

Un tour d’horizon des outils pour construire et déployer des modèles de machine learning robustes et prêts pour la production.
Quand il ne fait pas du python, le synalticien Marc Chevallier s’intéresse de près au Machine Learning, c’est ainsi qu’il a choisi de traduire pour vous, en français s’il vous plaît, cette article écrit par Ben Lorica, Harish Doddi, et David Talby, publié le 19 juin 2019.
Nos analyses [1] des quelques dernières années [2] ont montré un intérêt croissant pour le machine learning (ML) au sein des entreprises de divers secteurs. Différents facteurs contribuent à ce fort intérêt d’implanter du ML dans les produits et les services. Tout d’abord, la communauté du machine learning a mené des recherches innovantes dans de nombreux secteurs d’intérêts pour les entreprises, et beaucoup de ces recherches ont été présentées de manière libre dans des prépublications ou des conférences. De plus, il devient monnaie courante de voir des chercheurs partager une partie de leur code [3] écrit avec des librairies open sources populaires, certains allant même jusqu’à partager des modèles pré-entraînés [4] avec la communauté. Les organisations ont également plus de cas d’utilisation et de cas d’étude desquels s’inspirer. Quelque soit l’industrie ou le domaine qui vous intéresse, il y a de grandes chances qu’il existe de nombreuses applications de ML desquels s’inspirer. Enfin, les outils de modélisations s’améliorent, et l’automatisation commence à permettre aux nouveaux utilisateurs de s’attaquer à des problèmes qui étaient précédemment l’apanage des experts.
Avec cette tendance à l’implémentation de machine learning, on s’attend à une amélioration des outils visant à aider les entreprises à intégrer le ML dans leurs process. Dans des articles déjà publiés, nous avons ainsi souligné l’importance des fondations technologiques nécessaires pour soutenir le machine learning [5] au sein des organisations, ainsi que déceler les premiers signes indiquant l’intérêt des utilisateurs pour les outils de développement de modèles et de gouvernance de modèles [6].
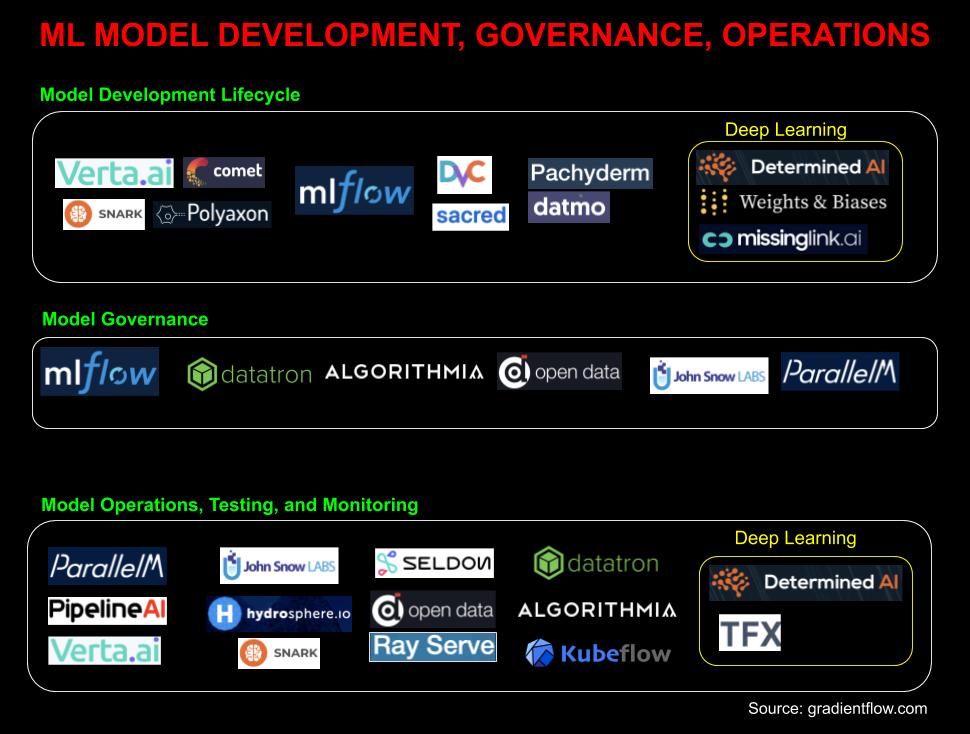
Figure 1 : Un ensemble d’outils centrés sur le développement de modèles, la gouvernance, et les opérations. Source : Ben Lorica
Développement de modèle :
Un signe certain que les entreprises se concentrent sur le machine learning est le succès grandissant des outils conçus spécifiquement pour gérer le cycle de développement de modèles de ML, comme MLflow [7] ou Comet.ml [8]. Pourquoi les outils traditionnels ne sont ils plus suffisants ? Dans un précédent article, nous avons noté quelques caractéristiques principales qui distinguent un projet de machine learning des autres :
- Contrairement aux logiciels traditionnels où le but est d’atteindre des spécifications fonctionnelles, l’objectif en ML est d’optimiser une métrique.
- La qualité ne dépend pas juste du code, mais aussi des données, du tuning, des mises à jour régulières, et du ré-entraînement.
- Ceux qui s’occupent du ML veulent généralement tester des nouvelles “librairies”, algorithmes, et sources de données, et donc être capables de mettre ces nouveaux composants en production.
L’adoption croissante d’outils comme MLflow [6] indique que des nouveaux outils sont de facto très demandés. Ces outils de développement de ML sont spécifiquement conçus pour aider les équipes de développeurs, les ingénieurs en machine learning [9] et les “data scientist” à collaborer, gérer, et reproduire les tests de ML. Ainsi, beaucoup de ces outils laissent systématiquement l’utilisateur gérer la modélisation (ex : optimisation des hyperparamètres, recherche de l’architecture du réseau de neurones) [10] mettant l’accent sur la facilité avec laquelle chacun peut gérer, suivre et reproduire ces tests.
Gouvernance des modèles :
Tout comme les entreprises ont longtemps traitées les données comme des atouts, alors que le ML devient plus central pour les métiers des organisations, les modèles vont également être traités comme des atouts importants. Plus précisément, les modèles construits ou optimisés pour des applications spécifiques (dans la réalité, cela signifie le modèle + les données) vont avoir besoin d’être gérés et protégés [6]. Pour ce faire, la gouvernance des modèles nécessitera un ensemble d’outils de gestion:
- Une base de données pour les accès et la sécurité : qui a les droits de lecture / écriture sur un certain modèle.
- Un catalogue ou une base de données qui liste les modèles, y compris quand ils ont été testés, entraînés, et déployés.
- Un catalogue de validation des données et des mesures de précision pour les modèles stockés
- Un versioning (des modèles, des vecteurs de caractéristiques [11], des données), et la possibilité de les déployer, revenir à une version précédente, ou avoir plusieurs versions en production.
- Des métadonnées et artefacts nécessaires pour réaliser un audit complet.
- Savoir qui a approuvé le modèle et a décidé de le pousser en production, qui est capable de suivre les performances et de recevoir des alertes, et qui est responsable du modèle en question.
- Un tableau de bord qui fournit des vues personnalisées pour chaque personne concernées (opérations, ingénieur ML , Data scientist, directeur)
Fonctionnement des modèles, test, et suivi (monitoring) :
Au fur et à mesure que le machine learning est adopté pour les produits et services , nous avons le besoin d’établir des rôles, des bonnes pratiques et des outils pour déployer, gérer, tester, et “monitorer” le ML dans un contexte réel de production. Quelques outils visent à gérer le fonctionnement des tests. Principalement pour déployer [12] et surveiller [13] des modèles de machine learning, (mais il est clair que nous ne sommes qu’aux prémisses des solutions dans ces domaines).
Il y a 3 problèmes communs qui diminuent la valeur des modèles de ML une fois qu’ils sont en production [14]. Le premier est le concept “drift” : la précision des modèles en production se dégrade au cours du temps , ceci émane de la différence grandissante entre les données qui ont servis à entraîner le modèle et celles sur lesquelles il est utilisé.
Le deuxième est “locality” : quand on déploie des modèles sur une nouvelle zone géographique, une nouvelle population , ou un nouveau type de consommateurs, les modèles pré-entraînés dans ces cas ne fonctionnent que rarement au niveau de précision attendu. Mesurer en ligne la précision par utilisateur / zone géographique / groupe de population est important, pour mesurer le biais et assurer la précision pour une masse croissante d’utilisateurs.
Le troisième soucis est la qualité de données : comme les modèles de ML sont plus sensibles à la sémantique des données entrantes, les changements impactant la distribution des données, qui sont souvent ignorés par les outils traditionnels de qualité de données, font des ravages sur la précision des modèles.
Au-delà du besoin de monitorer si les modèles couramment déployés fonctionnent comme prévu, un autre challenge est de savoir si un nouveau modèle propose réellement de meilleures performances en production. De nouveaux systèmes [15] commencent à apparaître et autorisent la comparaison d’un “modèle titulaire” contre “le modèle challenger”, ceux ci incluant la possibilité de lancer le modèle challenger en “dark launch” ou “hors ligne” (lancer le modèle sur les données entrantes de production sans que cela n’affecte les résultats en production). Les possibilités notables incluent :
- Des outils d’intégration et de test en continue des modèles. Un modèle n’est pas “correct” s’il retourne une valeur valide, il se doit ainsi d’atteindre un seuil de précision. Il faut trouver un moyen de valider cela par rapport à une métrique et un jeu de données de validation avant de déployer le modèle.
- Une mesure en ligne de la précision de chaque modèle (quelle est la précision que les utilisateurs expérimentent “au quotidien” ?). En lien avec cela, il faudra pouvoir monitorer le biais, les effets locaux, et les risques associés [16]. Par exemple, les résultats ont souvent besoins d’être éclatés suivant les populations (les hommes et les femmes donnent-ils une précision similaire ?) ou selon les spécificités géographiques (des utilisateurs allemands et espagnols engendrent ils la même précision ?).
- La capacité à gérer la qualité du service de prédiction du modèle pour différents utilisateurs, gestion du nombre d’appels, limite de la taille des requêtes, évaluation, détection des robots, et IP Géolocalisation.
- L’aptitude à se mettre à l’échelle (de manière automatique), sécurisé, monitoré, le dépannage en direct des modèles. La mise à l’échelle à deux dimensions : le volume du trafic passant par le modèle et le nombre de modèles qui ont besoin d’être évalués.
Le fonctionnement et le test des modèles est encore un domaine naissant où des vérifications systématiques commencent tout juste à être créées. Un aperçu d’un papier de 2017 de Google [17] nous permet d’évaluer à quel point des outils sont toujours nécessaires pour la gestion du fonctionnement des modèles et des tests. Ce papier est venu avec une liste de vérification de 28 points qui détaillent les éléments nécessaires pour obtenir un système atteignant des standards de production fiables en ce qui concerne le ML :
- Les fonctionnalités et les données : sept points qui incluent des vérifications, le contrôle du respect de la vie privée, la validations des fonctionnalités, explorer la nécessité et le coût des fonctionnalités, et d’autres tests sur les données.
- Des tests pour le développement de modèle : sept tests de santé du système : incluant la vérification si un modèle plus simple pourrait suffire, les précisions du modèle sur des sous-ensembles critiquent (ex : pays, age, nouveauté, fréquence..), l’impact du vieillissement du modèle, et d’autres considérations importantes.
- Tests d’infrastructure : Une autres liste de sept points à considérer incluant: la reproductibilité de l’entraînement du modèle, la facilité avec laquelle le modèle peut être ramené à une version précédente, des tests d’intégrations de bout en bout de la chaîne de développement du modèle. La possibilité de tester le modèle via le processus canary [18].
- Monitoring : Les auteurs listent un série de sept points pour s’assurer que les modèles fonctionnent comme prévu. Ceux-ci incluent des test pour évaluer le degré de péremption du modèle [14], des métriques de performance (entraînement, prédiction, vitesse de traitement), valider que le code utilisé pour entraîner le modèle et celui utilisé en production génèrent des résultats équivalents, et d’autres points essentiels.
Nouveaux Rôles :
Les débats autours du machine learning tendent à tourner autour du travail des data-scientists et des experts concepteurs de modèles. Ce paradigme commence à changer maintenant que de nombreuses entreprises entrent en phase d’implémentation de leurs projets ML. Les ingénieurs ML [19], data ingénieur, développeurs, et les experts du domaine ont un rôle essentiel dans la réussite des projets ML. Pour le moment, peu (voir aucune) équipe n’a une checklist aussi étendu que celle détaillée par Google [17]. La tâche de produire un modèle de ML “dans le monde réel” capable d’atteindre les standards nécessaires à un déploiement en production nécessite de rassembler des outils et des équipes transverses à plusieurs secteurs fonctionnels. Cependant, au fur et à mesure que les outils pour la gouvernance des modèles, leurs gestion de fonctionnement et leurs tests commencent à s’améliorer et à devenir plus largement disponibles, il est probable que les spécialistes (“ML ops team”) puissent être en charge de ce type d’outils. L’automatisation va aussi être primordial [20], puisque ces outils vont avoir besoin de permettre aux organisations de construire, gérer, et monitorer de plus en plus de modèles de machine learning [21].

Figure 2 La demande pour des outils de gestion de ML dans les entreprises. Source: Ben Lorica, using data from a Twitter poll.
Pour conclure, le développement d’outils spécialisés permettant aux équipes de gérer le cycle de développement des modèles de ML commence à voir le jour [22]. Ainsi, des outils comme MLflow sont utilisés pour suivre et gérer les expérimentations de ML (principalement hors ligne, en utilisant des jeux de données de test). Il y a aussi de nouveaux outils qui couvrent l’aspect gouvernance, déploiement en production, le service et le monitoring, mais pour le moment ces-derniers ont tendance à ne se concentrer que sur une seule librairie de ML (TFX [23]) et un outil de modélisation (SAS model manager [24]). La réalité est que les entreprises vont vouloir plus de flexibilité au niveau des librairies, des outils de modélisation, et des environnements d’utilisation. Heureusement, des start-ups et autres sociétés commencent à construire des outils accessibles propices à l’utilisation du ML au sein des entreprises.
Image: Background vector created by freepik
Source originale :
https://www.oreilly.com/ideas/what-are-model-governance-and-model-operations
Bibliographie:
1 https://ssearch.oreilly.com/?i=1;q=lorica+nathan;q1=Reports;x1=t1&act=fc_contenttype_Reports
2 https://www.oreilly.com/data/free/how-companies-are-putting-aI-to-work-through-deep-learning.csp
3 https://github.com/allenai/allennlp
4 https://github.com/google-research/bert
10 https://www.youtube.com/watch?v=UADvHfcMJek
11 https://en.wikipedia.org/wiki/Feature_(machine_learning)
12 https://www.oreilly.com/library/view/the-artificial-intelligence/9781492025894/video323441.html
16 https://www.oreilly.com/ideas/managing-risk-in-machine-learning
18 https://whatis.techtarget.com/definition/canary-canary-testing
19 https://www.oreilly.com/ideas/what-are-machine-learning-engineers
20 https://www.oreilly.com/ideas/deep-automation-in-machine-learning
21 https://www.oreilly.com/ideas/we-need-to-build-machine-learning-tools-to-augment-machine-learning-engineers
22 https://determined.ai/blog/announcing-the-future-of-ai-infrastructure/
