les traitements (data as code). La complexité liée à la gestion de l’infrastructure qui soutient les systèmes d’information actuellement, notamment induite par le cloud computing, oblige à reconsidérer la manière dont les données sont gérées. Il convient donc que toutes les organisations s’emparent de ses enjeux. Vos données sont vos données ! Ce n’est qu’un conseil.
Découvrir Dremio
Synaltic est partenaire Dremio depuis 2021 et nous sommes ainsi le premier intégrateur en France de l’Open Data Lakehouse Dremio !
Organiser une démonstration
*champs obligatoires
