

[Mise à jour] cet article a plus de 5 ans, si il reste utile pour rappeler l’histoire de la solution et pour rendre compte de l’avancé du projet, cet article ne mentionne pas les dernières évolutions. Hors en 5 ans, il y’en a plein ! Pour découvrir Dremio aujourd’hui, en 2023, nous vous invitons à visiter : Dremio en 2024 !
En 2014, alors en visite à San José pour le « Hadoop Summit », nous faisions la connaissance de Julien Le Dem, un ancien de Twitter. Aujourd’hui, il travaille chez WeWork, est VP pour Apache Parquet et PMC member pour Apache Arrow, deux projets qui visent à ranger des données au format colonne, respectivement sur disque et en mémoire.
A l’époque, Julien nous parle de son projet, alors en développement, qu’il mène avec Jacques Nadeau : Dremio. Il nous invite à le suivre et à nous tenir informés de ses avancées, ce que nous ferons régulièrement…
Et dès la sortie de la version 1.0 de Dremio, en août 2017, nous avons été séduits !
Dremio, son équipe
Julien Ledem continue les projets Apache Arrow, Apache Parquet, dont se sert Dremio, mais il l’a laissé à d’autres. Aujourd’hui, Kelly Stirman – que nous connaissions déjà de chez Hadapt (racheté par Teradata) et qui est aussi passé chez MongoDB – en est le CMO.

Pourquoi utiliser Dremio ?
Construire une chaîne analytique est particulièrement complexe. On a toute une série de flux à construire, et ces derniers alimentent un data warehouse avec la modélisation dimensionnelle qui va avec. Sur le data warehouse, on amène une couche d’abstraction (BO Univers) pour en faciliter l’accès aux utilisateurs finaux. Et depuis peu est venu s’ajouter le Data Lake pour renforcer les capacités de stockage et de calcul des organisations….
Les projets de données atteignent souvent un degré de complexité assez fou alors que l’utilisateur souhaite dans le même temps un accès simplifié à cette donnée.
Voilà de nombreuses années que les utilisateurs métiers accèdent au quotidien à des plateformes intuitives telles que Facebook, ou ayant des temps de réponse rapide, comme le moteur de recherche de Google.

Encore aujourd’hui, bien que l’on ait des technologies de stockage et de calcul qui ont évolué tel que Hadoop ou S3, que l’on ait même des technologies NoSQL, ou encore plus efficientes comme Spanner de Google ou CockroachDB, il faut quand même reconnaître un besoin de dépoussiérer le marché de l’analytique. C’est ce qu’un acteur tel que Tableau a réalisé : il s’est beaucoup intéressé à l’utilisateur final, en lui simplifiant des tâches qu’il savait déjà mettre en œuvre. De nombreux éditeurs ont d’ailleurs suivi cette tendance et se sont attaqués à fournir à l’utilisateur final nombre d’outils et de solutions pour qu’il sache par lui-même manipuler la donnée. On parle de « Self-Service ».
Pourtant aujourd’hui les utilisateurs ne s’y retrouvent pas encore.

La donnée n’a cessé d’être copiée, en essayant encore et toujours de la rendre performante par rapport à l’utilisation que l’on allait en faire.
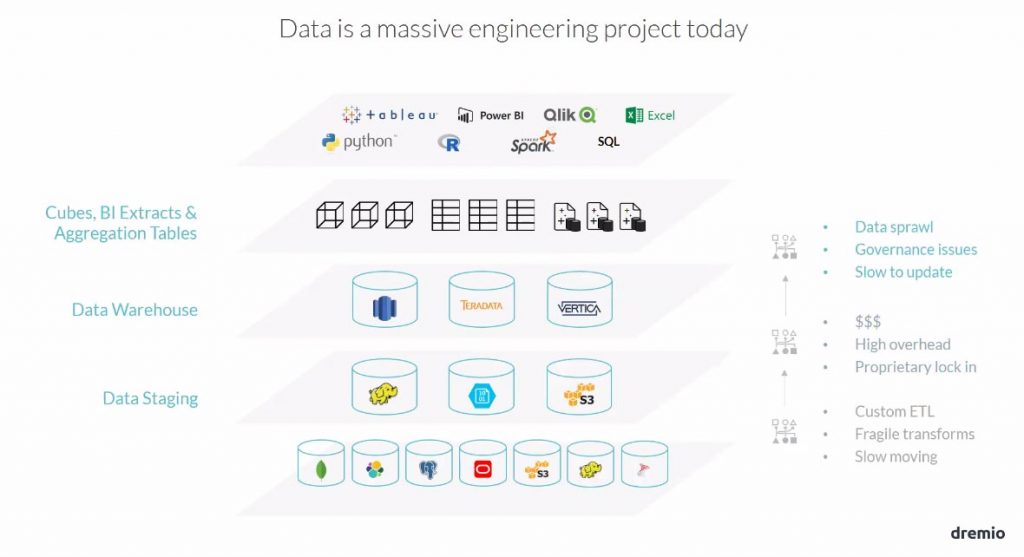
Ainsi, on n’a cessé d’augmenter le prix de possession et de traitement de cette donnée.
On a créée des couches et des couches de données… Et comme cette donnée est répartie dans de nombreux systèmes, elle demande énormément d’efforts pour la consolider et en gérer la sécurité.
Par ailleurs, DSI et les utilisateurs métier ne s’entendent jamais parce que les premiers pensent toujours que les seconds ne comprennent pas la complexité des flux ETL qu’il leur faut mettre en place pour copier, et copier cette donnée pour avoir les bonnes couches successives.
L’idée est simple « renforcer » les utilisateurs métier : leur faciliter l’accès à la donnée !
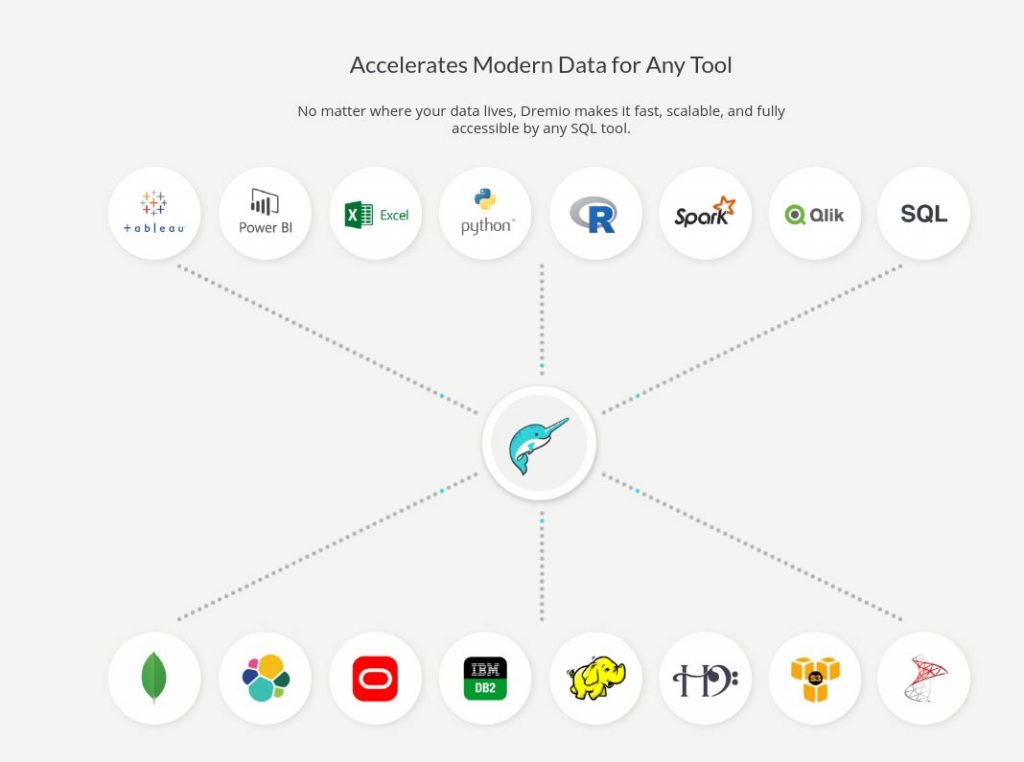
C’est dans cet esprit de simplification et d’assistance de l’utilisateur métier que Dremio a été construit : fournir un accès unique à toute la donnée des organisations, qu’il soit rapide, simple d’utilisation, avec la possibilité de croiser des données issues de sources diverses, tout en y ajoutant une abstraction dans le jargon de l’utilisateur !

Dès l’idée même du projet, ses initiateurs le pensent en Open Source : ils viennent tous de ce milieu tant par leur participation à la communauté Apache, que par leurs embauches précédentes MapR, MongoDB, Hortonworks ou encore Twitter…
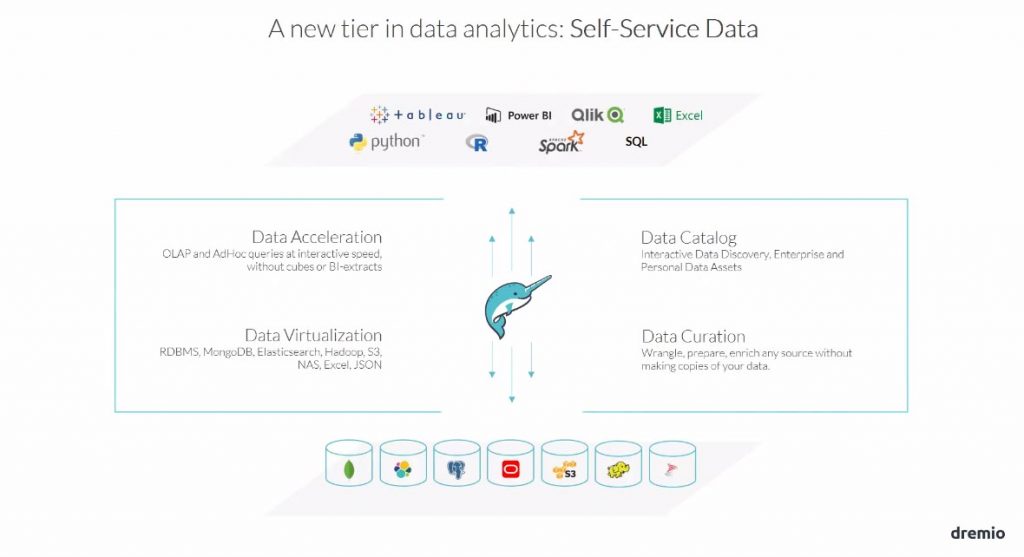
Et pour bien comprendre l’essence de cet outil, il faut voir Dremio comme un service d’accès à la donnée.
Les composants principaux
- Data Catalogue
Une connaissance fine de toutes les propriétés des sources de données. Il s’agit des métadonnées qui vont faciliter l’interrogation « assistée » de ces sources.
Il est possible désormais de documenter les espaces de travail et les jeux de données.
- Data Virtualisation
Concepts déjà connu du marché informatique, c’est la « Fédération de données». Toutes les données de l’organisation sont vues telles une seule et unique base de données.
- Data Accélération
Il s’agit d’une gestion de cache très optimisée avec Apache Parquet (sur disque) ou Apache Arrow (en mémoire). Ce cache est réalisé tant à l’exécution par Dremio lui-même, qu’au niveau du paramétrage pour optimiser des tables virtuelles.
- Data Curation
Qui participe à la préparation des données et la construction de table virtuelle.
Une technologie simple d’emploi
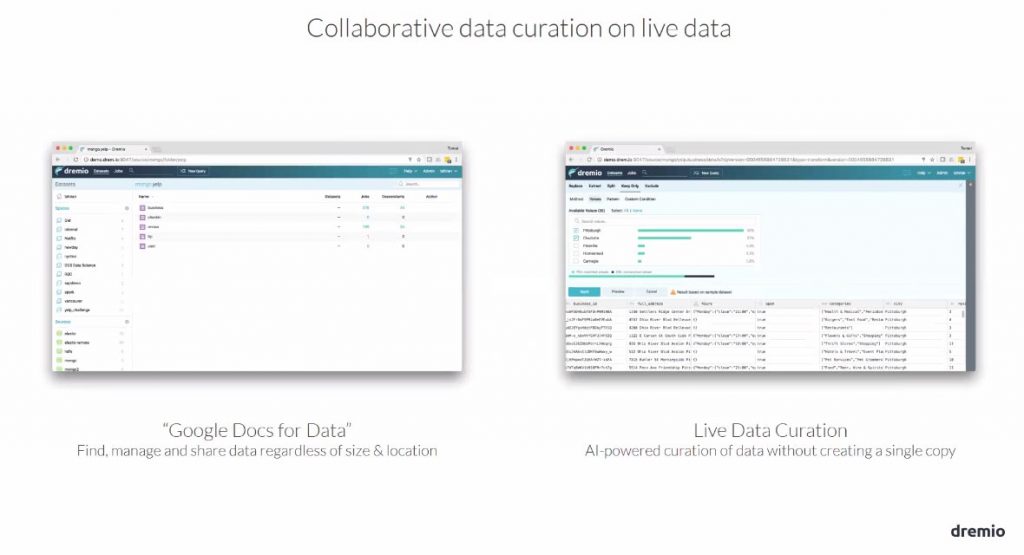
Le catalogue de métadonnées facilite la recherche de colonnes, de tables, de fichiers… quel que soit leur emplacement. Avec les fonctionnalités de « data préparation » l’utilisateur final construit tout seul les jeux de données qui lui sont nécessaires, et les partage pour une « ré-employabilité ».
Dremio apprend des utilisations des utilisateurs
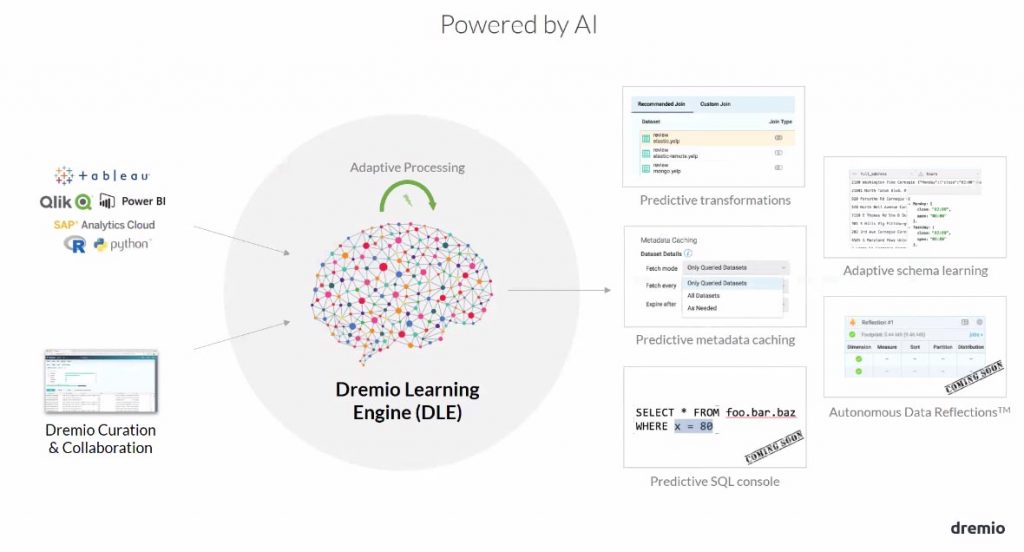
Si des utilisateurs ont pour habitude d’employer des associations de tables régulièrement, Dremio en ayant stocké ces activités est en mesure d’assister d’autres utilisateurs en leur proposant l’ajout de telles ou telles tables.
Une exécution distribuée du simple au robuste
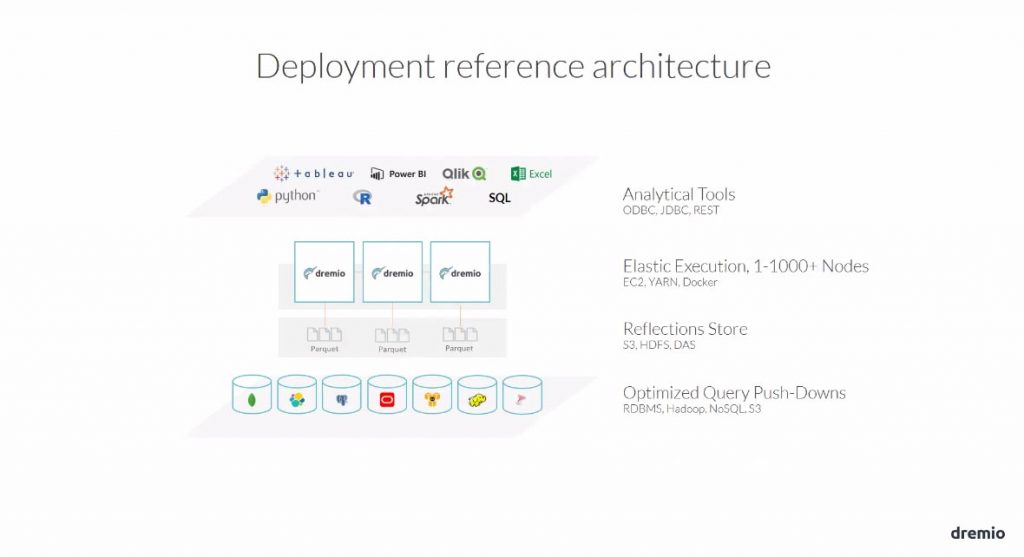
Dremio fonctionne tant au-dessus d’un orchestrateur de data center (YARN, Apache Mesos, Kubernetes, Swarm) qu’en « standalone ». Il sait aussi fonctionner sur une seule machine !
Par exemple un déploiement sous Kubernetes et en mode distribué peut simplement être lancé en une ligne de commandes.
helm upgrade 3.0 dremio --set executor.count=75
Son système de caching, nommé « Reflet » et peut être stocké dans HDFS, dans S3, ou encore dans un système de fichiers distribués.
Une intégration réussie à l’écosystème des organisations
Les utilisateurs ont donc un accès unique à la donnée grâce au pont JDBC, ODBC, api REST !
Grâce à son système de caching Dremio permettra aux utilisateurs d’accéder à la donnée même si le système source est inaccessible.

Il sait, de lui-même, optimiser les requêtes qui sont poussées vers les sources. En effet, les données en cache sont organisées (grâce au Reflet) pour accélérer les traitements, sans compter que Dremio va aussi savoir revoir le plan d’exécution pour là encore accélérer les traitements. Les administrateurs pourront, d’ailleurs, mieux paramétrer les sources et tables virtuelles pour agir sur l’accélération (il est aussi possible d’exploiter un moteur d’accélération externe). Par ailleurs, Dremio saura accélérer automatiquement des requêtes mettant en œuvre des jeux de données dont les jointures sont toute ou partie réalisées (« Starflake Reflections »).
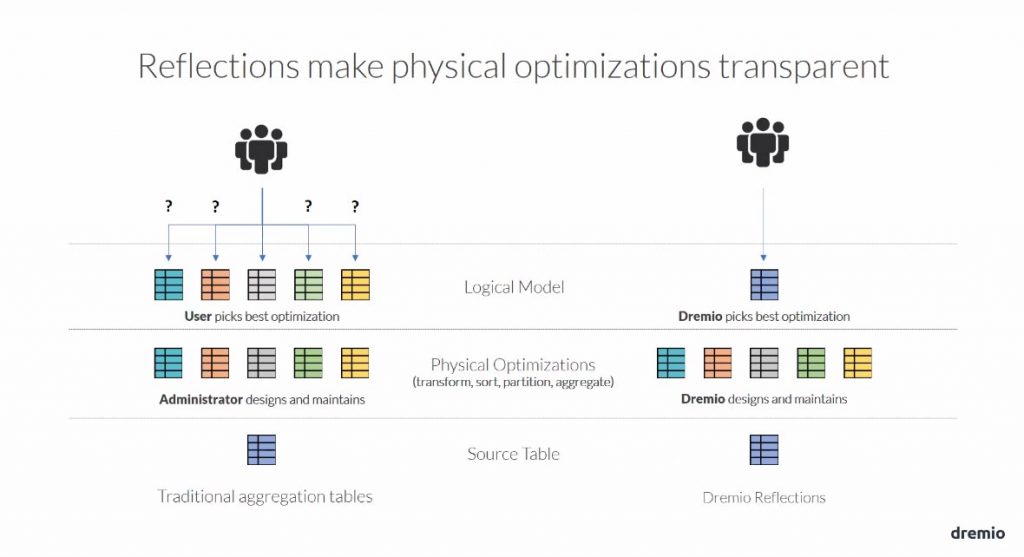
Par rapport à un système classique où l’on bâti des tables agrégées, et où l’utilisateur peut être perdu, ne sachant laquelle sélectionner, Dremio sait parfaitement sélectionner la bonne « réflexion » pour fournir dans les meilleurs délais la donnée aux utilisateurs finaux.
La mise à jour des « réflexions » se fait selon les SLA définis (rafraichissement toutes les 2 heures, par exemple), c’est-à-dire selon une fréquence de mise à jour. Dremio construit alors sa planification, qu’il exécute pour maintenir ses performances.
Dans le cadre d’un déploiement, si l’on a un cluster Hadoop, le mieux est de s’appuyer sur Yarn pour la gestion du rafraîchissement des accélérations et de leur stockage.
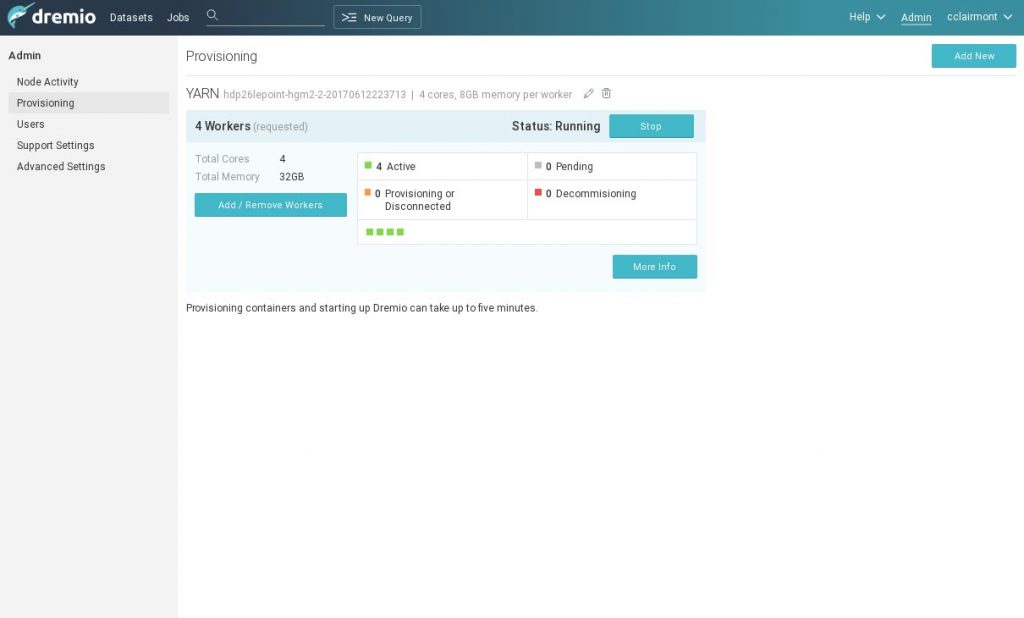
Démonstration
Création d’une source avec Elasticsearch
Partage et Collaboration des utilisateurs
Les espaces pour organiser la collaboration entre utilisateurs.
Dremio apporte de la collaboration entre utilisateurs : ils se partagent des espaces de travail pour s’octroyer des accès sur les tables virtuelles et donc sur les données.
La sécurité se gère par exemple comme sur Google Doc !
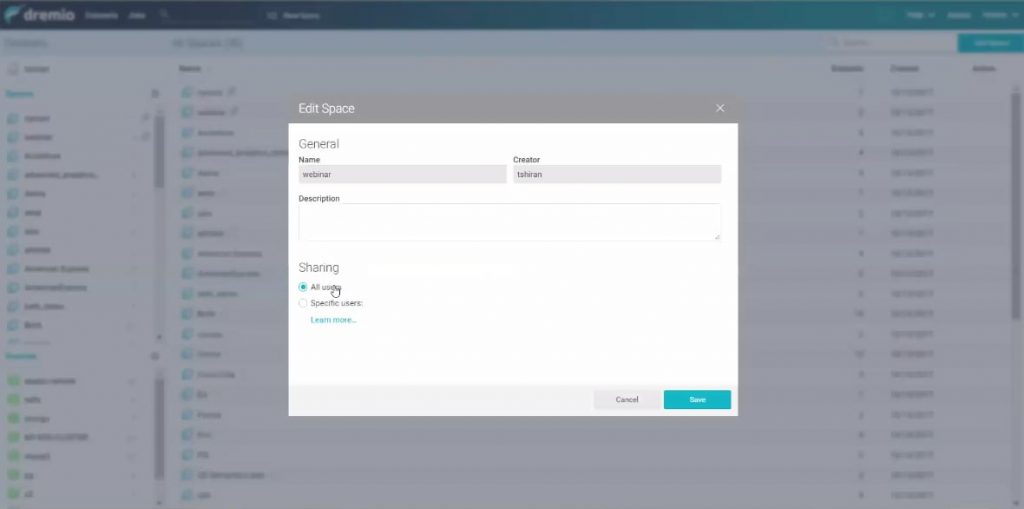
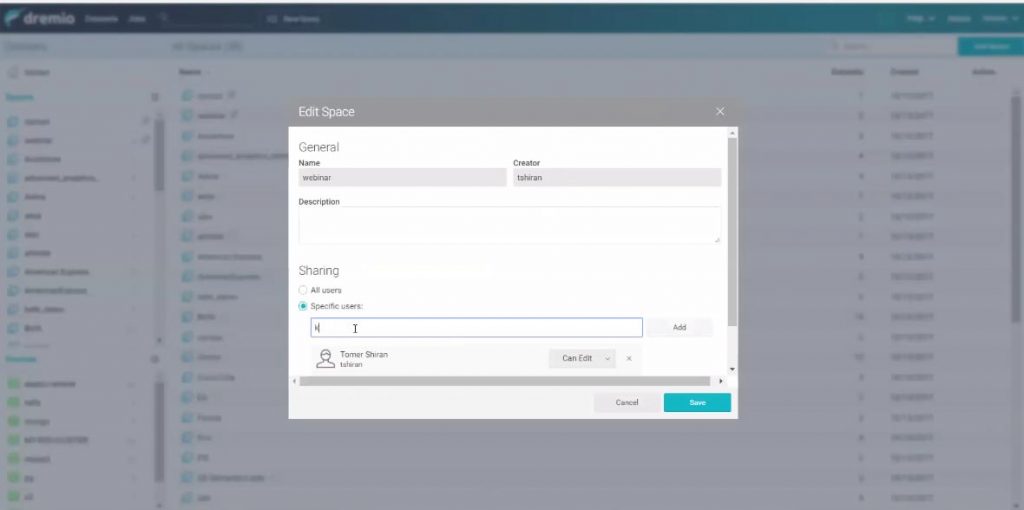
Les sources peuvent être gérées par les administrateurs et les développeurs. Les utilisateurs ont accès aux espaces.
Interrogations
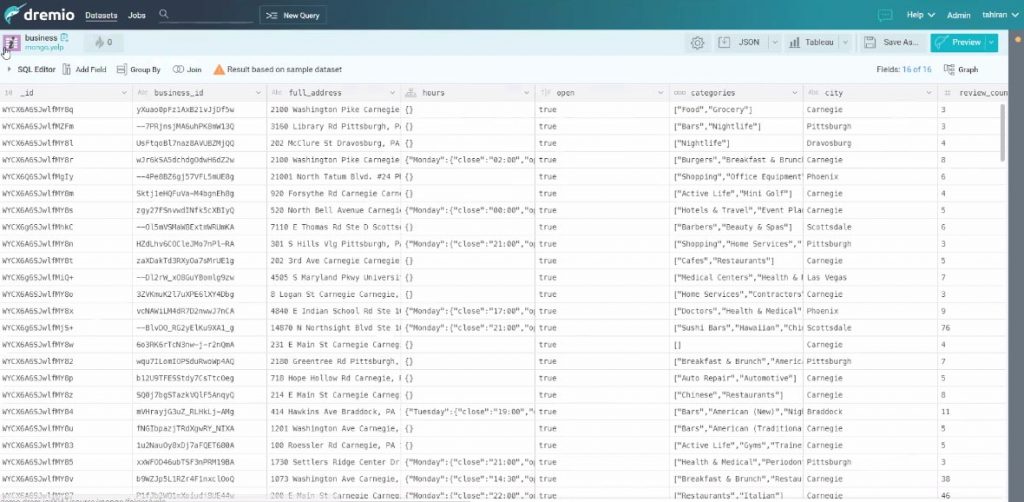
Les utilisateurs finaux peuvent alors naviguer entre les tables et observent les enregistrements tels qu’ils sont rangés dans leur système source. Ils peuvent alors construire, avec un assistant, des tables virtuelles (des vues alors mises en cache) ou tout simplement exploiter le langage SQL.
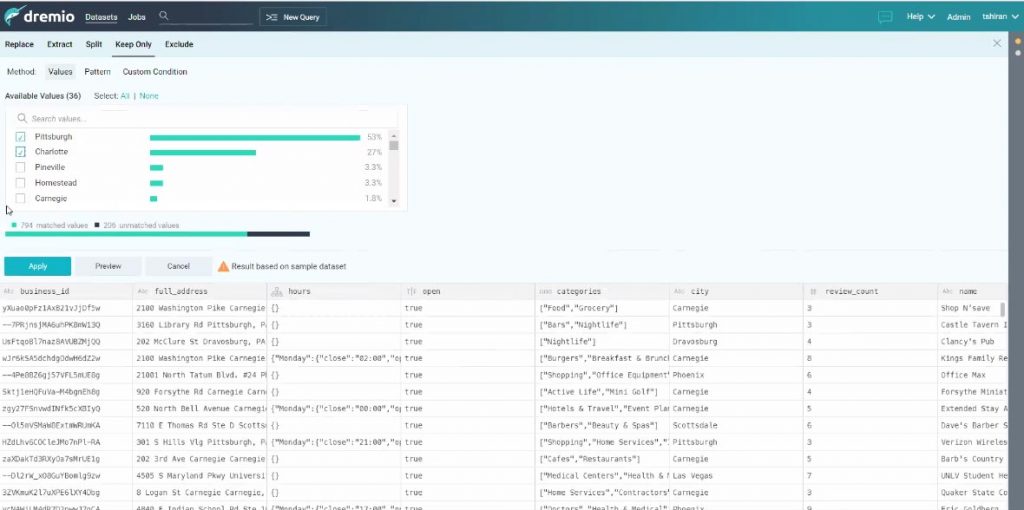
On peut sélectionner une colonne et en voir le contenu, créer un filtre…
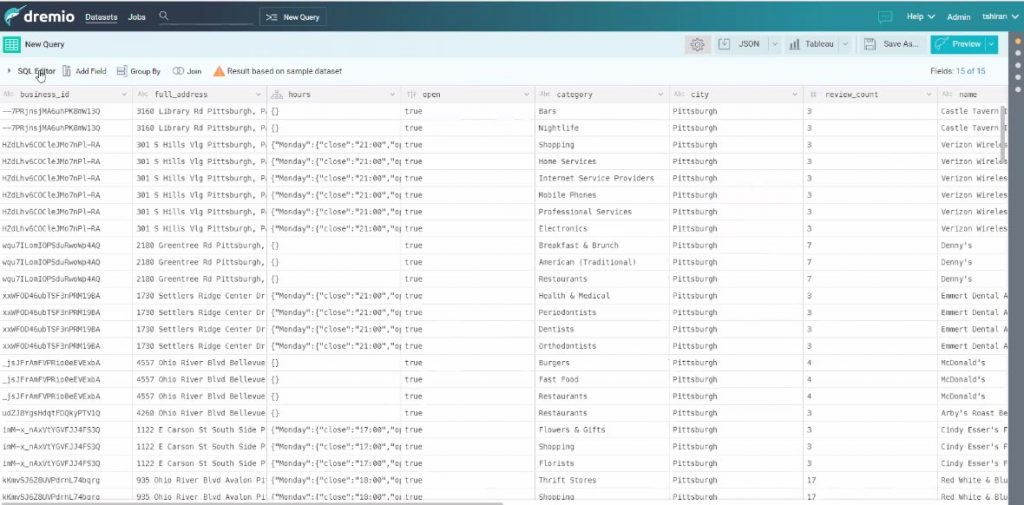
On peut cliquer sur une colonne et choisir « d’exploser » un tableau et renommer la colonne. Observez ici que l’on a plus qu’une colonne « catégorie », et non plus « categories » et que l’on a bien plus qu’une catégorie par ligne pour le même business_id (dans l’écran précédent).
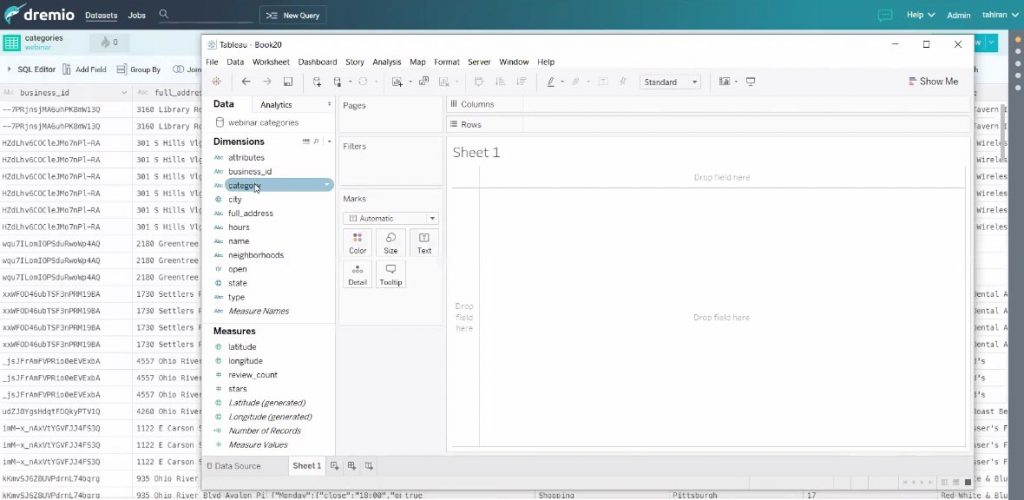
Et voilà on retrouve notre nouvelle colonne dans tableau ! Et pouvons enfin bénéficier des accélérations dans Tableau.
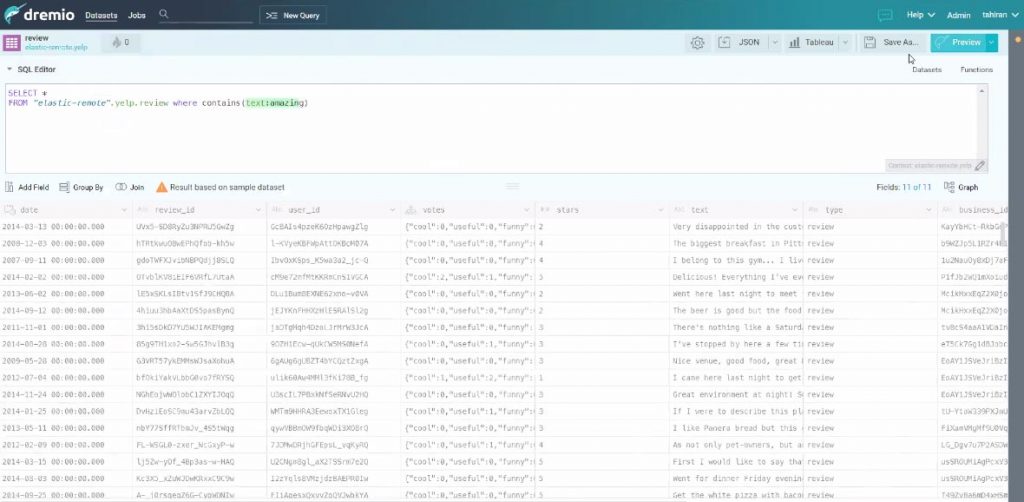
Lors de la construction des requêtes il va être possible d’exploiter les index de « Lucene » pour faciliter l’accès aux métadonnées.
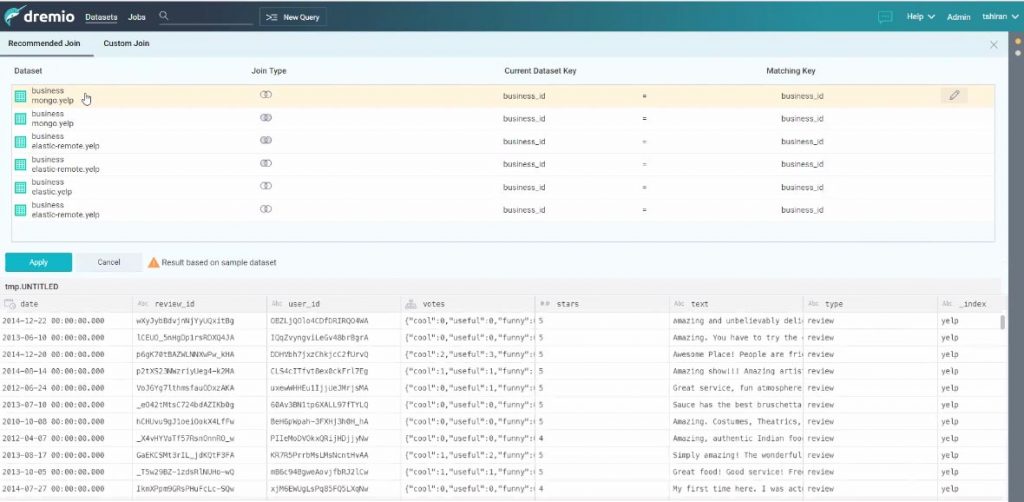
Dremio propose de joindre alors la table déjà en jeu avec une autre de MongoDB parce que d’autres utilisateurs ont déjà réalisé une telle jointure.
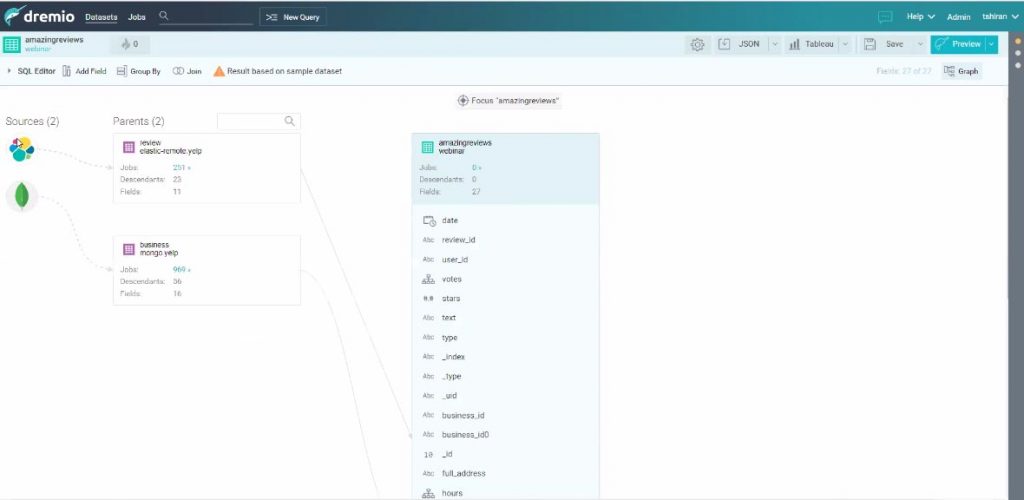
Dremio prend du sens grâce à une présentation orientée graphe de la requête où l’on comprend clairement les relations entre toutes les sources.
Audit
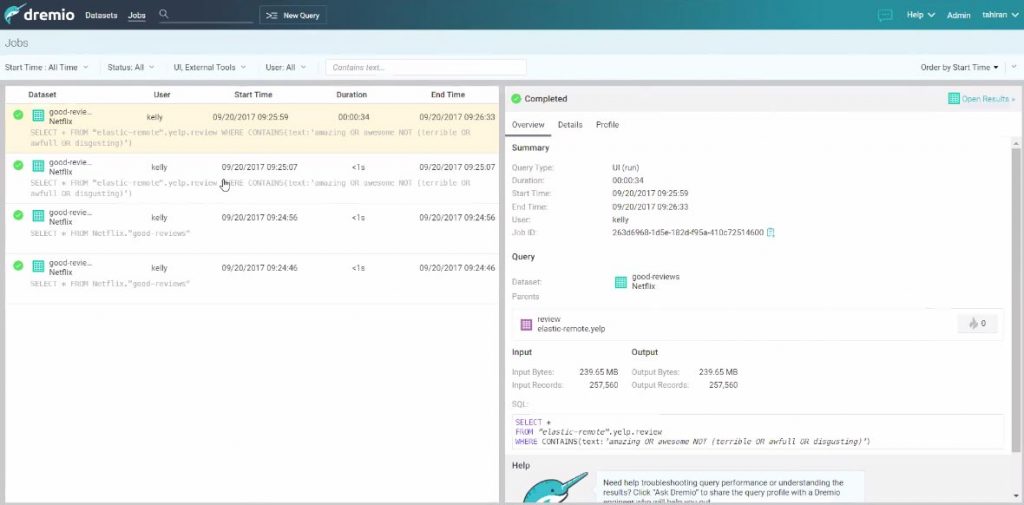
La chose la plus appréciable au-delà des accélérations et de l’accès unique, réside dans cette possibilité à suivre l’entièreté de l’activité de chaque utilisateur, qui interroge chaque source de données. Et bien sûr de voir les temps de réponse des systèmes sources ! Finalement, Dremio devient ici à lui seul une sorte de tableau de bord pour suivre « qui fait quoi » sur l’ensemble des sources de données.
Tableau, and co !
Et bien entendu c’est vrai pour une requête exécutée en directe depuis Tableau.
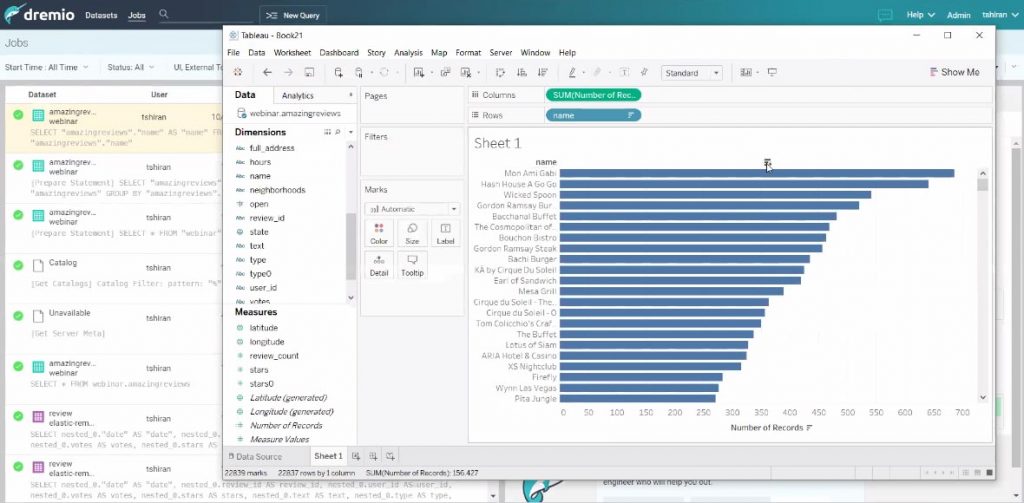
Grâce à Dremio on peut travailler en direct sur un jeu de données d’un milliard de lignes.
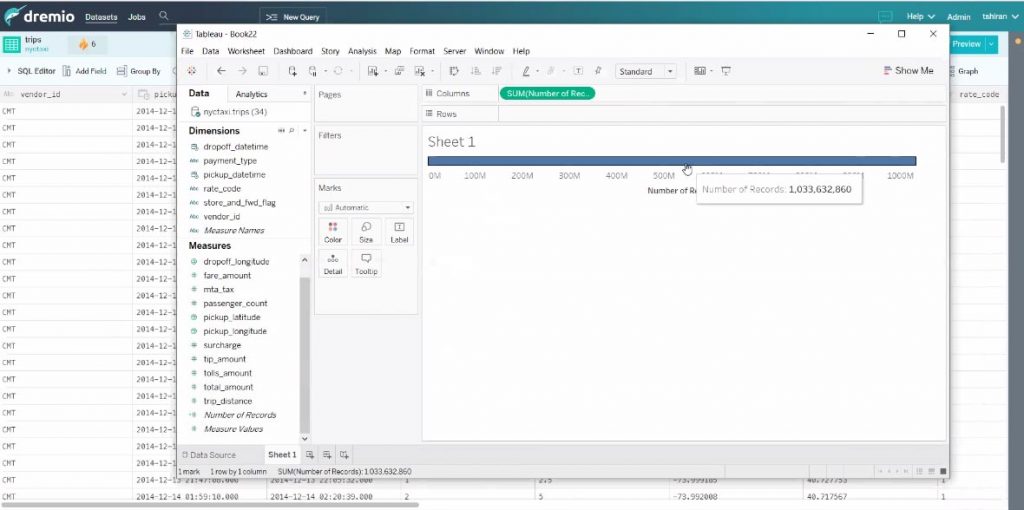
Et l’on peut naviguer avec tous les axes.
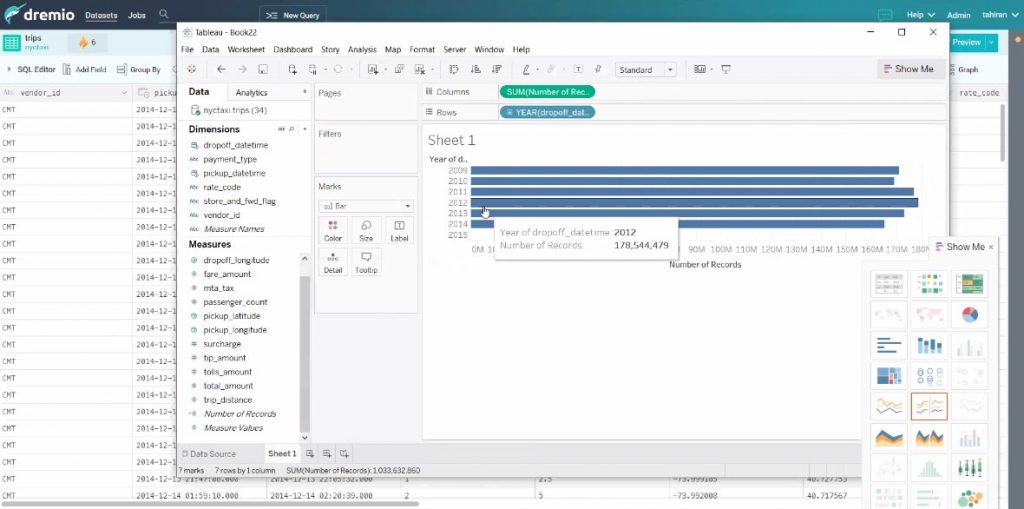
Et la preuve dans Dremio :
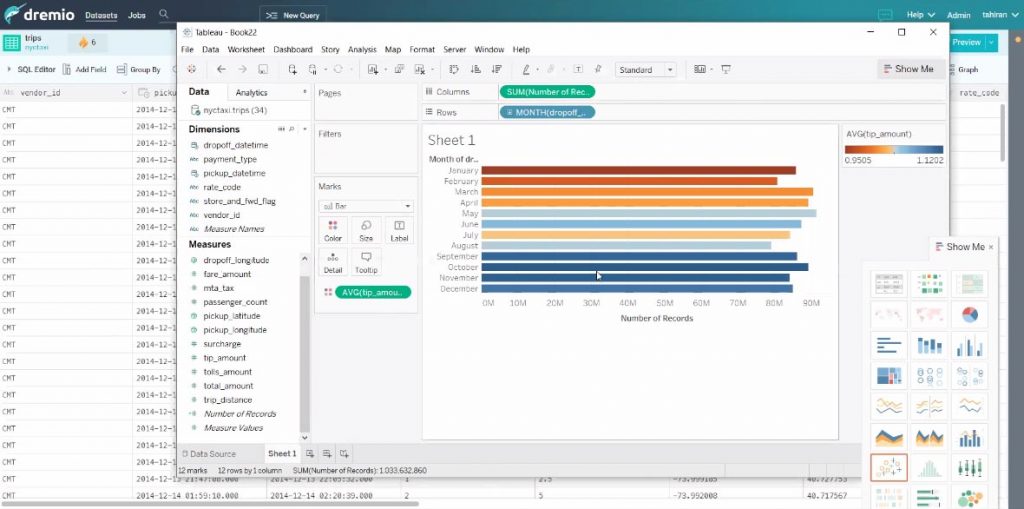
Les résultats sont retournés en moins d’une seconde.
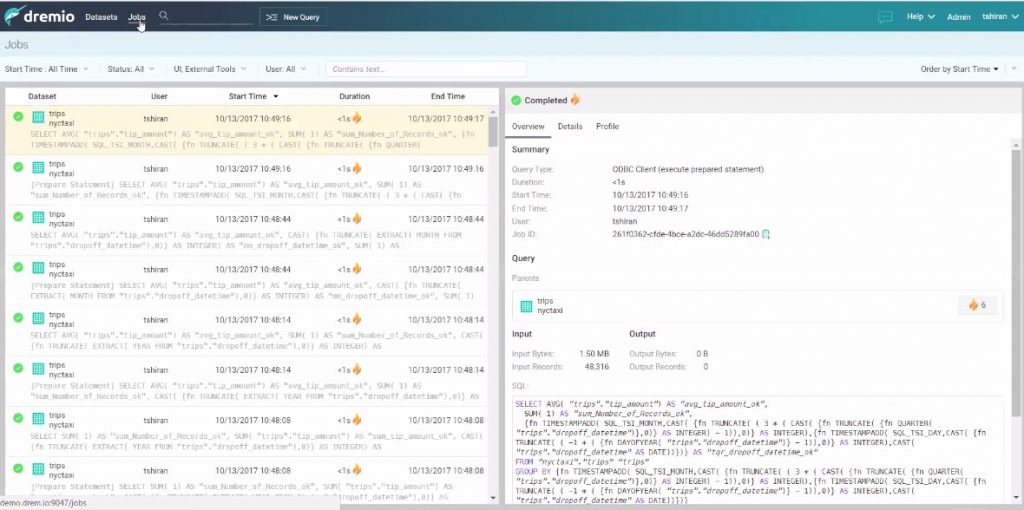
Source de données
Dremio travaille déjà avec ces sources-là :

Dremio ne s’appuie pas sur Hive engine, il exploite seulement ses metadonnées.
Cas clients
Dremio, dans le monde de La Presse
Nous avons mené un projet avec un client dans le monde de la presse, qui est emballé par la solution ! Le client a bien compris son intérêt : « Nous ne sommes pas obligés de tout ramener dans Hadoop ! Toutes nos données déjà structurées et qui sont dans notre infrastructure, nous y accéderons via Dremio. La donnée partenaire, ou celles issues des solutions SAAS, sera transférée dans Hadoop. En plus Dremio nous offre la possibilité de les voir de manière uniforme, telle une seule base de données ».
Cas OVH
OVH a vite adopté Dremio pour avoir une vision unique du système d’information. L’hébergeur a développé un pont pour collecter des données depuis différentes base de données. Ces données sont alors rapatriées vers un cluster Hadoop et Dremio vient les présenter au métier.
OVH est tellement ravi de la solution qu’il pense même à en fournir une version en tant que service managé.
Comme dit en introduction, dès sa sortie, la #SynalTeam a adopté Dremio c’est d’ailleurs pourquoi nous avons décidé d’y consacrer une présentation lors de Paris Open Source Summit 2018 ! Ne manquez pas notre atelier le 5 décembre à 15h40 (on pourrait avoir des petites surprises à distribuer…!).
Vous pouvez aussi essayer Dremio en téléchargeant la version communautaire.
Essayer Dremio
[…] A l’époque, Julien nous parle de son projet, alors en développement, qu’il mène avec Jacques Nadeau : Dremio. Lire la suite » […]
[…] https://www.synaltic.fr/blog/dremio-federation-de-donnees-self-service […]
I think this is a very useful thing =) given the development of technology and business in general, such innovations are simply necessary.
Cela semble être une excellente application. Ceci est très important pour suivre le développement technologique. Merci)